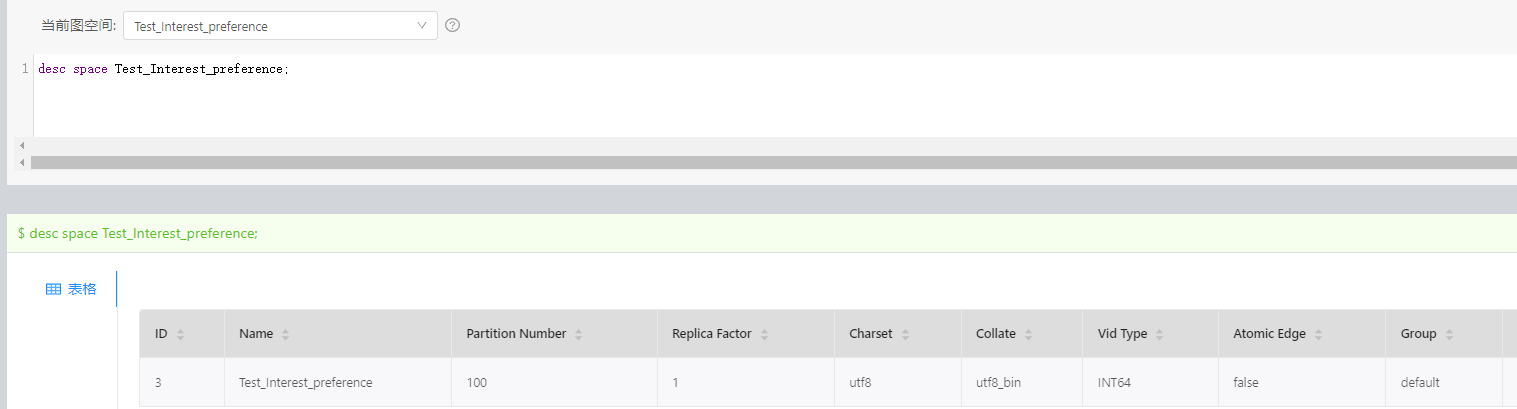
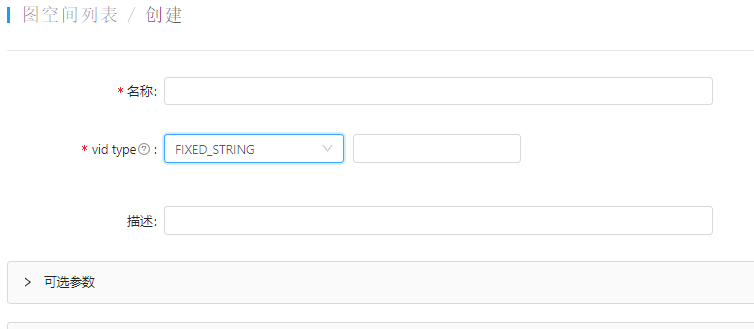
- nebula 版本:2.6,sparkconnector:2.6,spark 2.4.0(换成2.4.4,或2.4.3,依旧读取边的时候报错)
- 部署方式:单机
- 安装方式:源码编译
- 是否为线上版本:N
在写入vertex的时候,如果写入的顶点信息为字符串,则会报错:
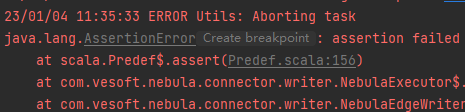
java.lang.AssertionError: assertion failed
at scala.Predef$.assert(Predef.scala:156)
at com.vesoft.nebula.connector.writer.NebulaExecutor$.extraID(NebulaExecutor.scala:60)
at com.vesoft.nebula.connector.writer.NebulaEdgeWriter.write(NebulaEdgeWriter.scala:56)
at com.vesoft.nebula.connector.writer.NebulaEdgeWriter.write(NebulaEdgeWriter.scala:17)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$$anonfun$run$3.apply(WriteToDataSourceV2Exec.scala:118)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$$anonfun$run$3.apply(WriteToDataSourceV2Exec.scala:116)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2Exec.scala:146)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec$$anonfun$doExecute$2.apply(WriteToDataSourceV2Exec.scala:67)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec$$anonfun$doExecute$2.apply(WriteToDataSourceV2Exec.scala:66)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:402)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:408)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
请问,如何将字符串形式的(如“关键词”)数据,写入顶点呀?(数字格式的数据是可以作为顶点写入vertex,但是中文字符无法作为顶点写入vertex)