提问参考模版:
- nebula 版本:V2.6.2
- 部署方式:分布式
- 安装方式:tar包安装
问题描述:
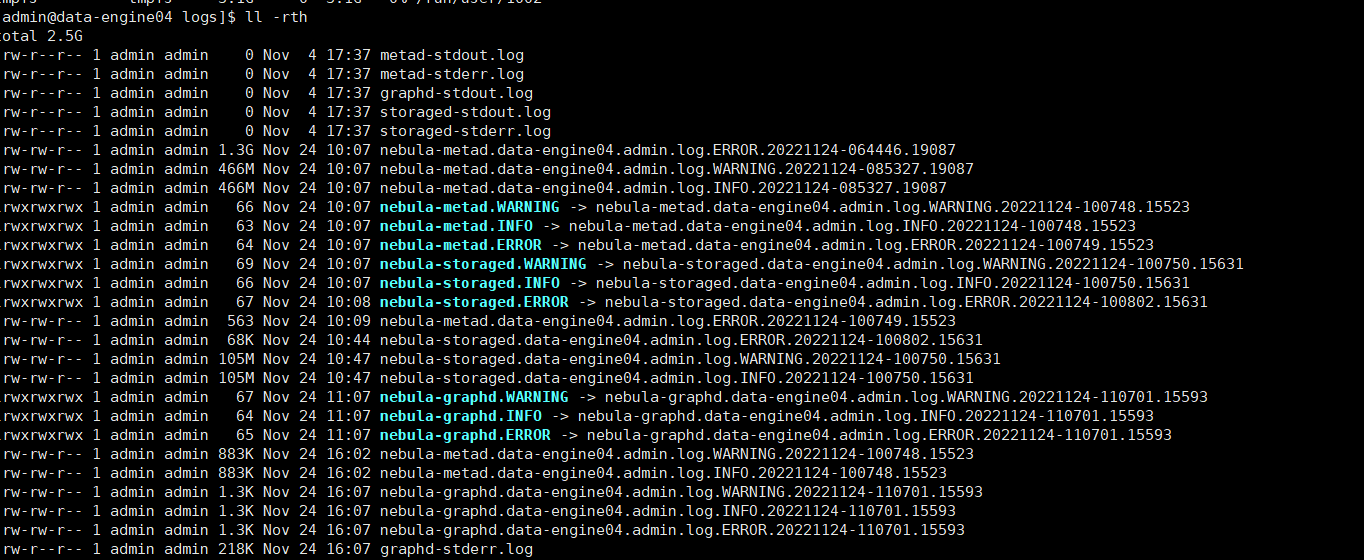
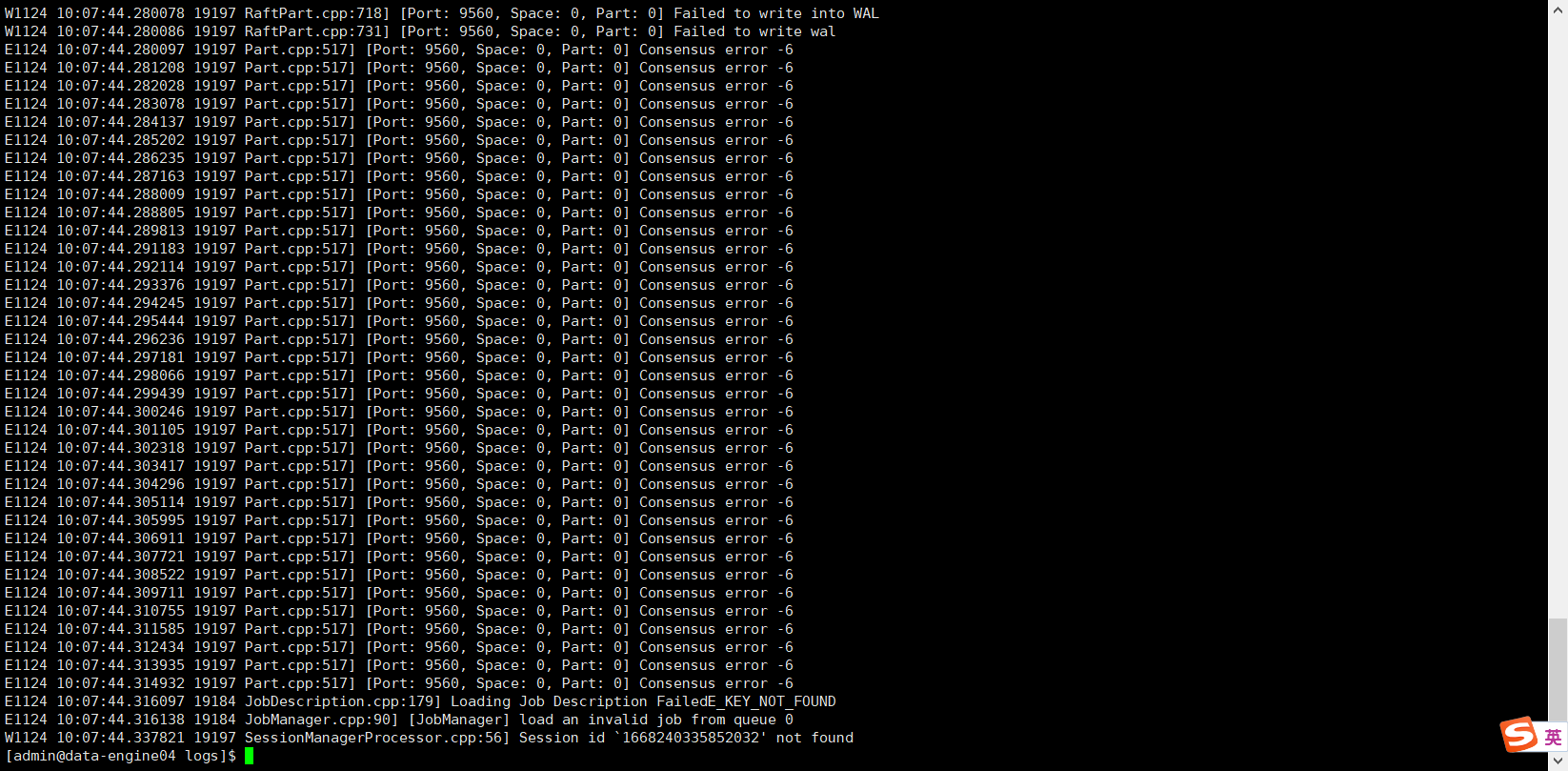
nebula-graph经常会遇到一些错误后,疯狂打印日志,导致磁盘被占满。经常把磁盘打印到90%
我查看了文档,要么完全关闭日志打印,要么就只能自己写脚本物理删除了。
需求:
贵团队有没有提供清理日志的脚本?或者清理规则思路?应该怎么删除合适?
提问参考模版:
问题描述:
nebula-graph经常会遇到一些错误后,疯狂打印日志,导致磁盘被占满。经常把磁盘打印到90%
我查看了文档,要么完全关闭日志打印,要么就只能自己写脚本物理删除了。
需求:
贵团队有没有提供清理日志的脚本?或者清理规则思路?应该怎么删除合适?
我的日志级别已经调整了,是warning日志了。warning或者error都会打印日志,疯狂打印,知道磁盘满
minloglevel 这个配置,我现在设置的是1
可以大概给几行看看 warning 都是什么日志吗?
如果写删除shell脚本的话,以什么规则删除呢?比如删除昨天及以前的日志?还是删除大于多少G的文件?
我们日志组件用的时 glog,可以首先在各个 conf 文件中设置单个文件的最大大小,参数是: https://github.com/google/glog/blob/master/src/glog/logging.h.in#L494 ;然后写个监听 shell 脚本定期删老日志文件就可以。网上有很多相关脚本,比如说随便搜了一个,改改路径和配置应该就可以(注意测试):glog配置与持久化记录_时暑的博客-CSDN博客
#glog日志路径
log_path="/mnt/hgfs/test/log"
#监听频率 3秒扫描一次
monitor_time=3
#是否开启监听
working_flag=true
#当日志文件超过该值则删除旧文件
file_number_threshould=10
cd $log_path
while $working_flag
do
#判断日志文件个数是否超过阀值
file_number=$(ls -l | grep "a.wang-virtual-machine.wang.log.INFO*" | wc -l )
if [ $file_number -gt $file_number_threshould ]
then
#把文件按从旧到新的顺序排列,删除旧日志,保留最新的10个日志文件
declare -i delete_number=$(expr $file_number - $file_number_threshould )
rm -r $(ls -rt | head -n$delete_number)
fi
sleep $monitor_time #休眠
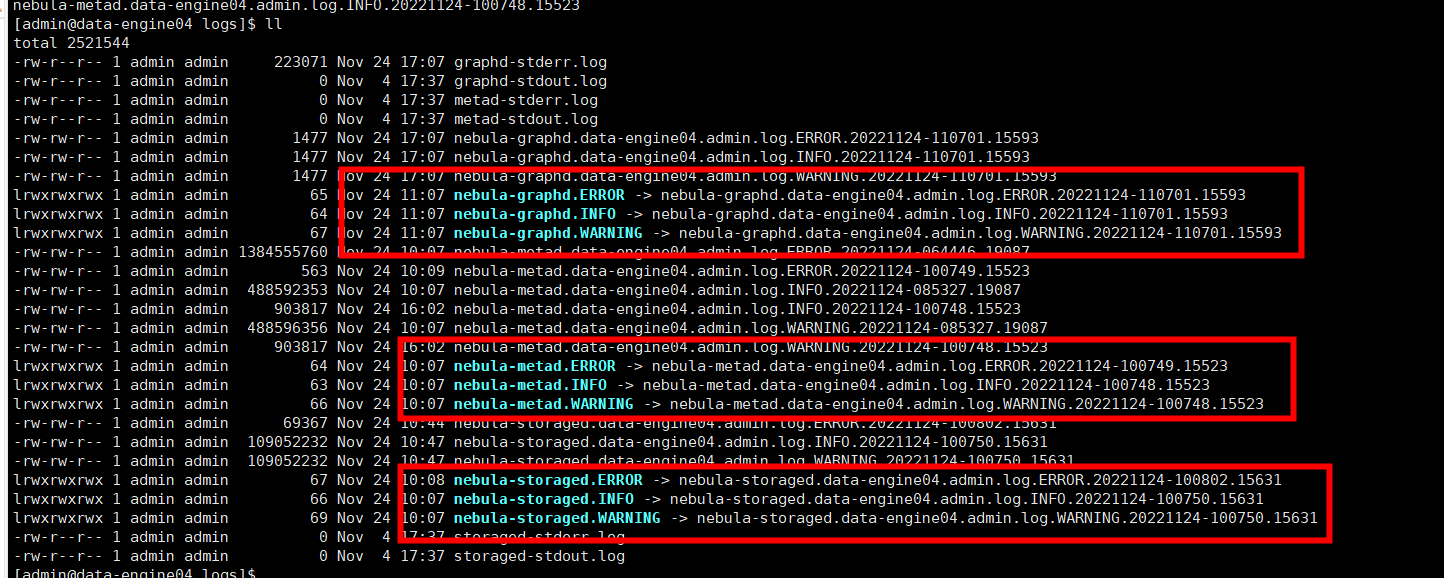
只要不删除最新的那个就可以,那个软连接一般都是指向最新的;所以你在删除的时候可以对于 metad/graphd/storaged 的日志分别按日期进行排序,然后保留最新的一两个,其他都删除。
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。