Can not define any other configs when kafka exists
[root@hadoop nebula-exchange]# spark-submit \
> --name "kafkaToNebula" \
> --master "local" \
> --class com.vesoft.nebula.exchange.Exchange \
> /opt/nebula-exchange/nebula-exchange_spark_2.4/target/nebula-exchange_spark_2.4-3.0.0.jar \
> -c /opt/nebula-exchange/kafka_application.conf
22/09/14 11:02:10 INFO config.Configs$: DataBase Config com.vesoft.exchange.common.config.DataBaseConfigEntry@2833c390
22/09/14 11:02:10 INFO config.Configs$: User Config com.vesoft.exchange.common.config.UserConfigEntry@7f08e74
22/09/14 11:02:10 INFO config.Configs$: Connection Config Some(Config(SimpleConfigObject({"retry":3,"timeout":3000})))
22/09/14 11:02:10 INFO config.Configs$: Execution Config com.vesoft.exchange.common.config.ExecutionConfigEntry@c757796a
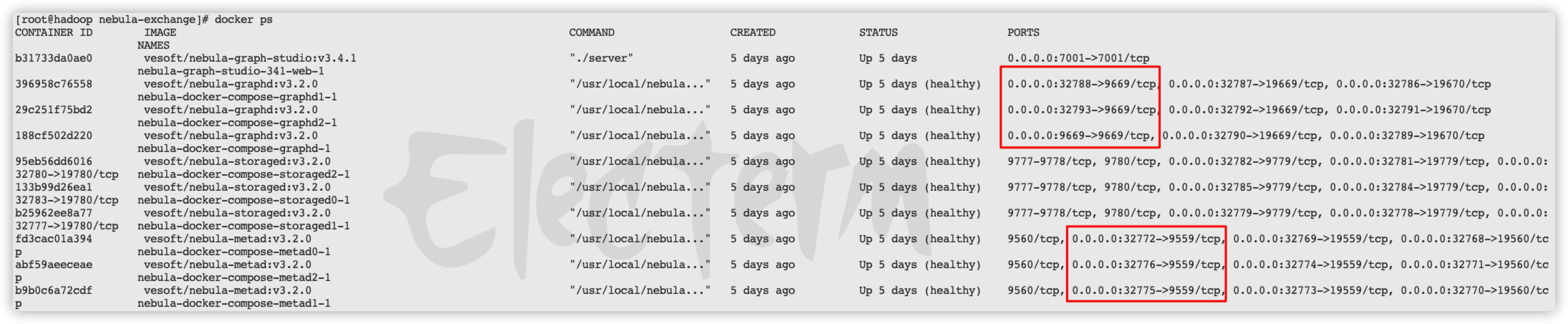
22/09/14 11:02:10 INFO config.Configs$: Source Config Kafka source server: 10.30.6.71:9092 topic:topic_name1 startingOffsets:latest maxOffsetsPerTrigger:None
22/09/14 11:02:10 INFO config.Configs$: Sink Config Kafka source server: 10.30.6.71:9092 topic:topic_name1 startingOffsets:latest maxOffsetsPerTrigger:None
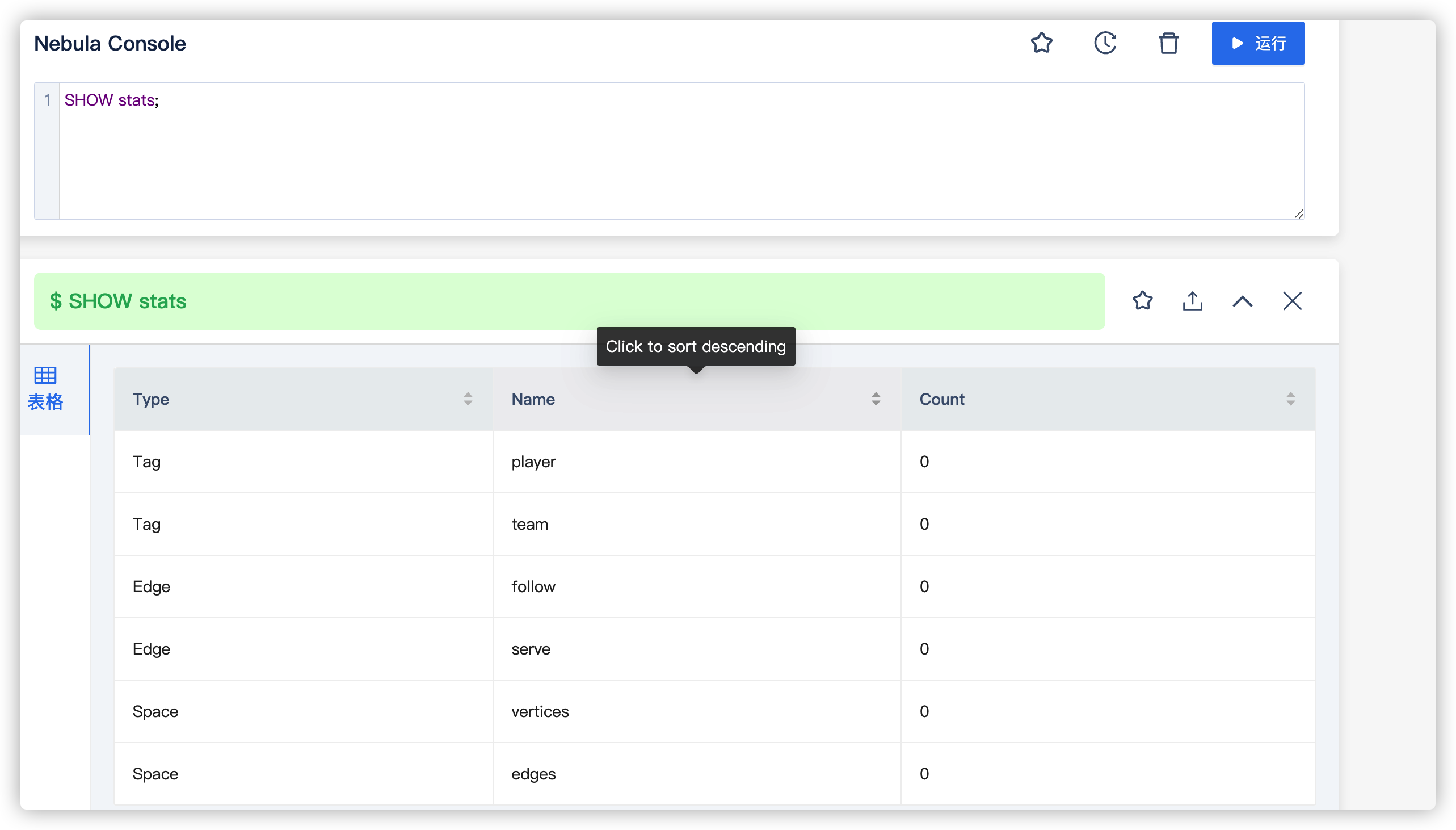
22/09/14 11:02:10 INFO config.Configs$: name player batch 10
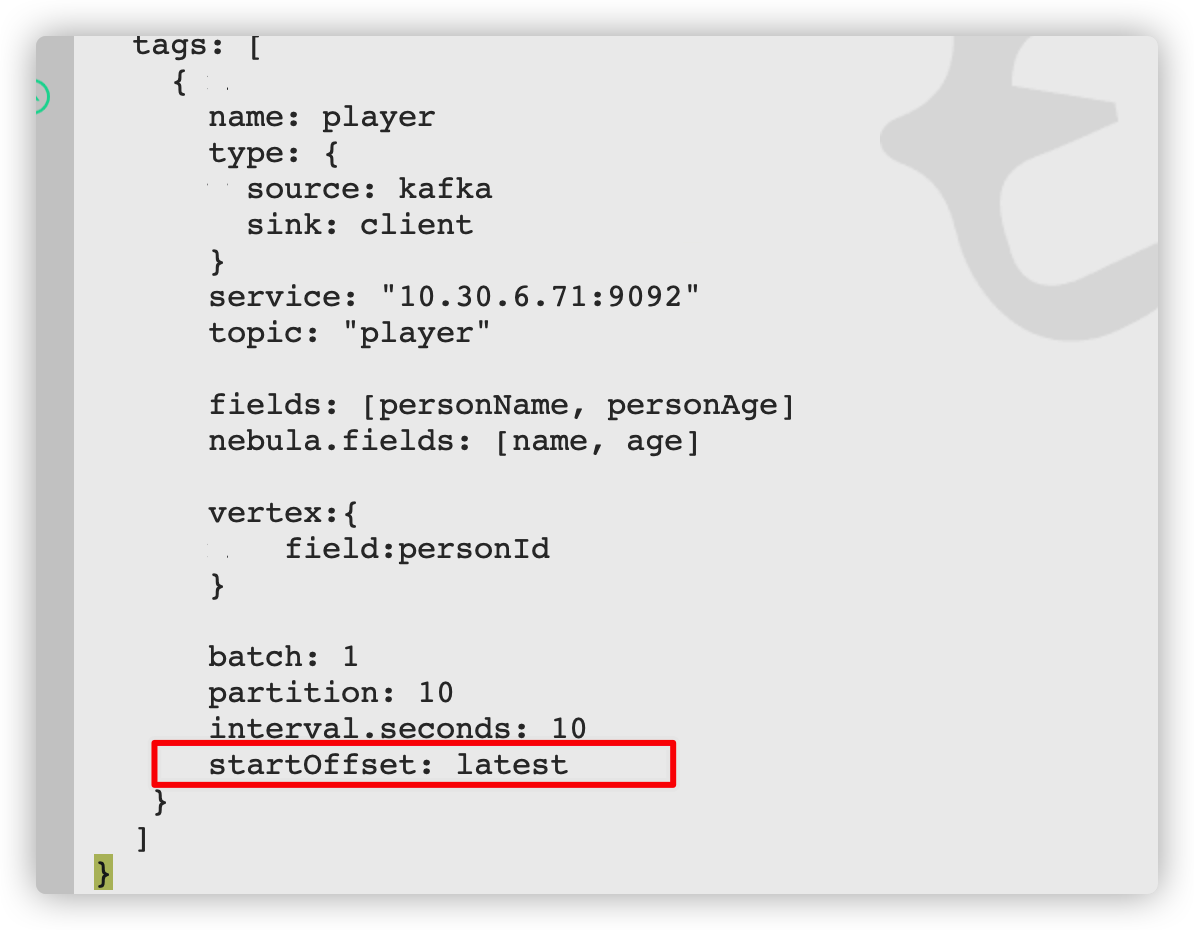
22/09/14 11:02:10 INFO config.Configs$: Tag Config: Tag name: player, source: Kafka source server: 10.30.6.71:9092 topic:topic_name1 startingOffsets:latest maxOffsetsPerTrigger:None, sink: Nebula sink addresses: [10.30.6.71:32788], vertex field: personId, vertex policy: None, batch: 10, partition: 10.
Exception in thread "main" java.lang.IllegalArgumentException: Can not define any other configs when kafka exists
at com.vesoft.exchange.common.config.Configs$$anonfun$parse$1.apply(Configs.scala:349)
at com.vesoft.exchange.common.config.Configs$$anonfun$parse$1.apply(Configs.scala:347)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at com.vesoft.exchange.common.config.Configs$.parse(Configs.scala:347)
at com.vesoft.nebula.exchange.Exchange$.main(Exchange.scala:38)
at com.vesoft.nebula.exchange.Exchange.main(Exchange.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:851)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:926)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:935)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
22/09/14 11:02:11 INFO util.ShutdownHookManager: Shutdown hook called
22/09/14 11:02:11 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-3f711747-116f-448b-a5f8-6eb9da652a72