你用的这个版本应该还没有对应边的过滤下推,最新的分支的版本才完成的优化,可以考虑截断来防止一下 OOM
这个具体可以帮我看下嘛 帮我优化一个,其他的,其他的我仿照这个来改,感觉无从下手 我是nebula3.3.0
match (m:USER) where id(m) in [“1510615318”] optional match (m)-[r1:CALL_TO]-(x:MOBILE)-[:APPLY_FOR]->(a1:APPL)-[:APPLY_ON]-(t1:TIME) where r1.first_callmark_on<=20220102 and t1.TIME.date < ‘2022-01-02’ with m,collect(distinct x) as col_appl_1st_v4 unwind case when size(col_appl_1st_v4) == 0 then [null] else col_appl_1st_v4 end as x match (x)-[r2:CALL_TO]-(n:USER) where r2.first_callmark_on<=20220102 and id(n)<>‘1510615318’ with m,col_appl_1st_v4,collect(distinct n) as col_user_2nd_v4 with m,col_appl_1st_v4,col_user_2nd_v4, [n in col_user_2nd_v4 WHERE “MOBILE” in labels(n)] as col_mobile_2nd_v4 return size(col_appl_1st_v4) as n_appl_1st_v4,size(col_user_2nd_v4) as n_user_2nd_v4;这个cypher应该如何改写呢
如果是 3.3 的版本,还不包含一些优化,你可以试试 nightly 的版本,针对上面的产生 OOM 的 pattern,应该是有对应边上的过滤下推,如果过滤之后的依然产生 OOM 的话,暂时考虑截断吧;
上面的改写可能不能解决你的问题

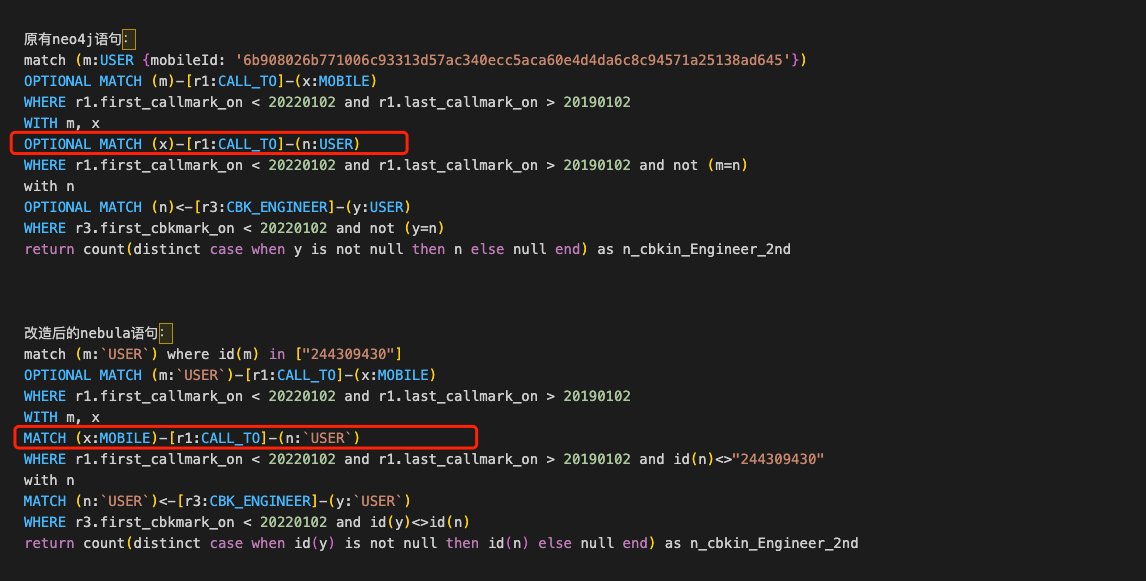
怀疑碰到了超级节点,能看下两个 x 对应的那个 pattern 的边的数量吗?比如:
MATCH (x)-[:CALL_TO]-(:`USER`)
WHERE id(x)=="xxxxx"
RETURN count(*)
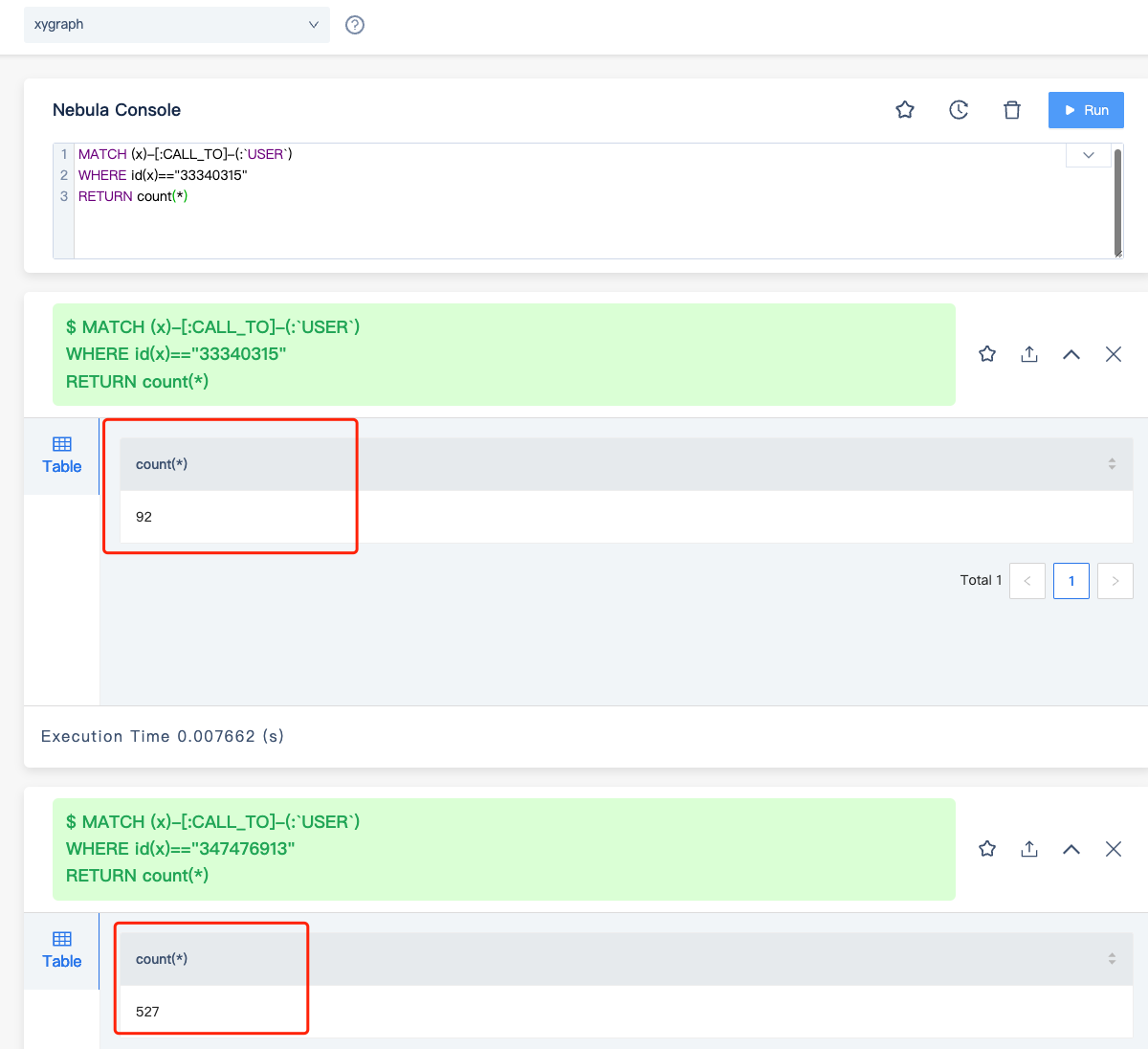
把上面的 "xxxxx" 换成你说的结果中的每一个试试?
match (m) where id(m) in [“1391958719”] optional match (m:
USER)-[r1:CALL_TO]-(x:MOBILE)-[:APPLY_FOR]->(a1:APPL)-[:APPLY_ON]-(t1:TIME) where r1.first_callmark_on<=20220602 and replace(t1.TIME.date,‘-’,‘’)<=‘20220602’ with m,collect(distinct x) as col_appl_1st_v4 unwind case when size(col_appl_1st_v4) == 0 then [null] else col_appl_1st_v4 end as x return x;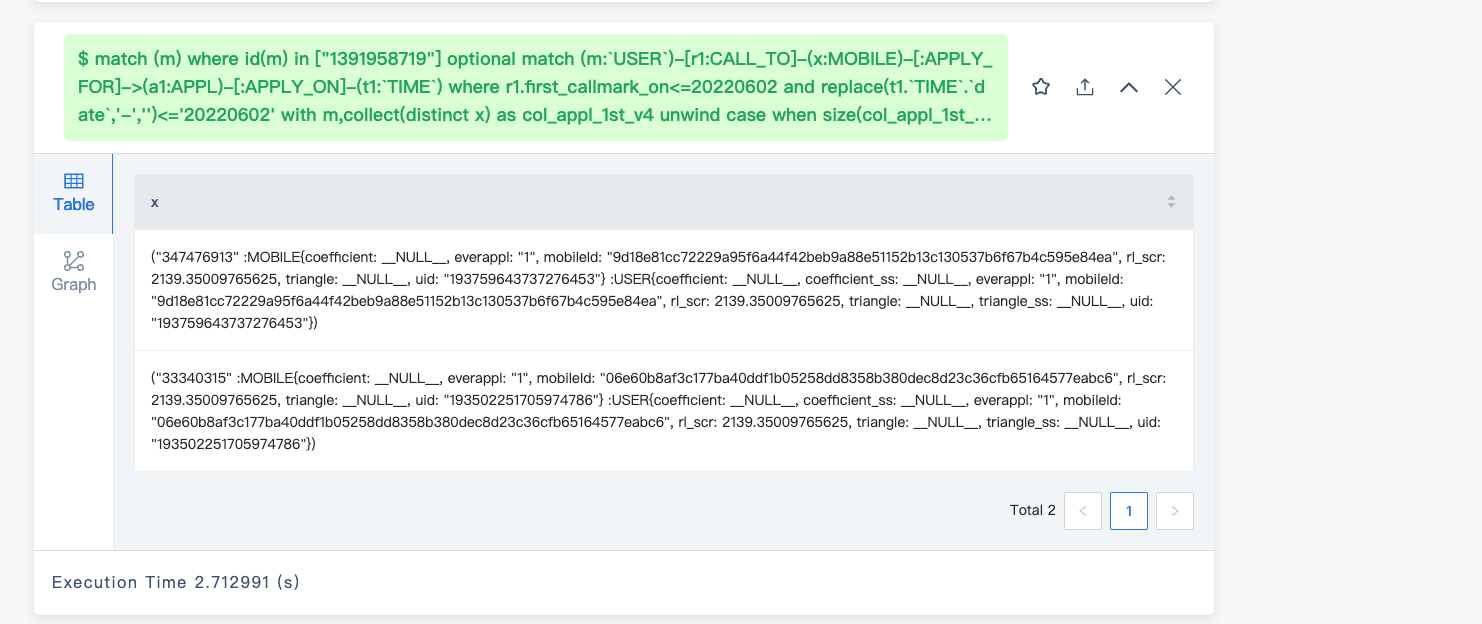
这是查出来的结果
看起来不像是会 OOM 的情况,可否 explain 一下最开始的 query,贴一下 plan 的结果
辛苦帮我看下 执行计划 有点看不懂
你给我的计划也不是很好阅读,你能点一下 左下角的 graph 结构截图发一下吗?
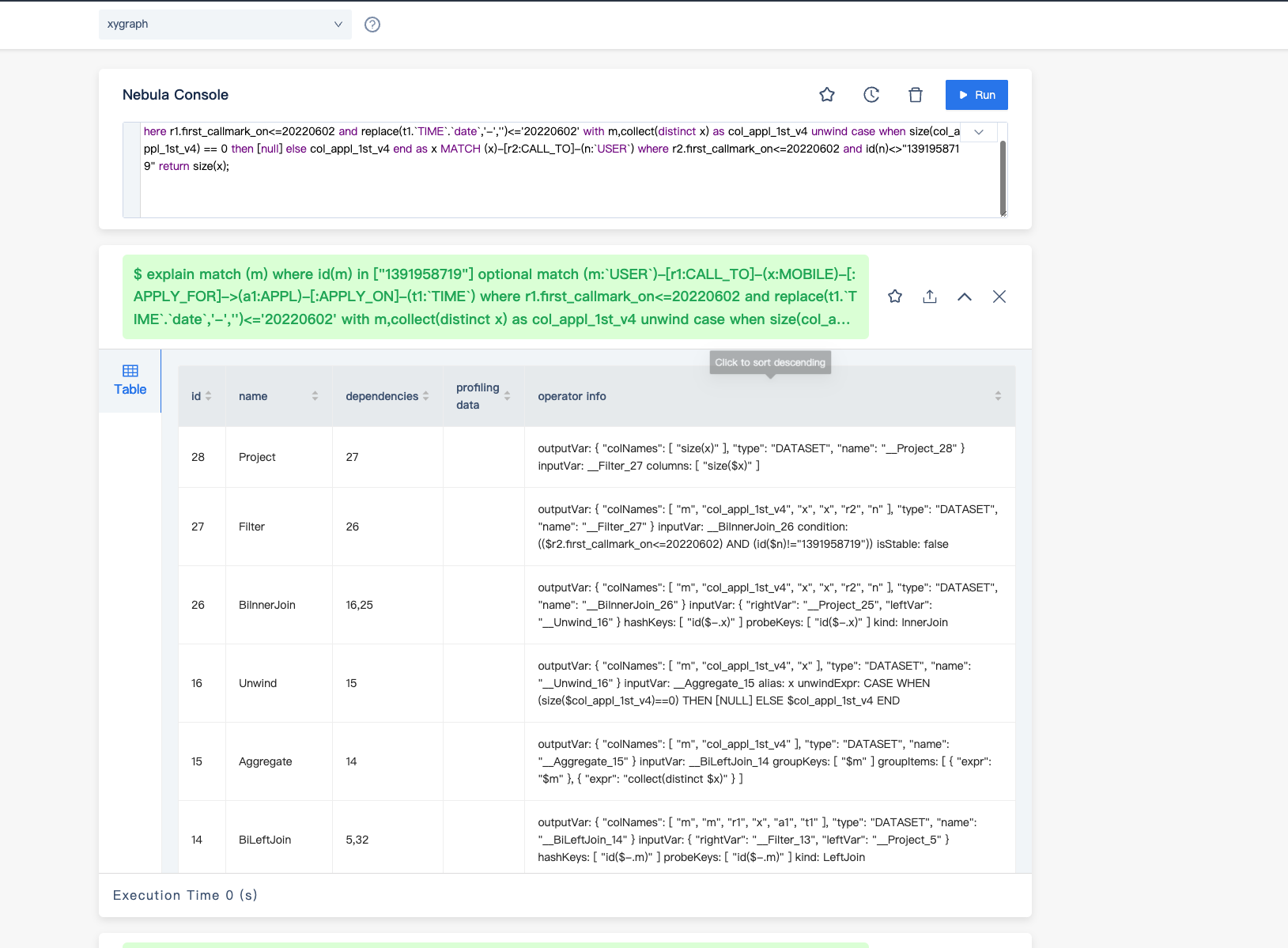
能不能把上面的图的下半部分截图截全些?先这样看看这个 table 样式的吧
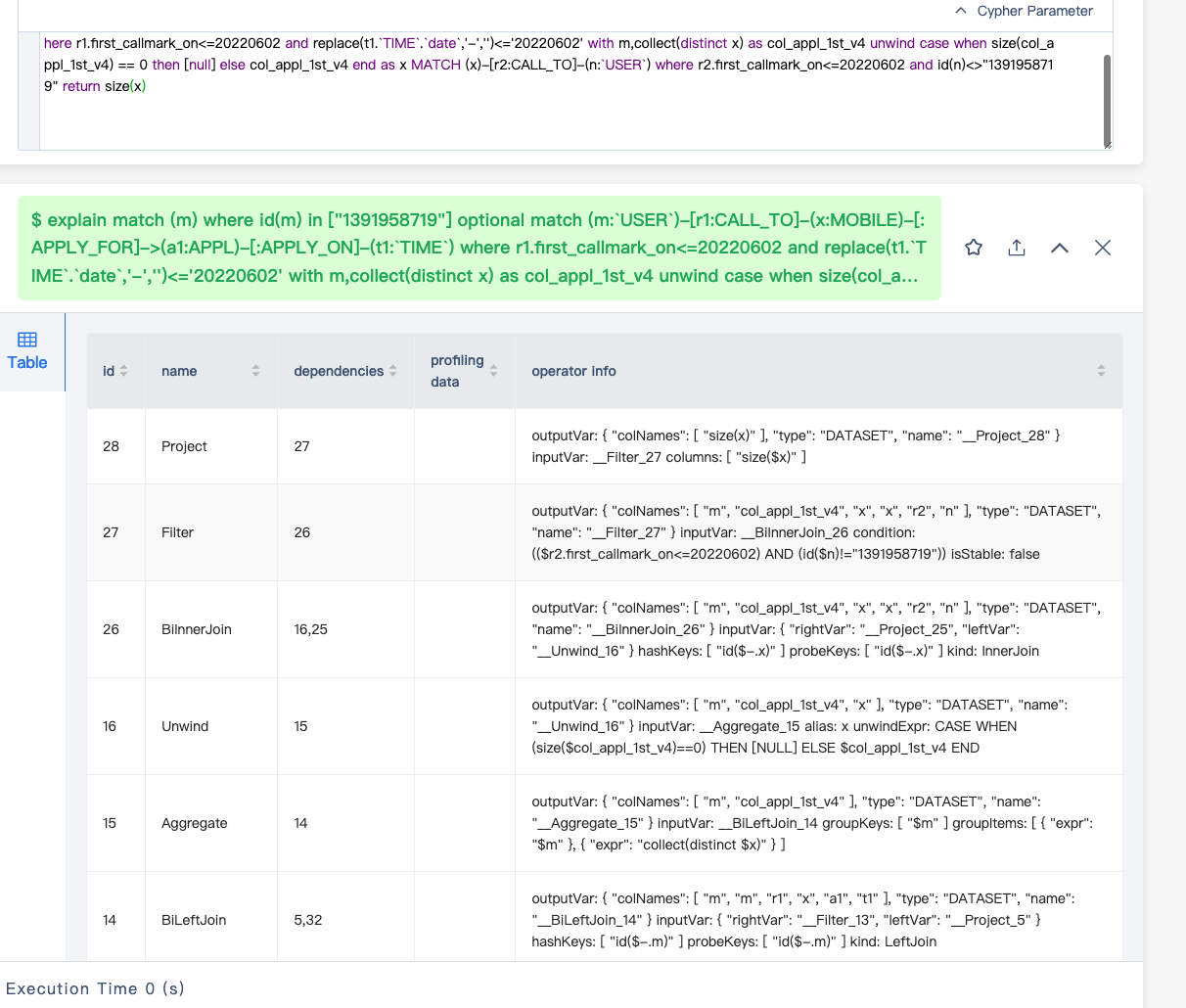

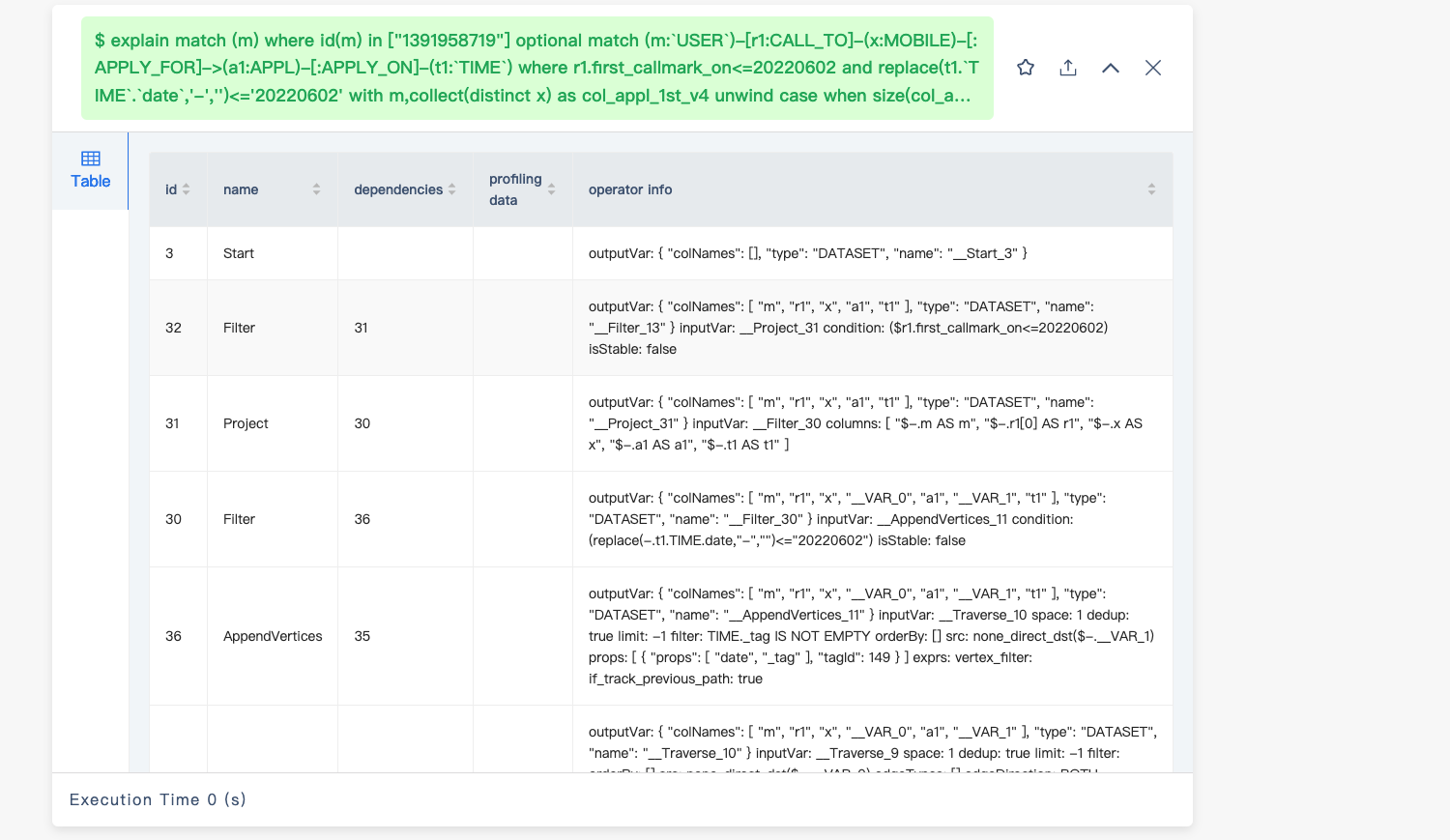

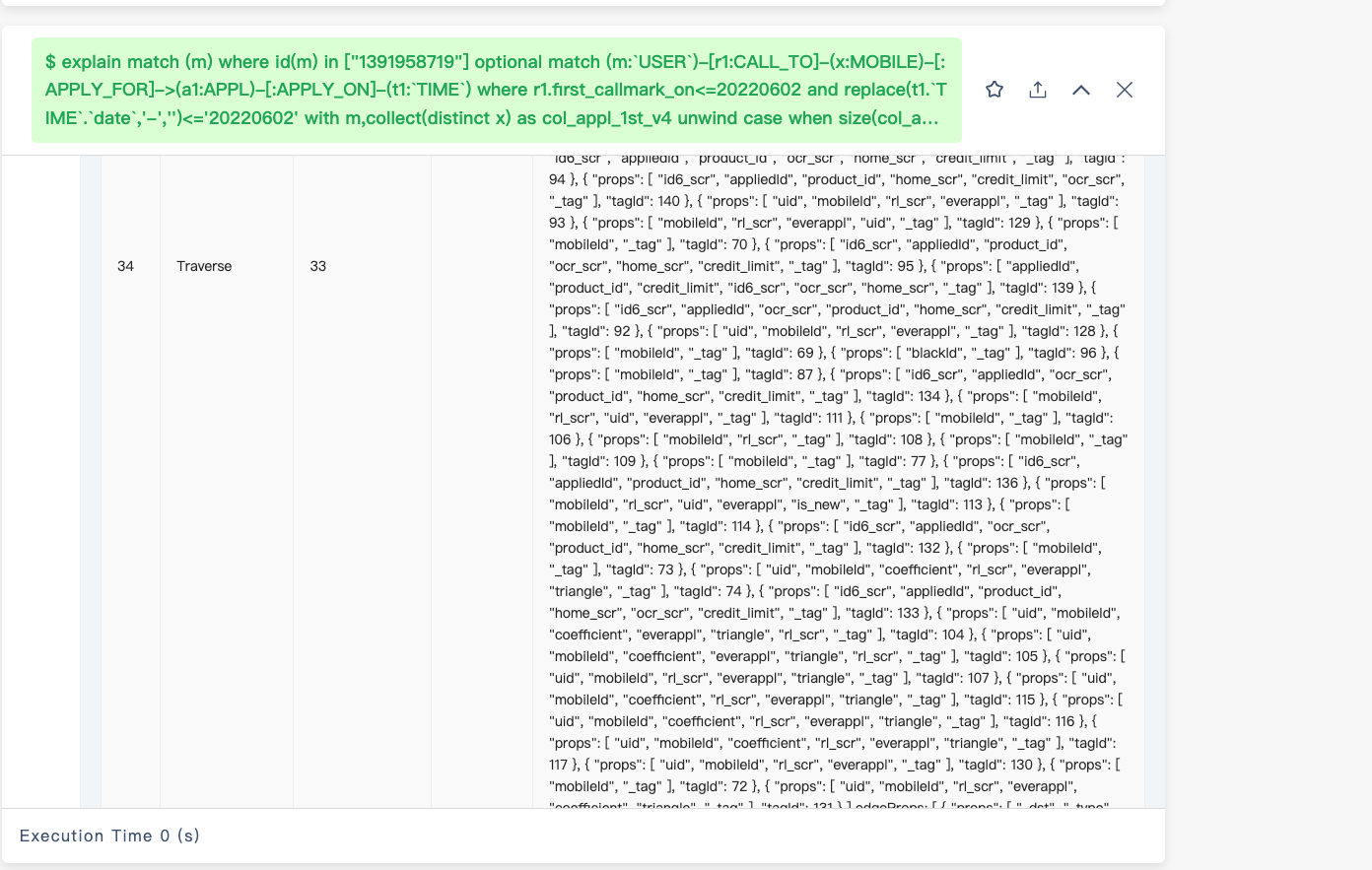
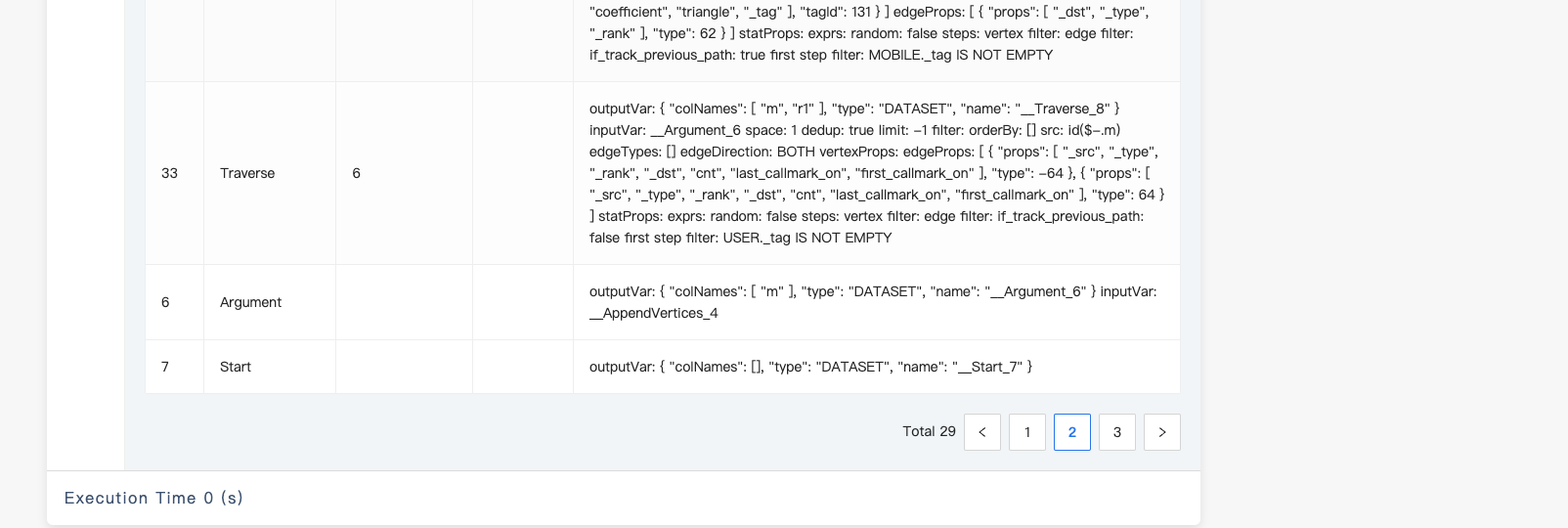
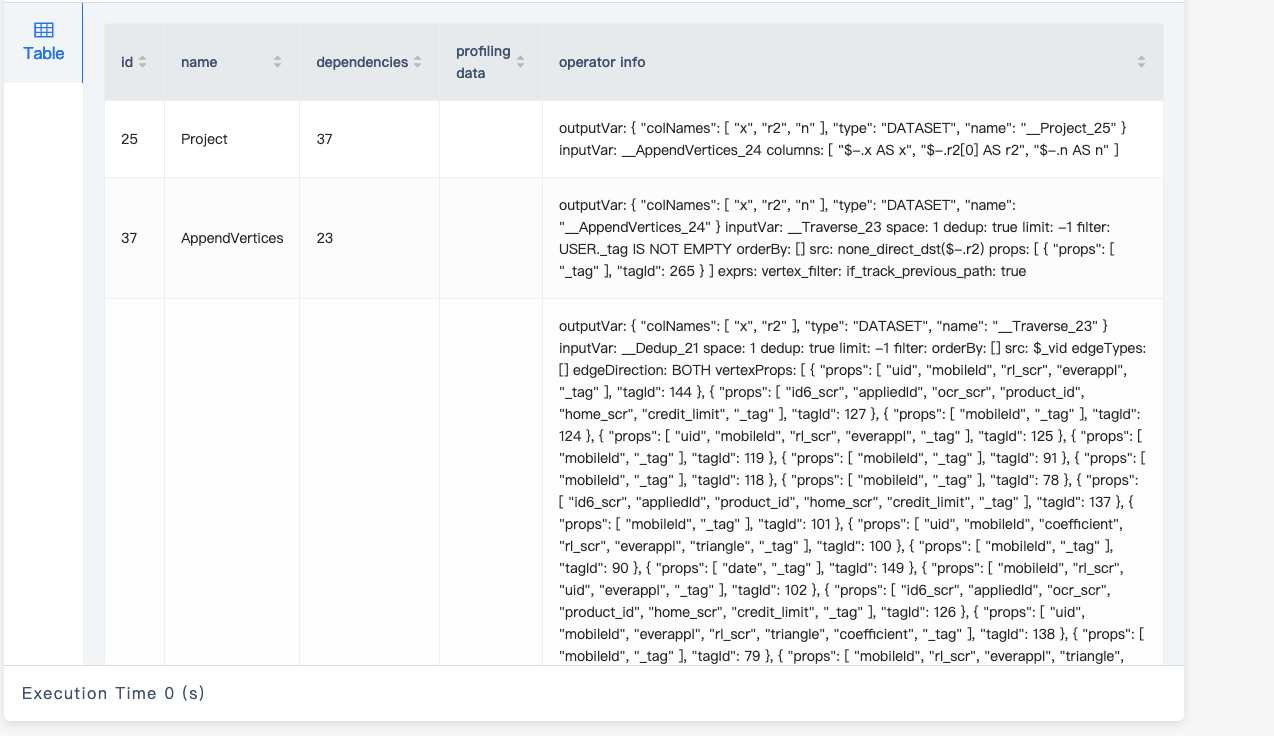
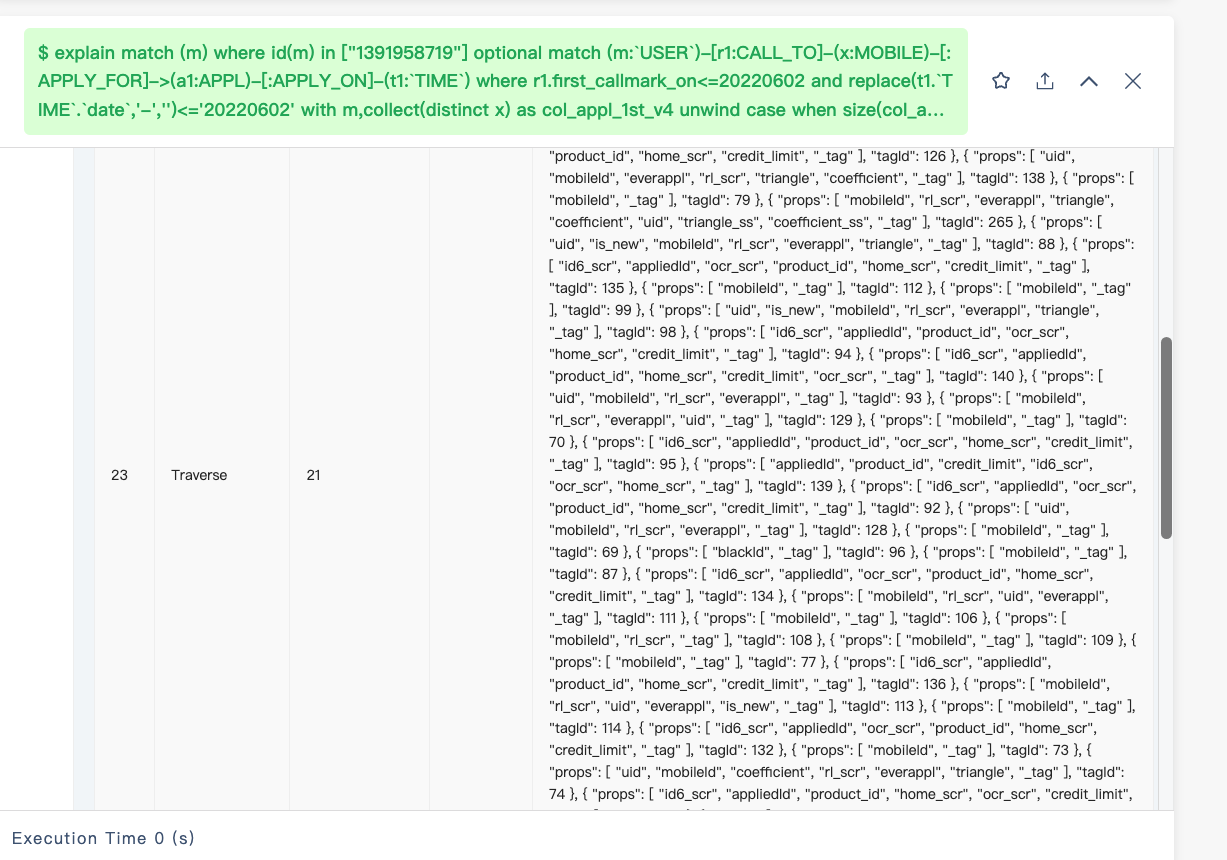


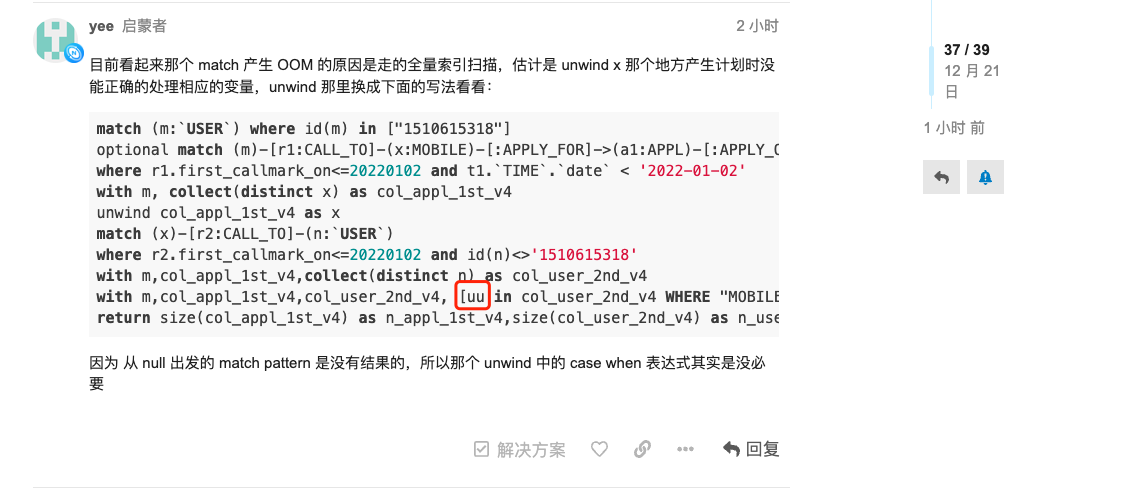
目前看起来那个 match 产生 OOM 的原因是走的全量索引扫描,估计是 unwind x 那个地方产生计划时没能正确的处理相应的变量,unwind 那里换成下面的写法看看:
match (m:`USER`) where id(m) in ["1510615318"]
optional match (m)-[r1:CALL_TO]-(x:MOBILE)-[:APPLY_FOR]->(a1:APPL)-[:APPLY_ON]-(t1:`TIME`)
where r1.first_callmark_on<=20220102 and t1.`TIME`.`date` < '2022-01-02'
with m, collect(distinct x) as col_appl_1st_v4
unwind col_appl_1st_v4 as x
match (x)-[r2:CALL_TO]-(n:`USER`)
where r2.first_callmark_on<=20220102 and id(n)<>'1510615318'
with m,col_appl_1st_v4,collect(distinct n) as col_user_2nd_v4
with m,col_appl_1st_v4,col_user_2nd_v4, [uu in col_user_2nd_v4 WHERE "MOBILE" in labels(n)] as col_mobile_2nd_v4
return size(col_appl_1st_v4) as n_appl_1st_v4,size(col_user_2nd_v4) as n_user_2nd_v4
因为 从 null 出发的 match pattern 是没有结果的,所以那个 unwind 中的 case when 表达式其实是没必要
检查了最新的开发分支上这个问题已经被修复了,加了对应的测试到用例集中:
1 个赞