- nebula 版本:v3.1.0
- 部署方式:分布式
- 安装方式: RPM
- 是否为线上版本:Y
- 硬件信息
CPU: 72 Core Intel(R) Xeon(R) Gold 6240 CPU @ 2.60GHz
Memory: 192 G DDR4
SSD: NVME 16 T
Below are the details:
Nebula Version: v3.1.0
Deployment:
三台机器每台一个 nebula-metad, 一个 nebula-graphd, 一个 nebula-storaged.
Machine Info:
CPU: 72 Core Intel(R) Xeon(R) Gold 6240 CPU @ 2.60GHz
Memory: 192 G DDR4
SSD: NVME 16 T
Space Statistics:
Partition Number:240 Replica Factor : 3
- vertices: 800 million
- member Tag : 250 million
- edges: 9.5 billion
- follow: 2.6 billion
show hosts
+----------------+------+-----------+----------+--------------+---------------------------+----------------------------+---------+
| Host | Port | HTTP port | Status | Leader count | Leader distribution | Partition distribution | Version |
+----------------+------+-----------+----------+--------------+---------------------------+----------------------------+---------+
| "10.0.0.1" | 9779 | 19669 | "ONLINE" | 80 | "base_space:80" | "base_space:240" | "3.1.0" |
| "10.0.0.2" | 9779 | 19669 | "ONLINE" | 80 | "base_space:80" | "base_space:240" | "3.1.0" |
| "10.0.0.3" | 9779 | 19669 | "ONLINE" | 80 | "base_space:80" | "base_space:240" | "3.1.0" |
+----------------+------+-----------+----------+--------------+---------------------------+----------------------------+---------+
---------+------------+------------+
| Type | Name | Count |
+---------+------------+------------+
| "Tag" | "content" | 532806319 |
| "Tag" | "member" | 261499703 |
| "Edge" | "follow" | 2611243656 |
| "Edge" | "upvote" | 6837411544 |
| "Space" | "vertices" | 794306022 |
| "Space" | "edges" | 9448655200 |
+---------+------------+------------+
问题场景:
A 关注了 B, B 关注了 C, 想找出所有的B
A 可能关注了 10 到 1000 人
C 可能有 10 到 10000000 的关注者
使用 FIND ALL PATH 、GO 语句查询比较慢,是否有更优的查询方式或者调优方案?
nGQL and profile result
Case detail: 用户 m_1 关注了 277 用户, m_2 有大约100万关注者
MATCH:
尝试使用 MATCH 语句花费大概 17 秒.
MATCH (m)-[e:follow]->(n:member) WHERE id(m)=="m_1" MATCH (n)-[f:follow]->(l) WHERE id(l)=="m_2" RETURN id(n);
Explain result :

Profile result:

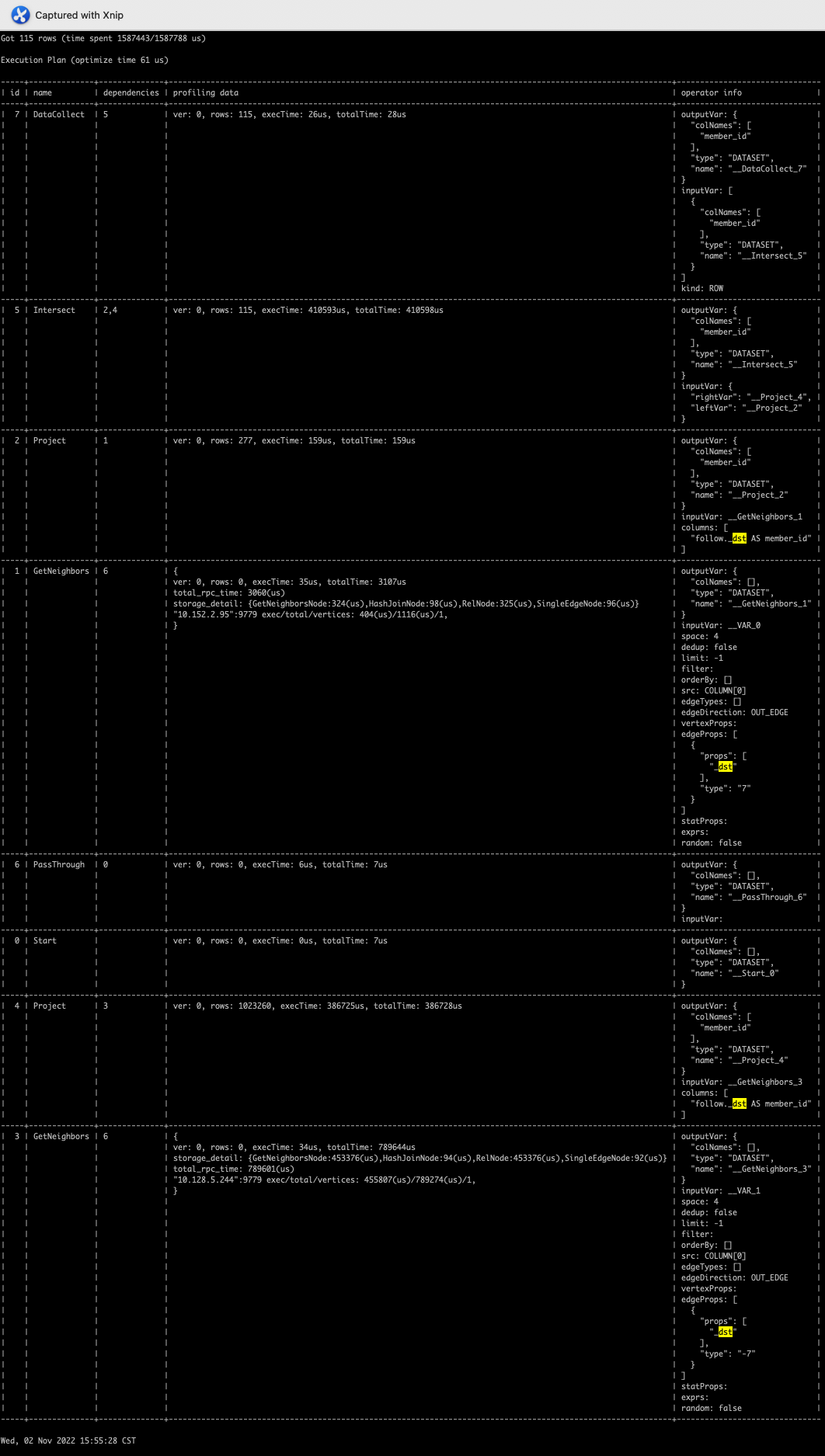
在本例中,我们不需要任何属性,所以我们尝试了 GO and FIND PATH 语句:
GO:
GO FROM "m_1" OVER follow YIELD dst(edge) AS member_id INTERSECT GO FROM "m_2" OVER follow REVERSELY YIELD src(edge) AS member_id
Explain result :

Profile result:

FIND PATH
FIND ALL PATH FROM "m_1" TO "m_2" OVER follow,follow UPTO 2 STEPS YIELD path AS p | YIELD nodes($-.p) AS nodes | YIELD $-.nodes AS nodes, size($-.nodes) AS len | YIELD id($-.nodes[1]) as id WHERE $-.len == 3
Explain result:

Profile result:

GO语句花费3秒,FIND PATH语句花费6秒。以上所有的方法我们都不能满足我们的要求。在阅读了关于处理超级顶点的文档后,我们尝试了一些解决方案。
- Compact: 没有效果
- Truncation: 不能满足需求,因为我们想要所有的数据
客户端处理方案也不适合我们:
- 删除多条边,合并为一条: 两个成员之间只有一个关注类型的边
- 拆分相同类型的边,变为多种不同类型的边: 同上
- 切分顶点本身:一个用户没办法切分