wuyou
1
配置:
目前三个节点, 版本3.2.0 ,内存分配策略是不超过当前服务器80% ,当前服务器256的内存,内存比较充足。
场景:
通过消费kafka,不断的往nebula写数据(会伴随有查询)
问题:
-
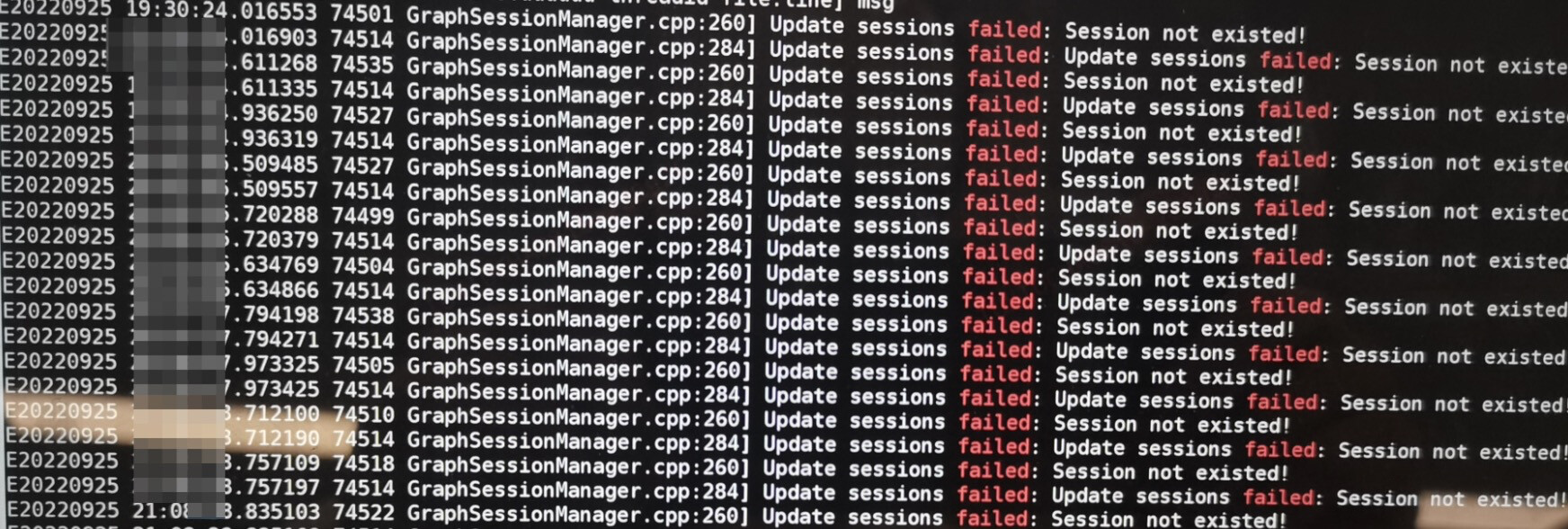
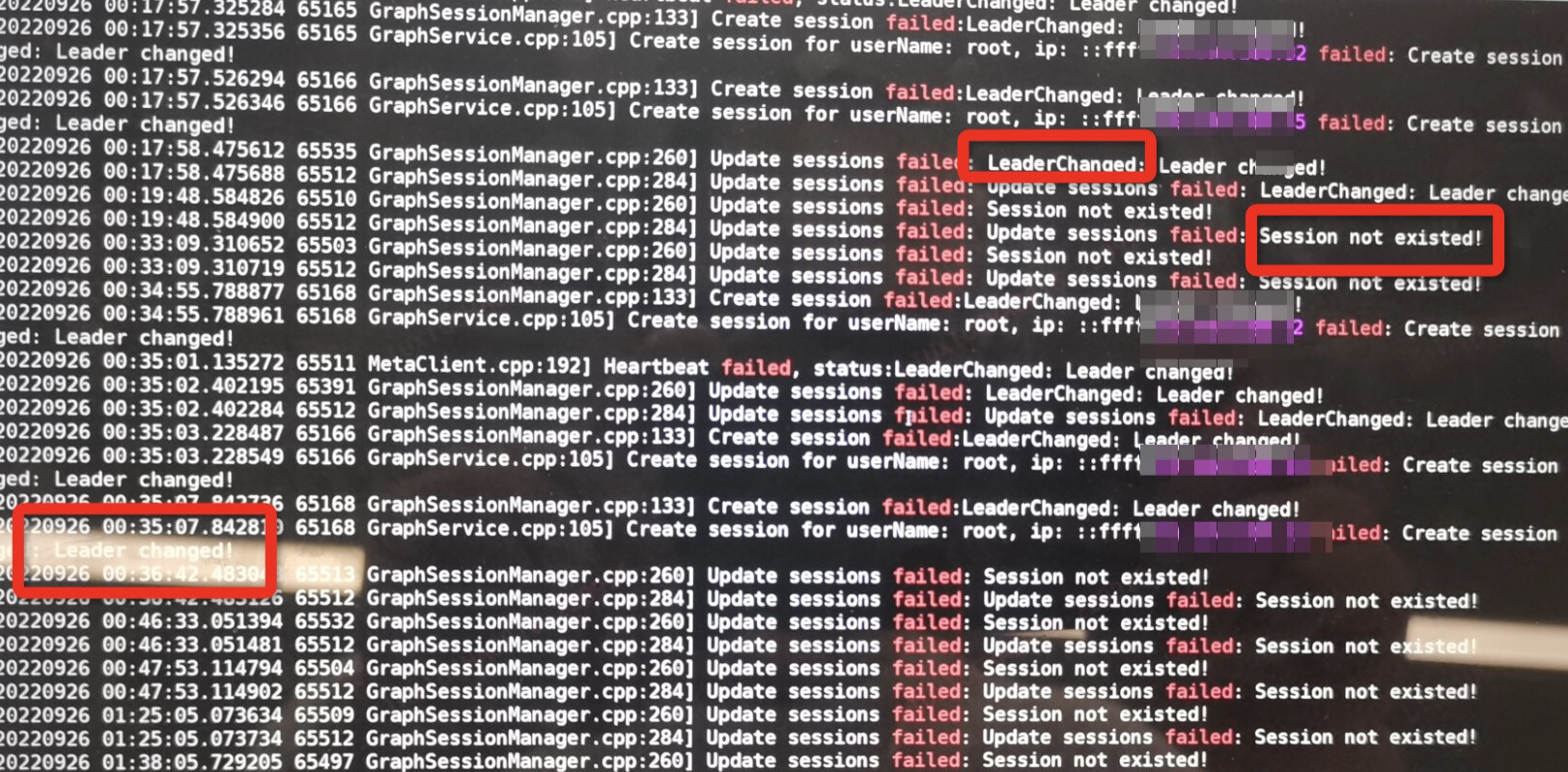
leader changed告警,但是后续服务好像也不可用了,想问一下,什么情况下会出现leader changed, 我理解服务都是稳定的,配置这些都没调整的话是不是应该不会出现leader changed
-
重启之后,一段时间内出现了 metaClient服务心跳的错误,RPC falied
看了下相关的帖子, 感觉有点类似, 我们的场景也是会高并发的读写, session应该是没有特殊处理的,理论上每次读写都会创建、删除sessionhttps://discuss.nebula-graph.com.cn/t/topic/9574/17?u=wuyou
因为是在现场部署,连接不到服务器, 很多日志信息都是通过截图观察总结的。 大致是上述的情况,想看一下如何避免, 因为目前我们会采集几千万的数据,如果期间老是出现问题,数据不一致
1 个赞
spw
2
应该是使用 session 的粒度太细了,是不是每个 query 都用了一个 session?这样的话会造成 session 频繁生成和销毁,进而造成 metad 的频繁写入(session 属于元信息),以至于打死 metad,造成 leader change。
最好维持一个 session pool,对 session 进行复用。
1 个赞
wuyou
3
那我这边先暂时部署一个应用服务节点看看是否还会出现leader change, nebula还是保持三个节点
spw
4
得改应用层使用 session 的方式呀,不是光降应用服务节点数量就能搞定的。要是一个 QPS 还是很高,还是可能出现这个问题。
wuyou
5
目前我们要先跑一部分数据, 慢一点也行, 先验证如果一个节点的话是否还是会出现这个问题。 咨询了你们的小伙伴, 了解到未来一两个月会有相关的动作, 打算先不自己去实现。
wuyou
7
请教一下, 因为之前也断断续续的咨询过你们,有一些结论,就是不同的线程使用一个session会直接报错。想再问一下, 这里会报错指的是同一时间不同的线程使用了同一session就会报错还是说session是和线程是绑定的, 只要检测到不同的线程来使用一个已经绑定过其他线程的session就会报错。
还有一个问题看方不方便描述,就是为什么不同的线程使用同一session会有线程安全的问题,哪怕目前其实我只有一个space。
Aiee
8
这里会报错指的是同一时间不同的线程使用了同一session就会报错还是说session是和线程是绑定的
是前者, thrift 内部的连接实现不是线程安全的, 所以不能多线程用同个 session
1 个赞
wuyou
9
在请教一下, 目前的问题就是消费kafka之后对nebula进行读写, 初步判断是因为频次比较高,导致meta服务出了问题, 一直leader changed。 想问一下, 能支持多少的并发读写, 或者qps大概有多少。。 目前是三个节点(每个节点都有一个graphd、 meta、storage),内存也是足够的,256G
system
关闭
10
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。