提问参考模版:
- nebula 版本:3.2.0
- 部署方式:分布式
- 是否为线上版本:N
各位老师好!
我想复现一个反欺诈的案例,项目地址:https://www.nebula-graph.com.cn/posts/fraud-detection#post-图神经网络的方法 直接看“图神经网络的方法”章节就行。
目前已完成:
– yelp数据导入到nebula
– 安装了DGL 和 nebula-dgl,和一些必要库
我的nebula服务相关IP:
– meta_server_addrs=192.168.200.100:9559,192.168.200.101:9559,192.168.200.111:9559
– graphserver 192.168.200.100:9669, 192.168.200.101:9669, 192.168.200.111:9669, 192.168.200.112:9669, 192.168.200.114:9669
– 在nebula stadio中show hosts:
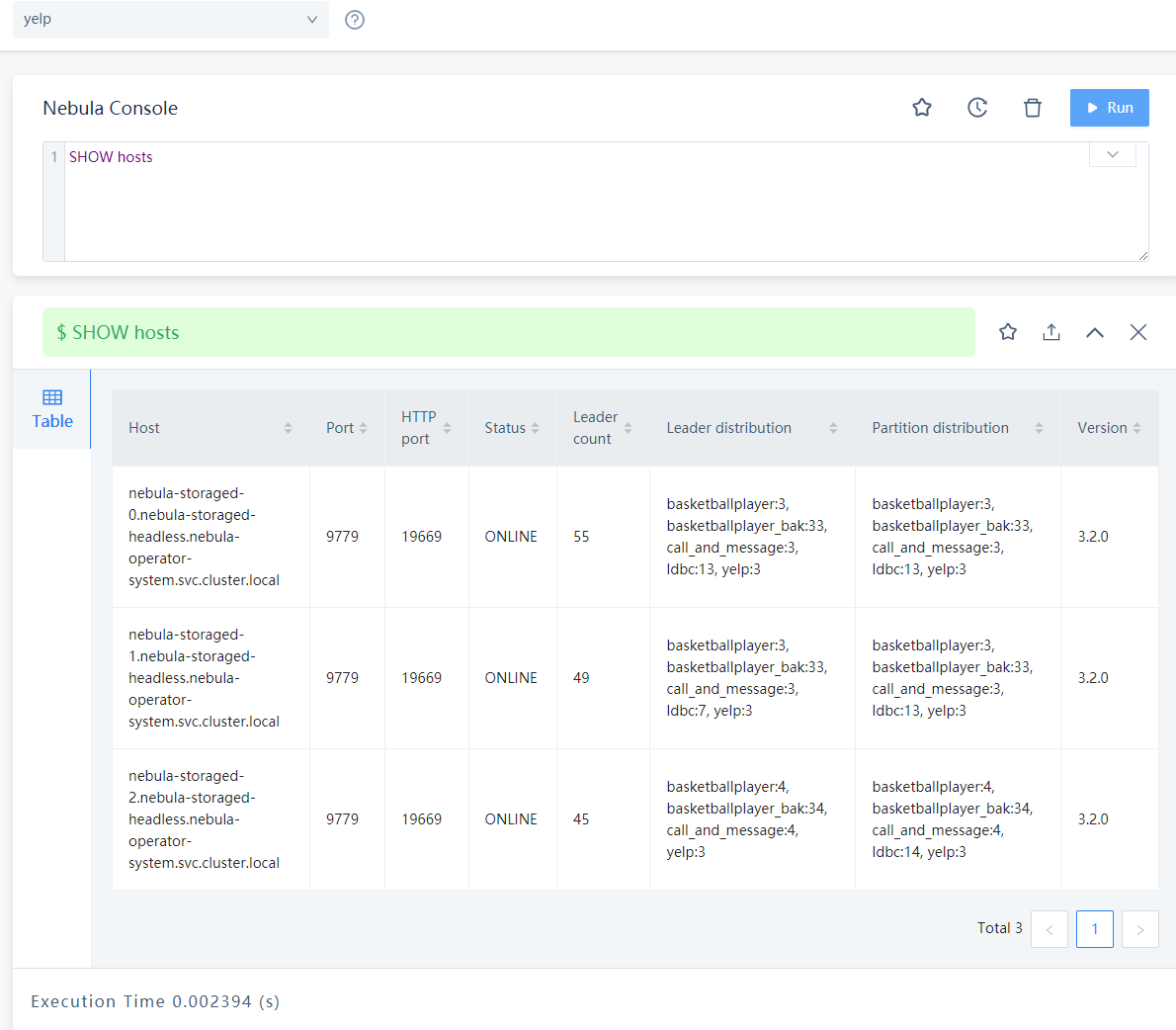
我目前做到了这里:
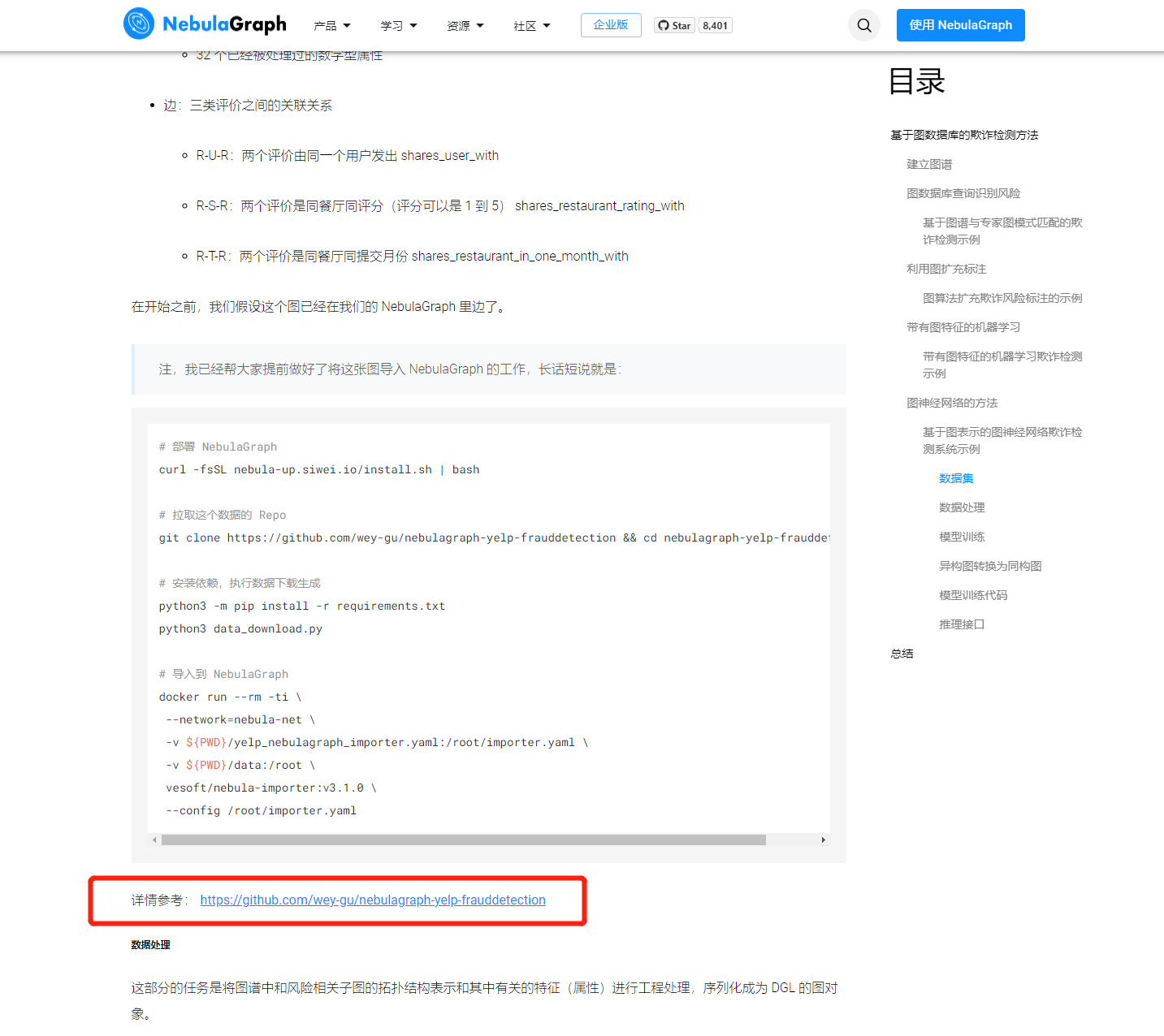
附上上图中红色框内的链接:https://github.com/wey-gu/nebulagraph-yelp-frauddetection
我跑下面这个测试时:
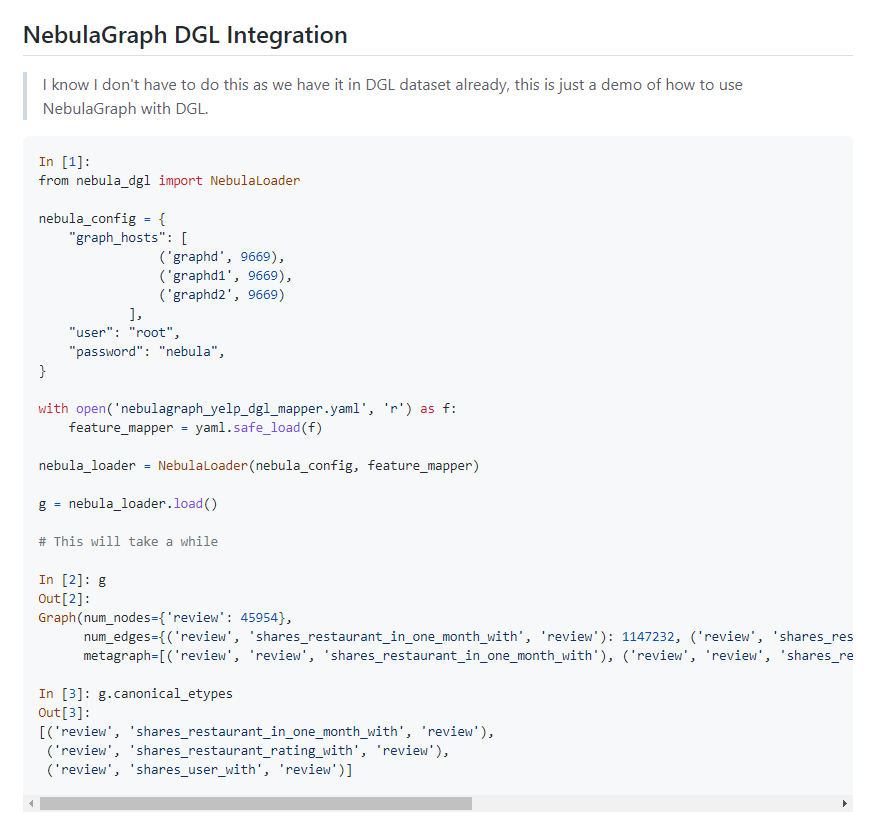
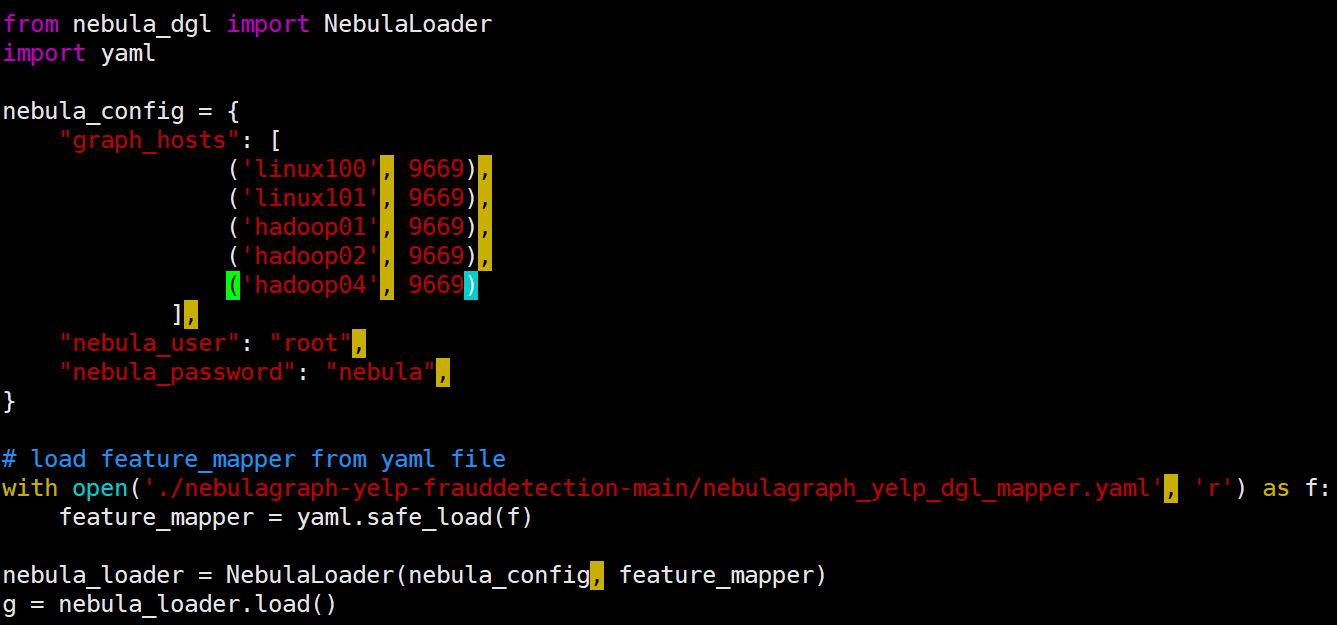
将graph_hosts的修改分别做了如下尝试:
1.
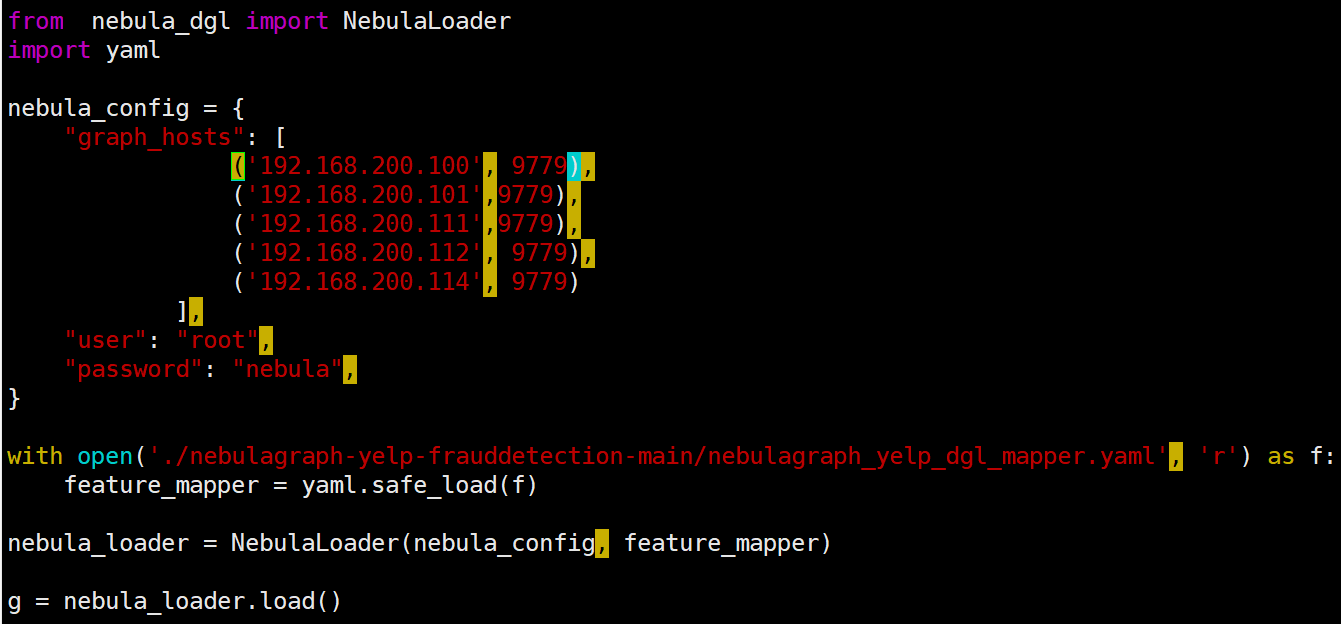
报错:

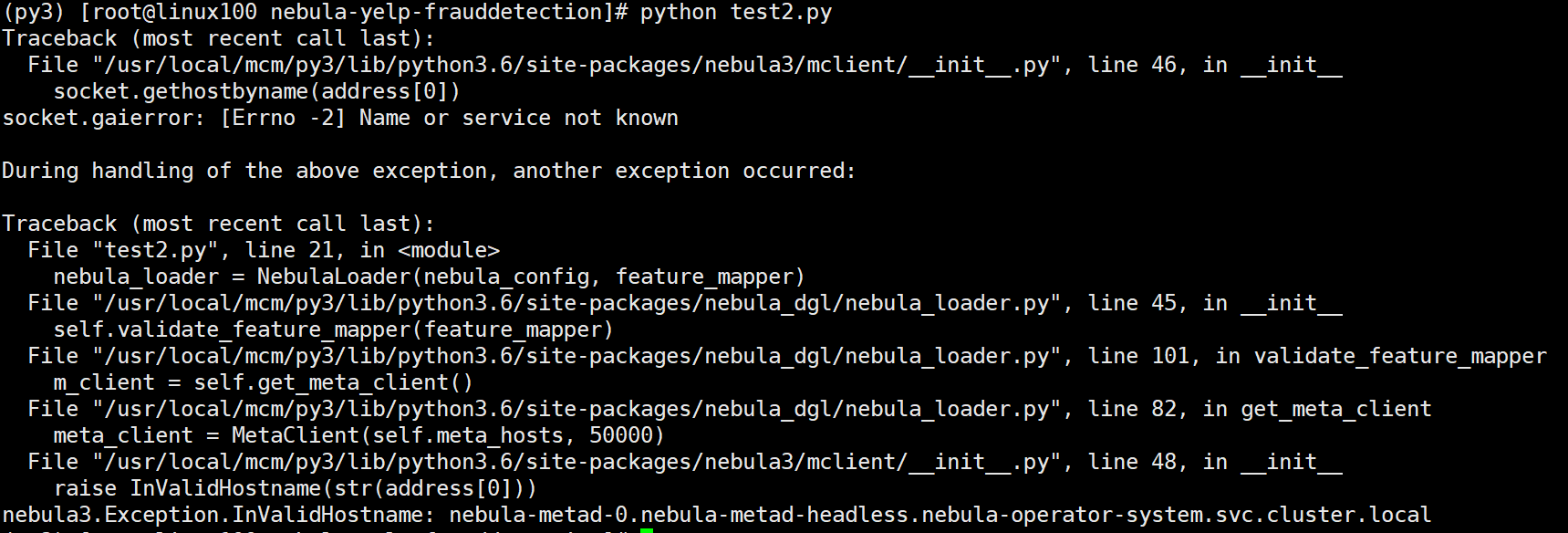
2.
报错:
3.
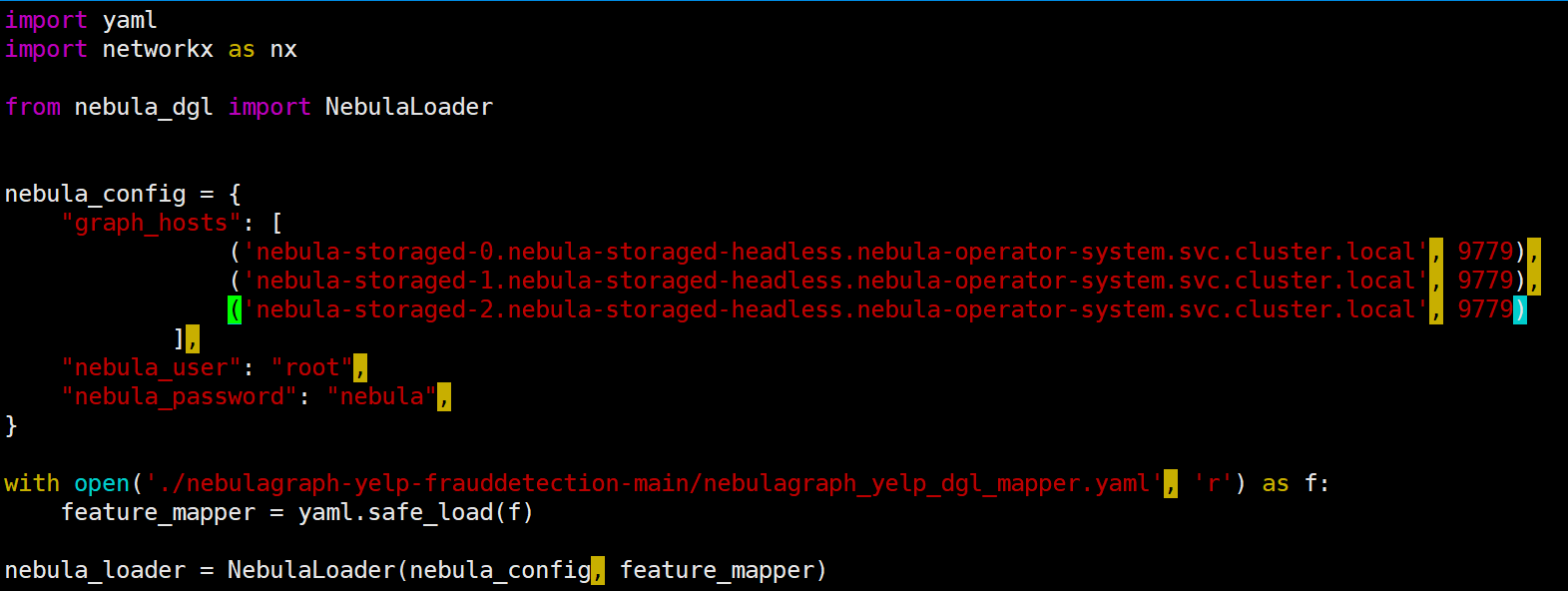
报错:
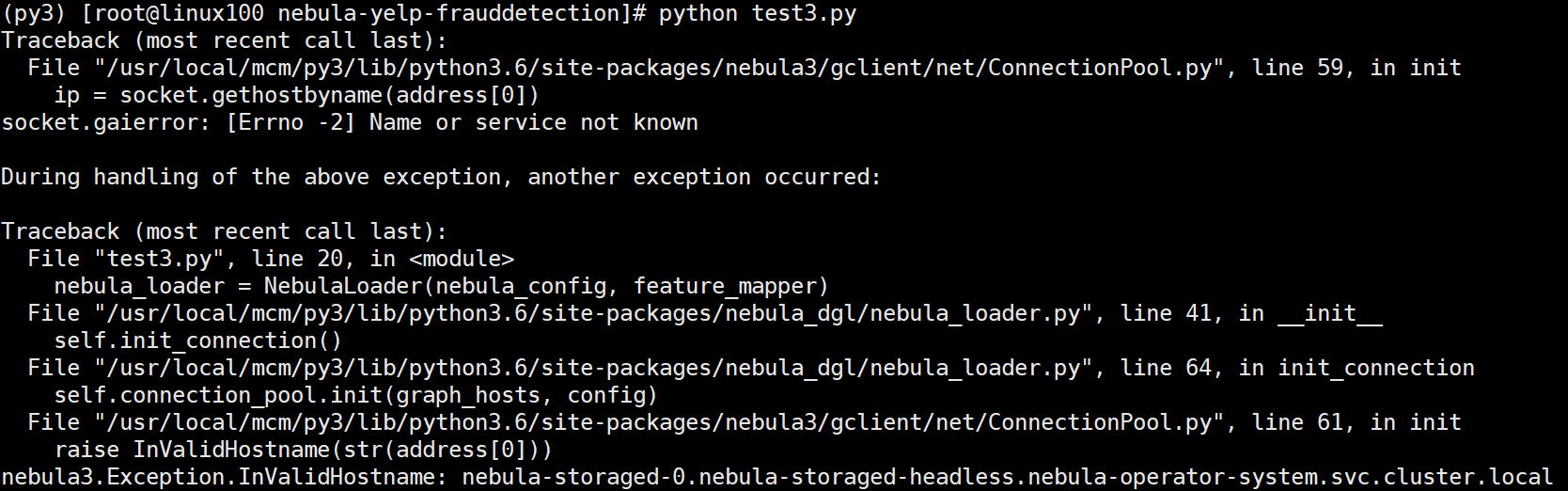
请问我应该怎么解决这个错误呢?