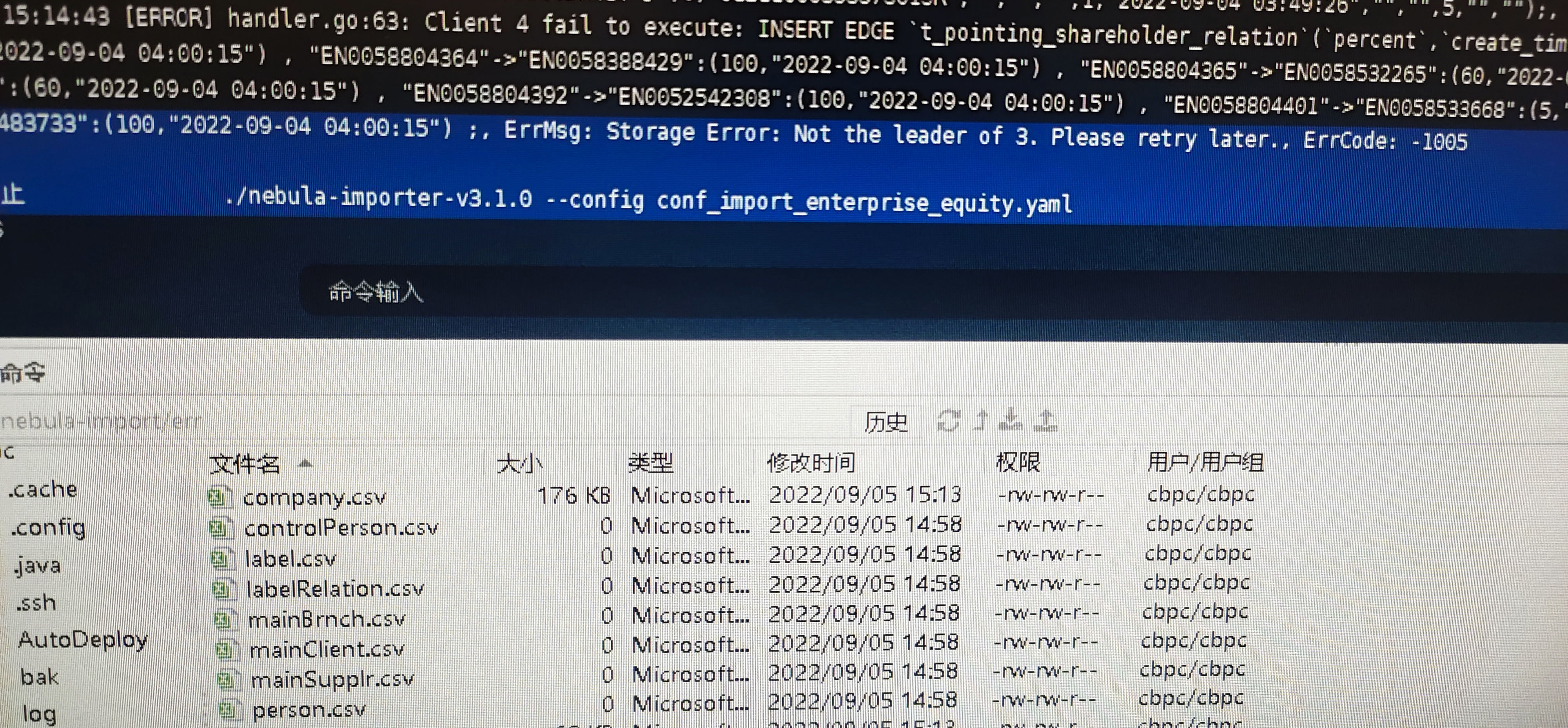
1.通过import工具把csv数据导入到星云图数据库中发现报错了,100-300M大小的csv文件。
2.也无法通过console创建连接
3.然后重新启动集群,也无法完全启动
我们安装的是3.1.0版本
烦请各位老师帮忙看下,感谢感谢
1.通过import工具把csv数据导入到星云图数据库中发现报错了,100-300M大小的csv文件。
2.也无法通过console创建连接
3.然后重新启动集群,也无法完全启动
我们安装的是3.1.0版本
烦请各位老师帮忙看下,感谢感谢
发帖的时候有固定模板做参考,麻烦根据模板提供下相关信息,这样可以提高和研发同学们的沟通效率 
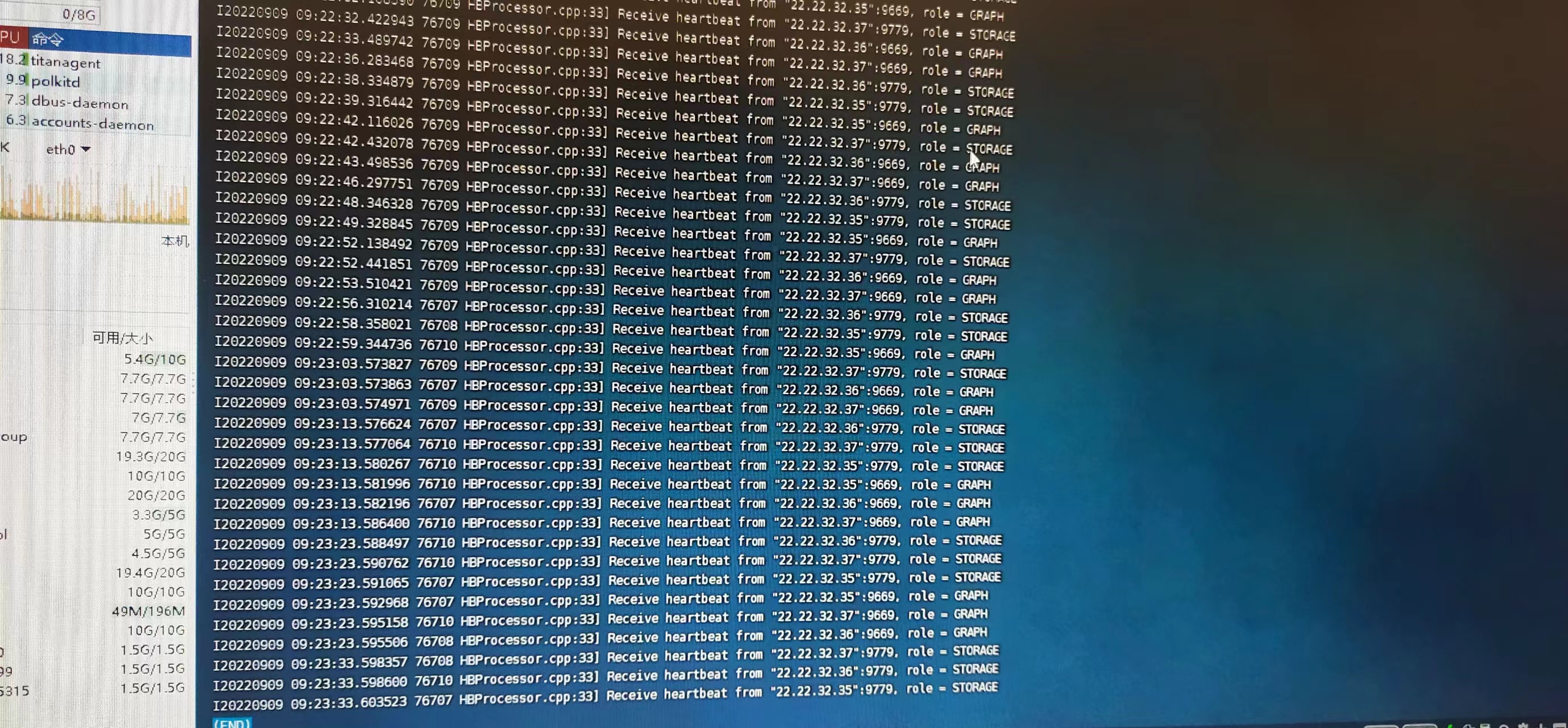
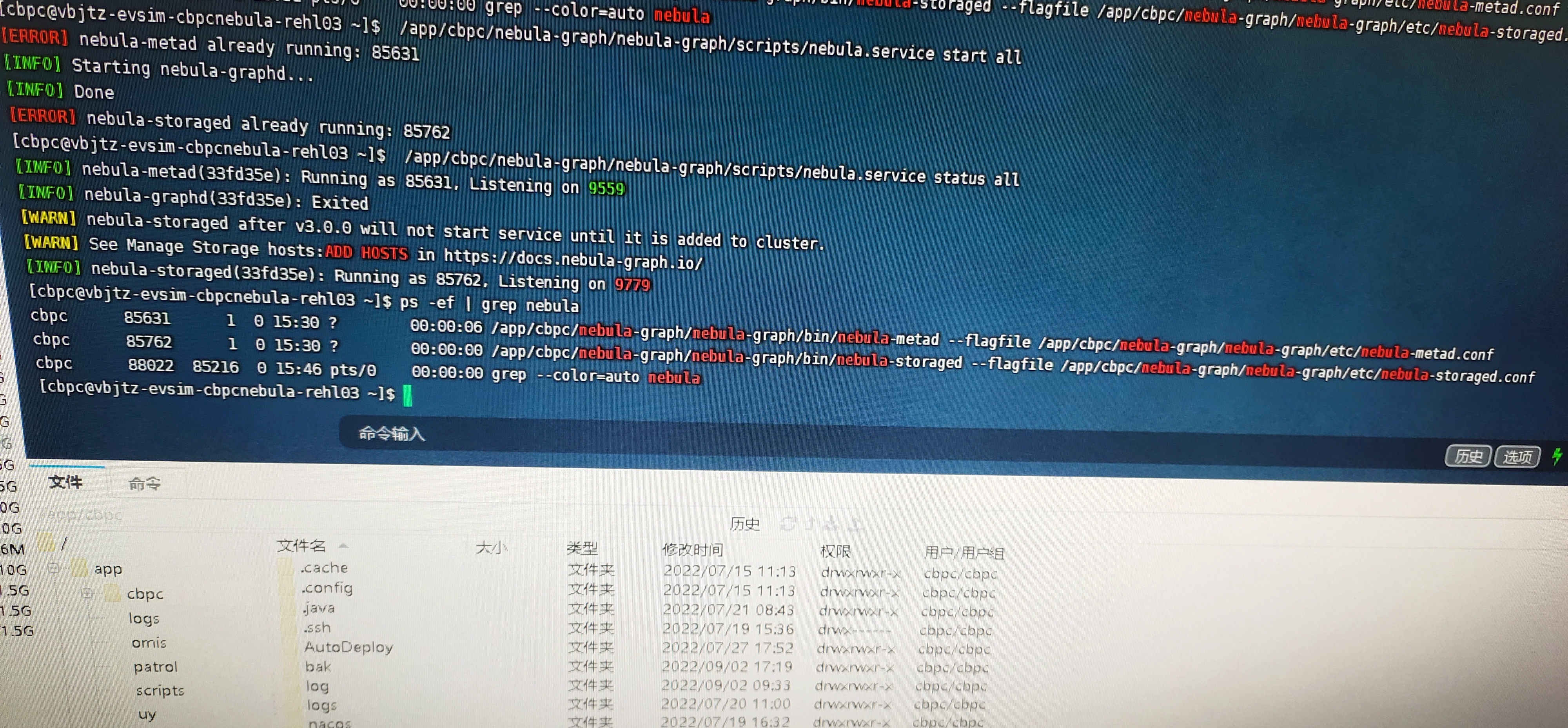
看步骤 3 好像你的服务并没有完全关掉又重新启动了。另外想问一下你这个是否是在使用importer导入数据以后服务才出现的异常?从你的status all看起来你的graphd 服务并没有启动起来,这也是为什么无论是console还是importer都无法连接的原因。
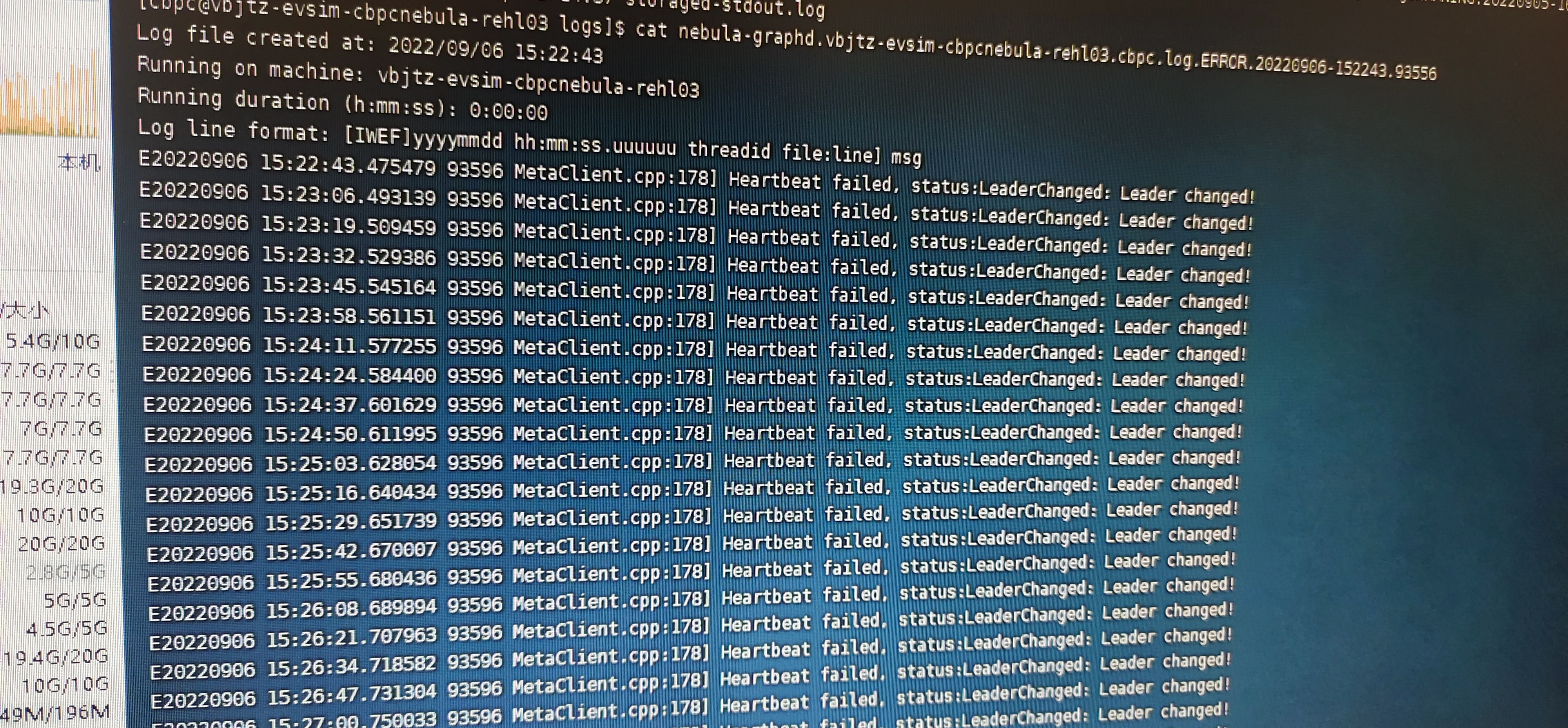
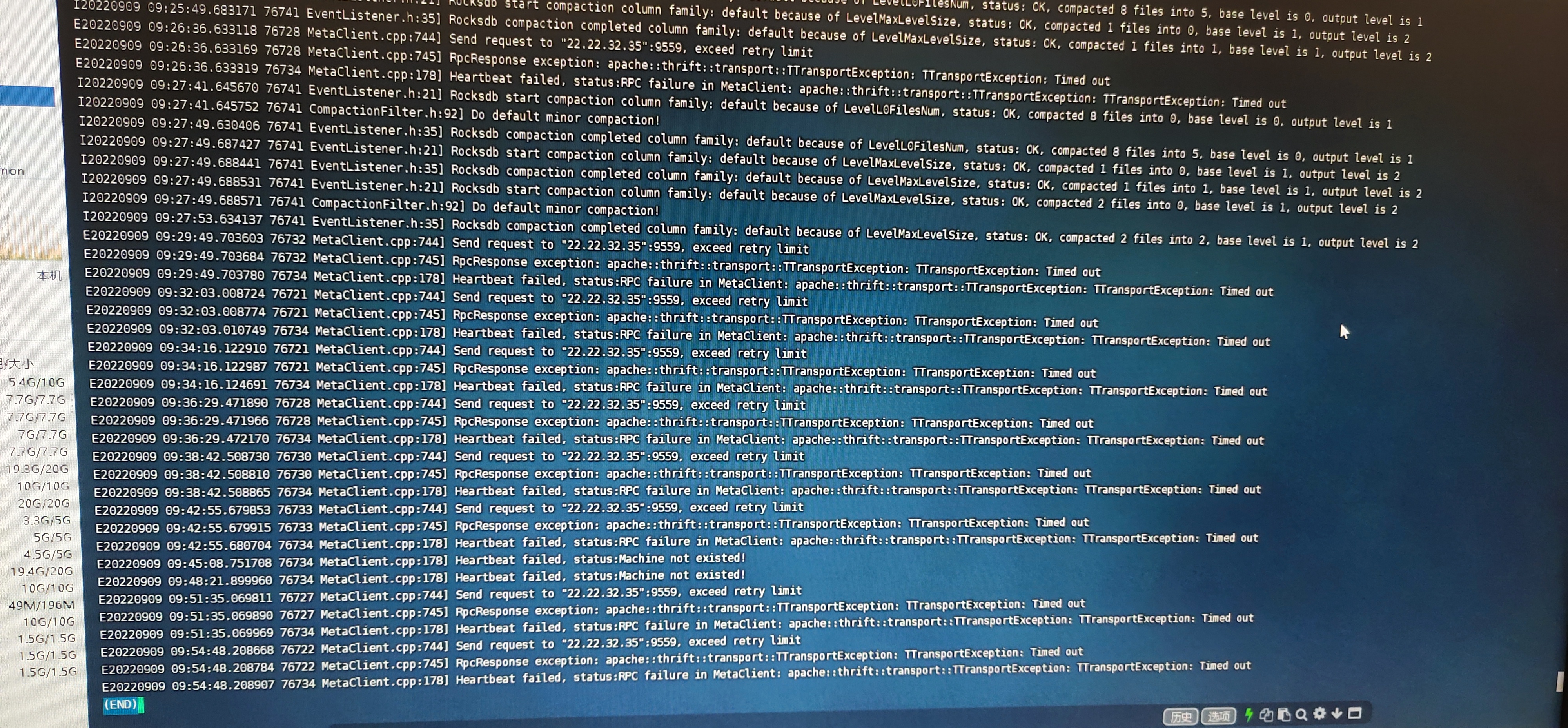
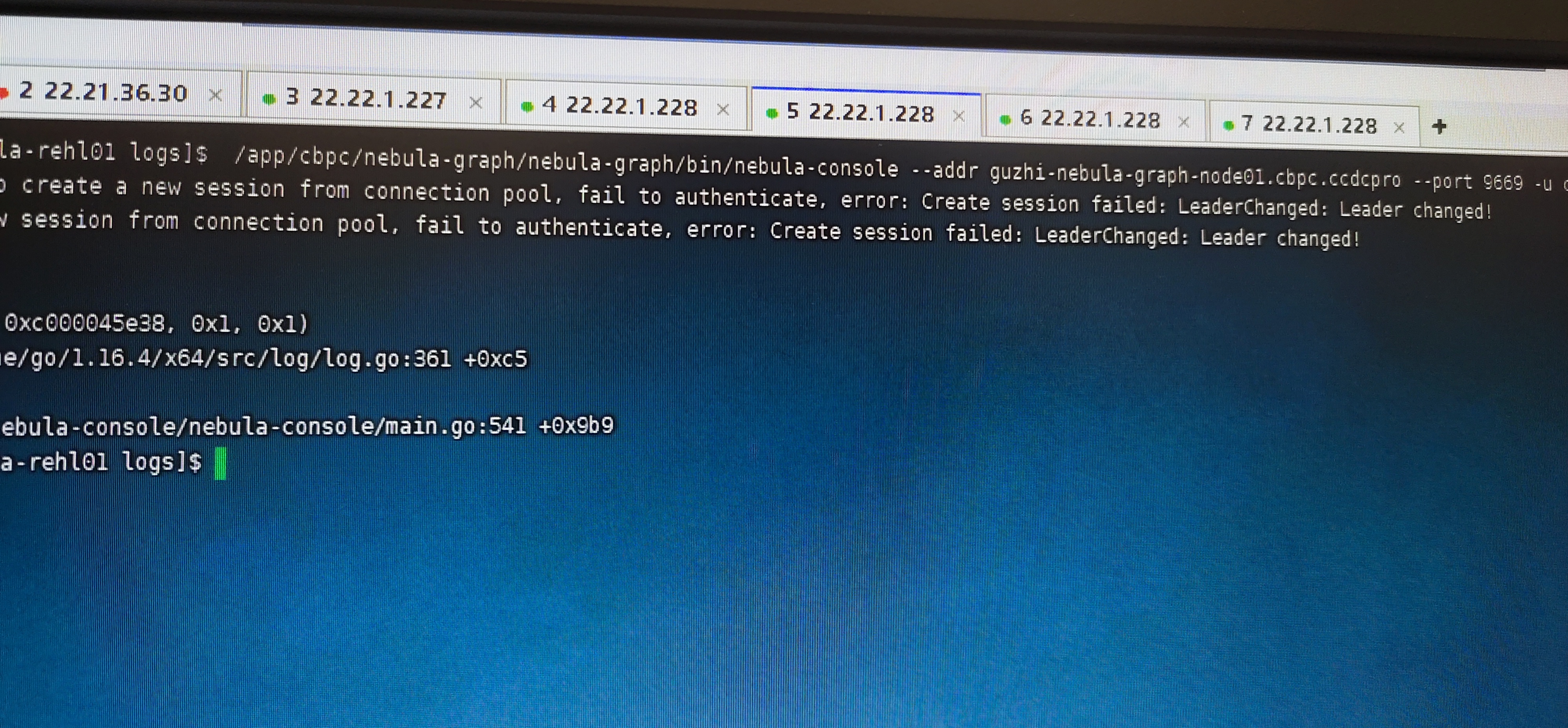
是的,是通过import导入才出现的这个问题。刚开始导入csv文件还正常,然后会出现Storage Error:Not the leader。时好时坏,然后我就终止了流程。
再次创建console连接时,就报错了error:Create session failed:LeaderChanged:Leader changed!
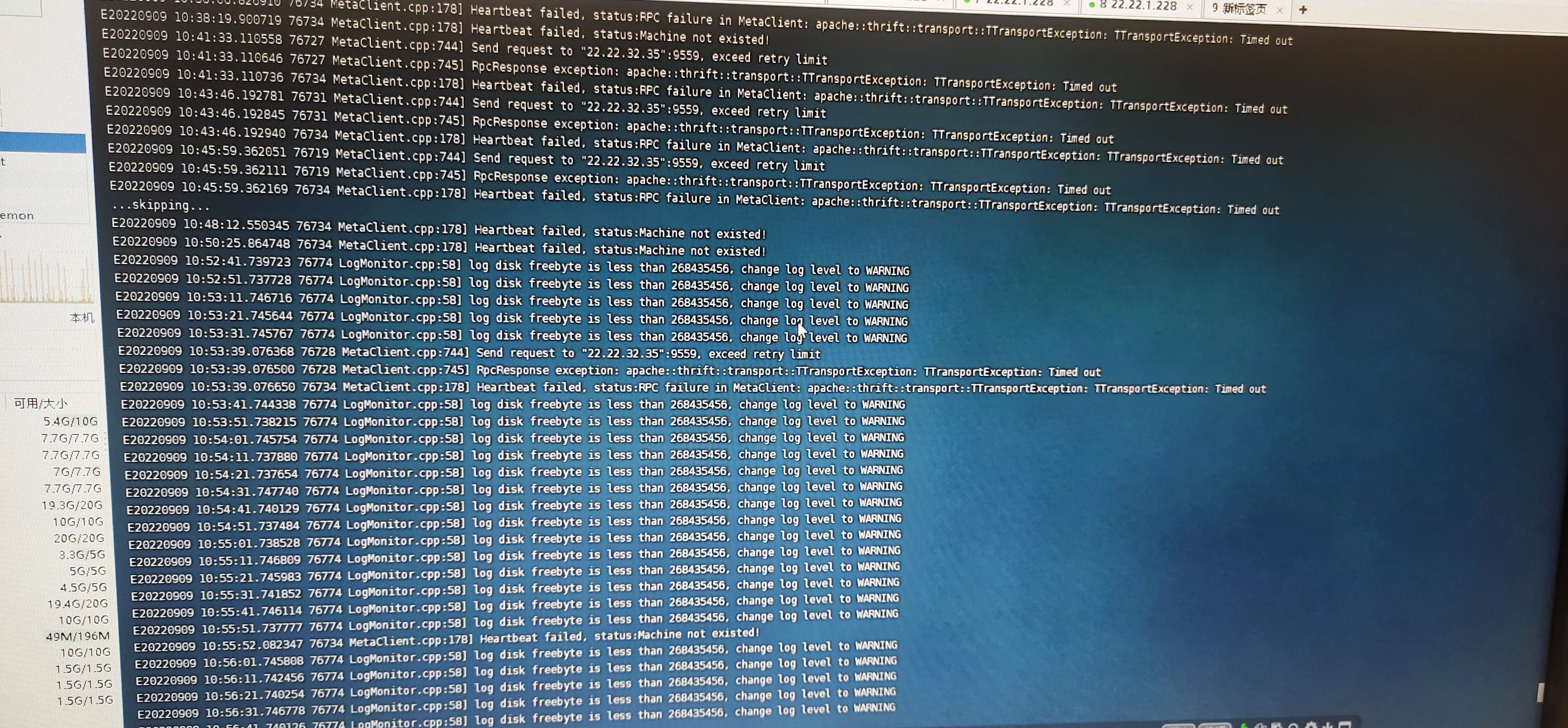
然后就关闭集群服务,再重新启动时graph 怎么都起不来
nebula 版本:3.1.0
部署方式:分布式
安装方式:TAR文件
是否为线上版本:N
硬件信息
磁盘 200G
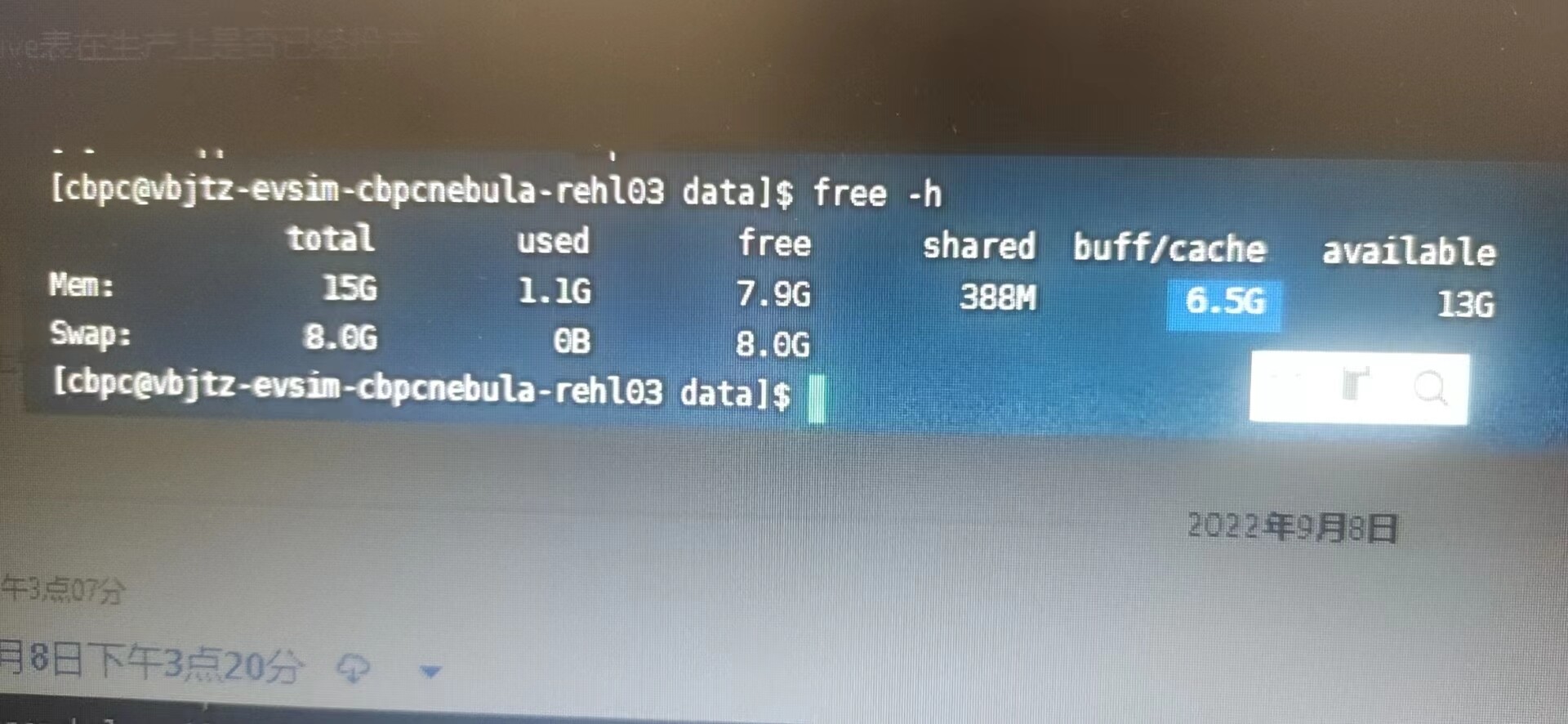
CPU、内存 4核 15G
可以给一个可复现的方式么?包括你创建的图模型和导入的数据,我们需要在这边复现一下定位原因。
另外多问几个问题:
复现:就是csv文件导入过程,时不时的出现这个异常:Storage Error:Not the leader。
结束进程后。
创建console连接时,无法创建成功,异常:error:Create session failed:LeaderChanged:Leader changed!
需要删除data文件夹里的storage存储数据,才可以成功创建console连接
1.磁盘:HDD
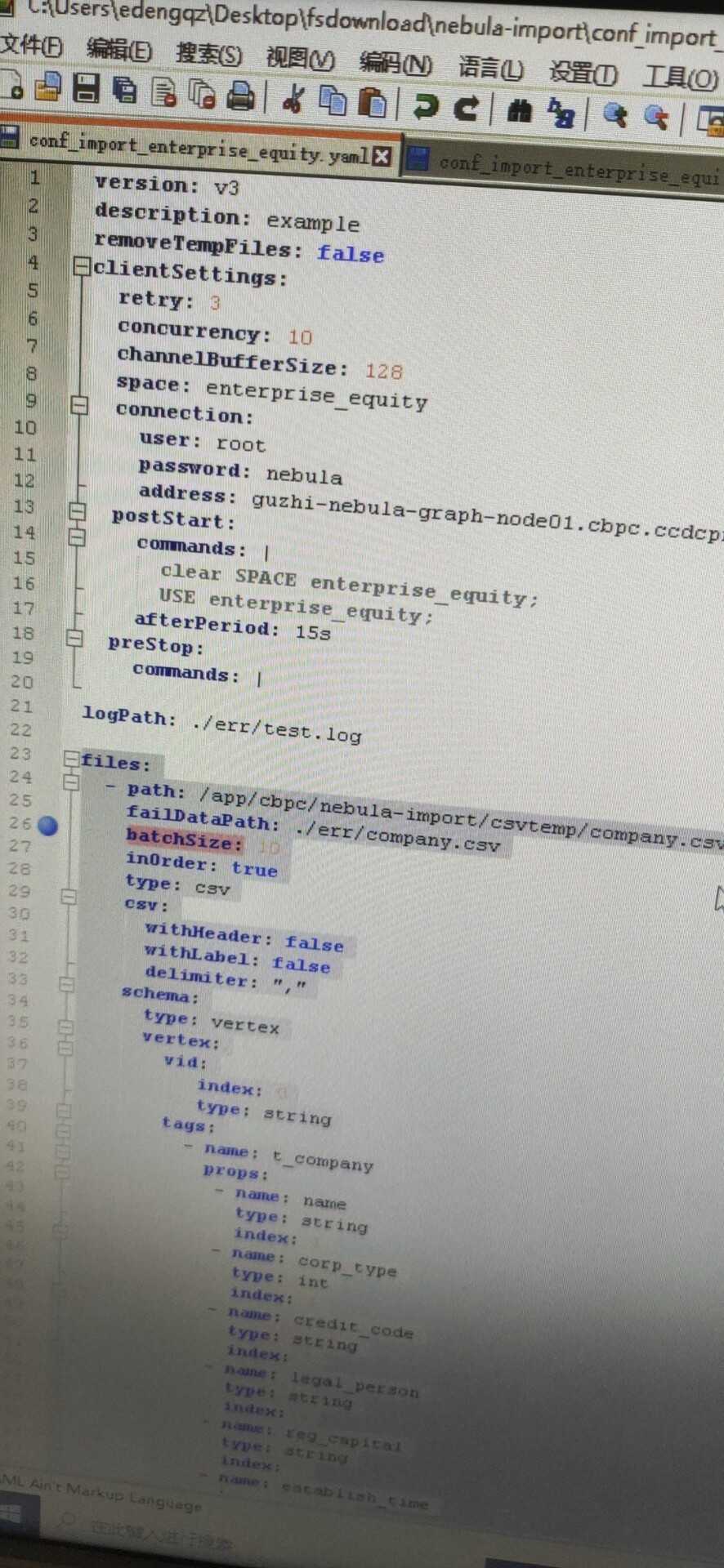
2.有两个图空间,不是同时入库的,两个yaml文件是有先后顺序。现在是执行第一个yaml文件出的问题
3.三台机器,分别部署了这三个服务meta,graph,storage
备注:在磁盘HDD 16核 内存16G 部署的 就一切正常。想问下和这个有关系吗
我这边yaml配置配置信息:
里面有10个schema。3个点 7个边。我今天调试 保留3个点3个边共计6个schema。发现可以正常导入。
我的疑惑:1.目前的这个yaml配置信息,针对10个schema。这个配置信息哪里还可以优化下。
2.针对4核15G内存 和 16核16G内存 的资源配置 对图数据库而言 有什么不同呢? 谢谢
concurrency: 10
channelBufferSize: 128
batchSize: 10
这些有什么可以调整的地方吗
配置比较低的情况下建议把concurrency改小一点,先改到5试试
目前判断不出来,但应该不是schema数量的问题,我怀疑你的数据里是否存在脏数据,比如你的某个schema定义的vid string的长度是有限制的,但实际导数据时,存在id过长,导致storage挂掉了。这个你可以排除下?
可以再往上翻一下storage error的错误,因为这里的错误看起来是storage leader已经挂了的情况,可以翻一下前面是否还有错误
这个可以排除,因为同样的数据 在换了高配置环境后就可以正常导入
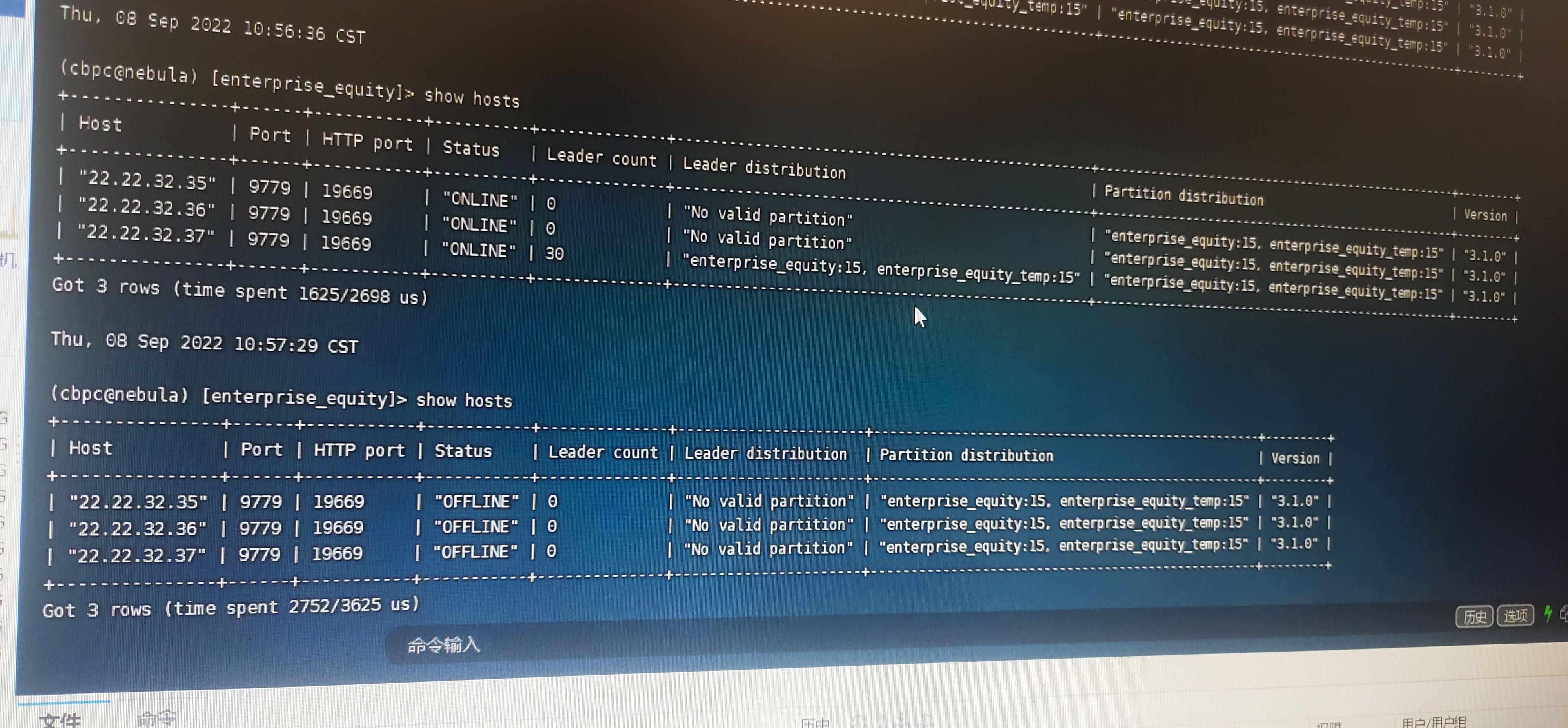
storage 的端口还在,就是 集群种的状态offline。
这个问题,还会影响到集群重启,只有把data/storage 里面的文件数据全部删除 才能重启成功 
不重启集群 无法创建客户端和nebula-console连接
方便把storaged和metad(leader)的INFO贴一下吗?
建议把账号进程操作数调大些