机器配置:
nebula 版本:3.2.0
三台机器的集群,每台是6核 16g
数据总量500m

1、出现达到阈值,并且9669宕机的情况,偶尔出现挤占linux服务器资源导致linux服务器不能通过xsell连接
2、定位发现,当执行最短路径查询时,只有其中一台机器的内存是飙高的,另外两台机器的内存没有用到
机器配置:
nebula 版本:3.2.0
三台机器的集群,每台是6核 16g
数据总量500m
1、出现达到阈值,并且9669宕机的情况,偶尔出现挤占linux服务器资源导致linux服务器不能通过xsell连接
2、定位发现,当执行最短路径查询时,只有其中一台机器的内存是飙高的,另外两台机器的内存没有用到
16G?你确定没填错么?标题的 30 G 指的是集群一共么?
对的,我估算的集群大概可用的总数
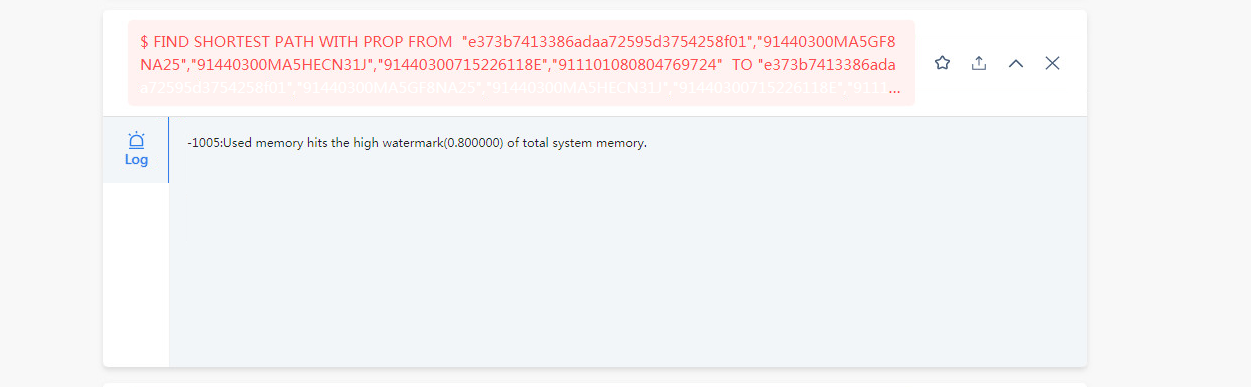
我输入的点总数是6个 最大度数是5度,他们之间的最短路径,就查不出来,再多输入一些,就会出现服务器9669挂掉的情况,偶尔出现linux连不上的情况
你可以在执行的语句前面加一个 explain 看下执行计划么(生成的执行计划文本贴过来——cv 就行)。![]() 信息比较全了我去找研发给你看看。
信息比较全了我去找研发给你看看。
嗯嗯可以的
已经跑着的查询的内存占用现在是没有限制的,所以会跑满,挤占 OS 甚至 sshd 的资源造成无法响应,在之前我们只能用 cgroup 等方式从 nebula 外部限制。庆幸的是,社区租金合并了 memtracker,提供了在 nebulagraph 进程内部去追踪、限制内存占用的能力,这个问题在下一个正式版本 3.4.0(马上发布)得到了解决。
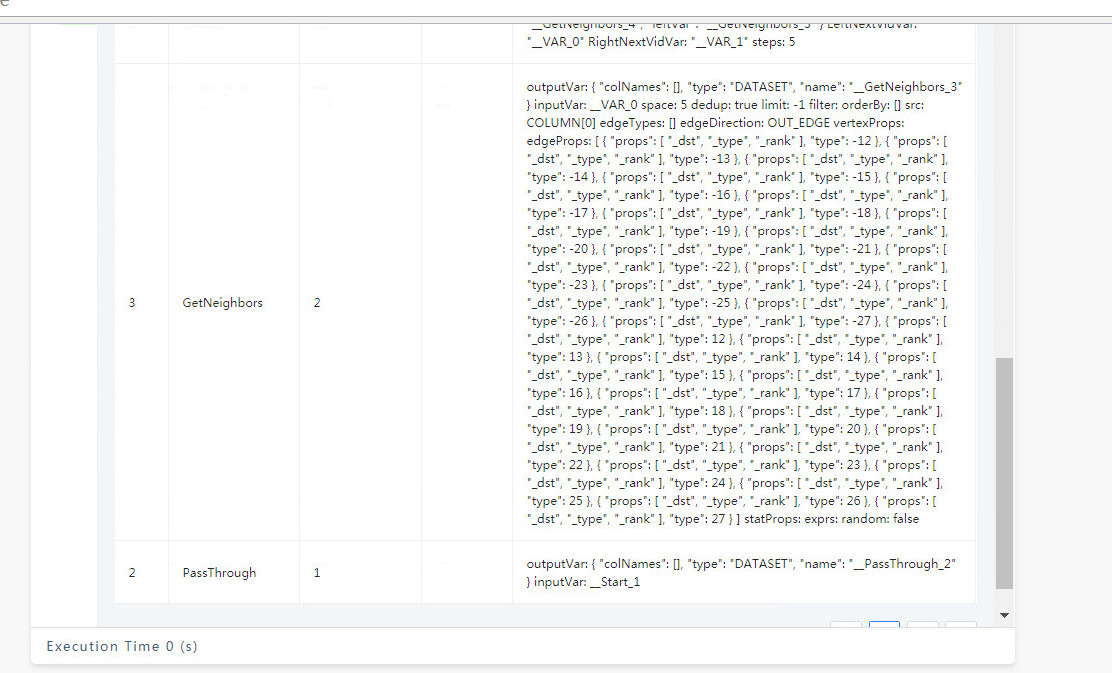
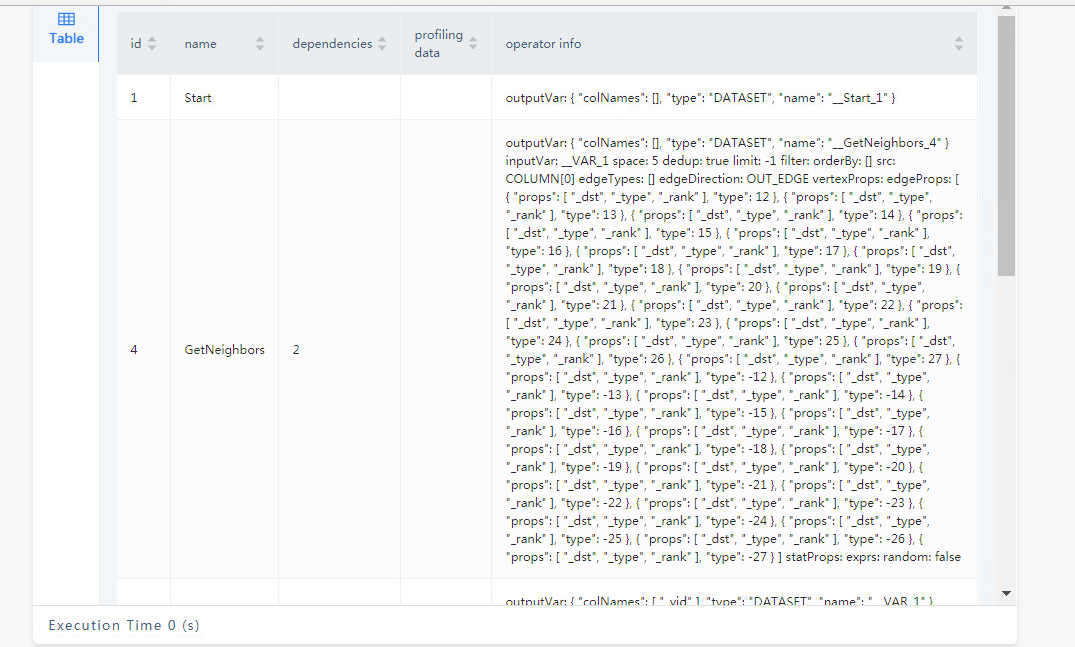
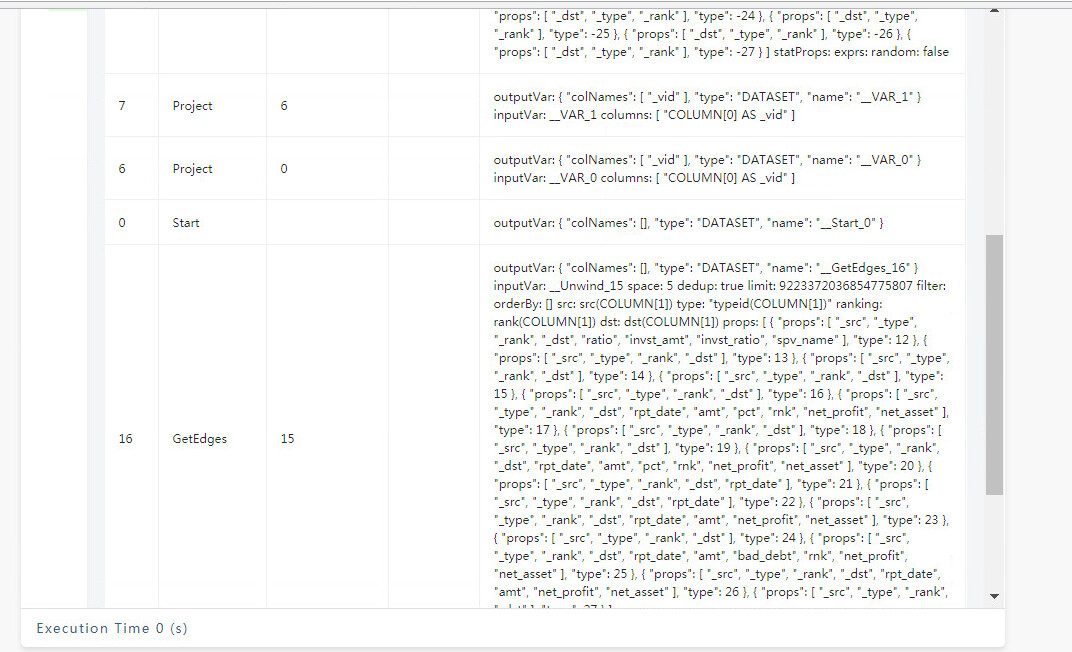
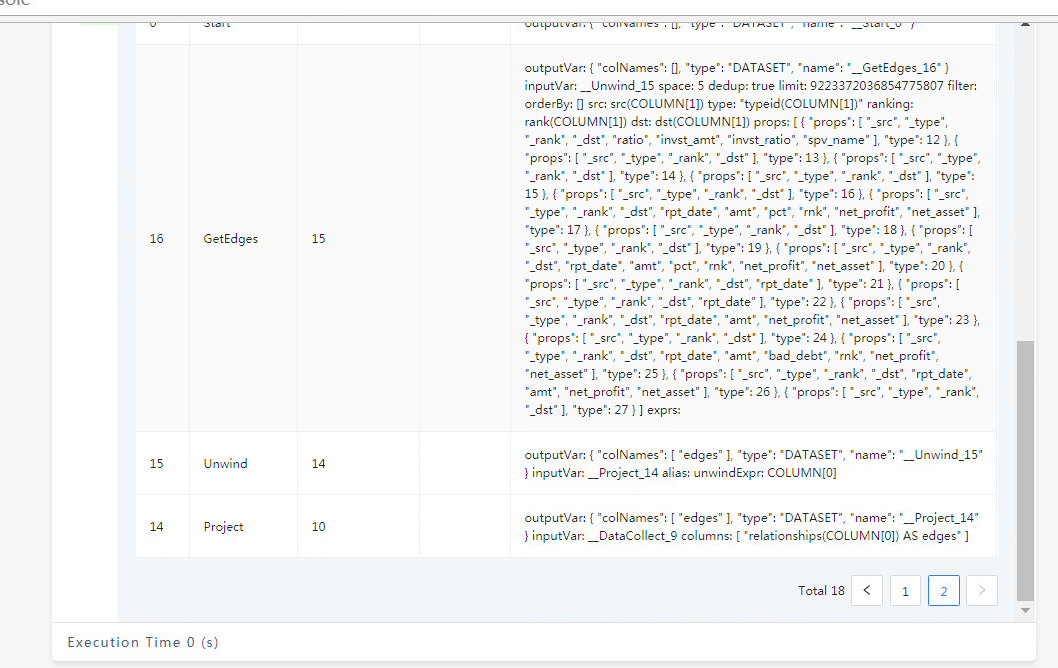
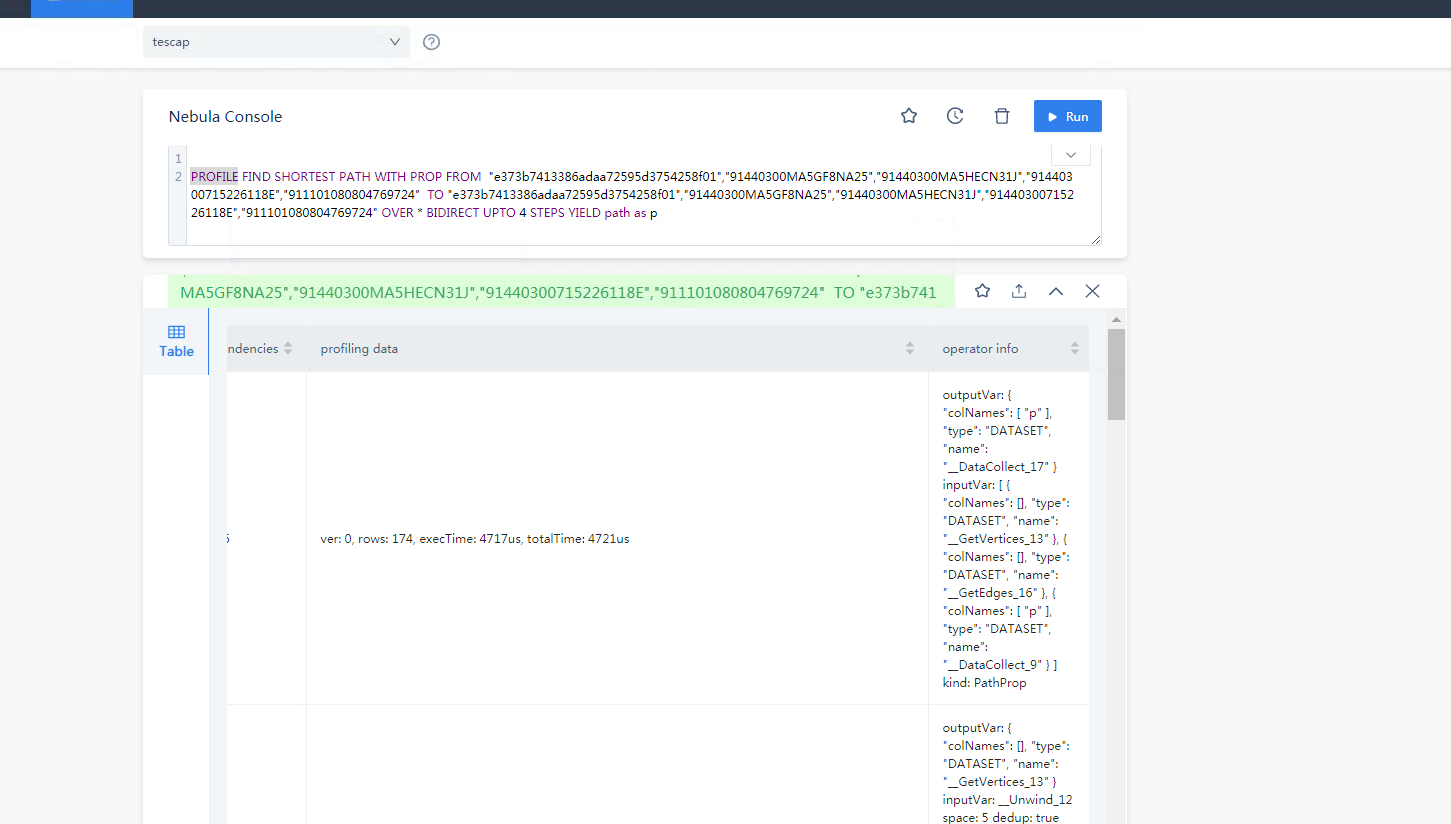
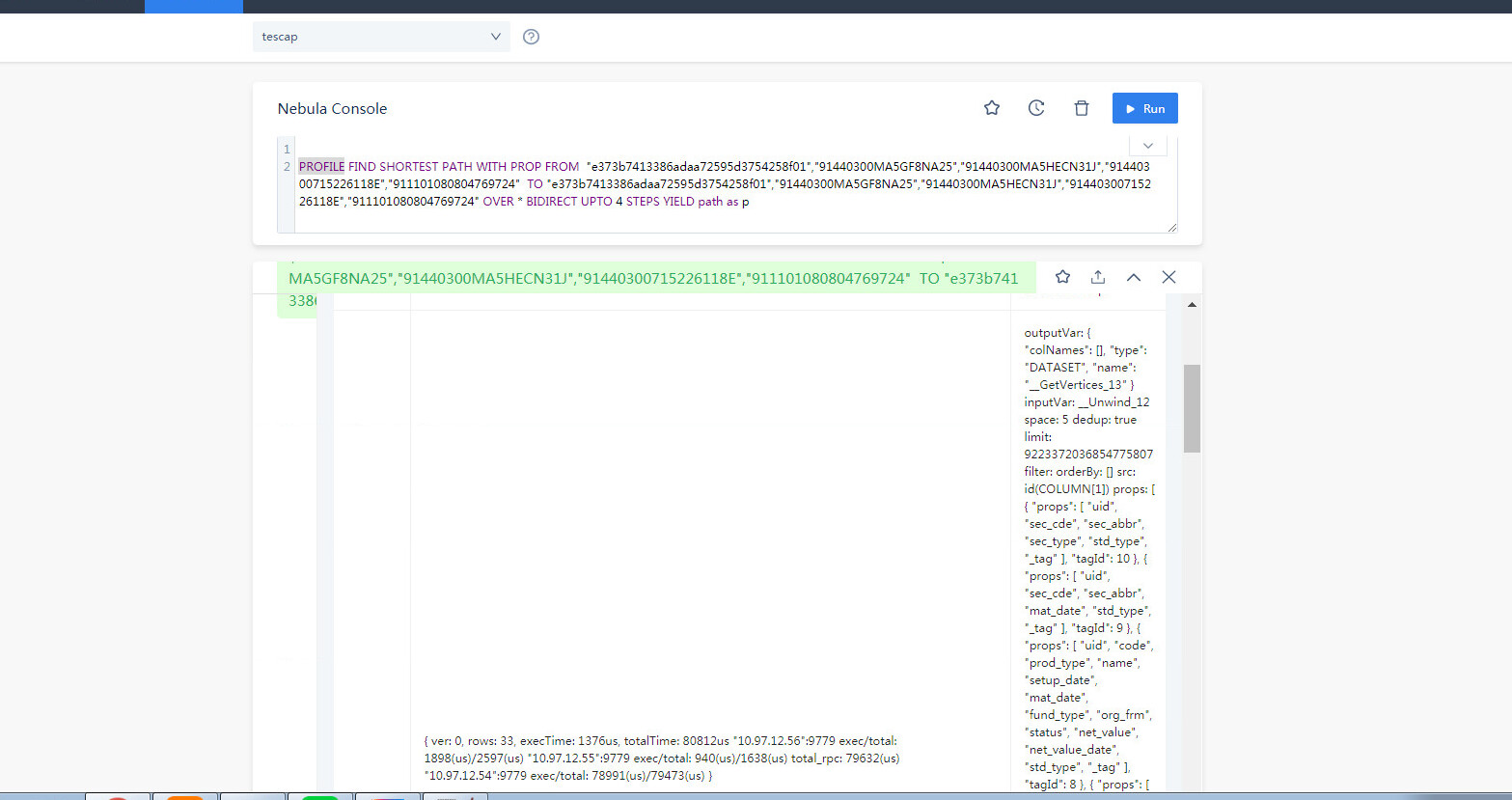
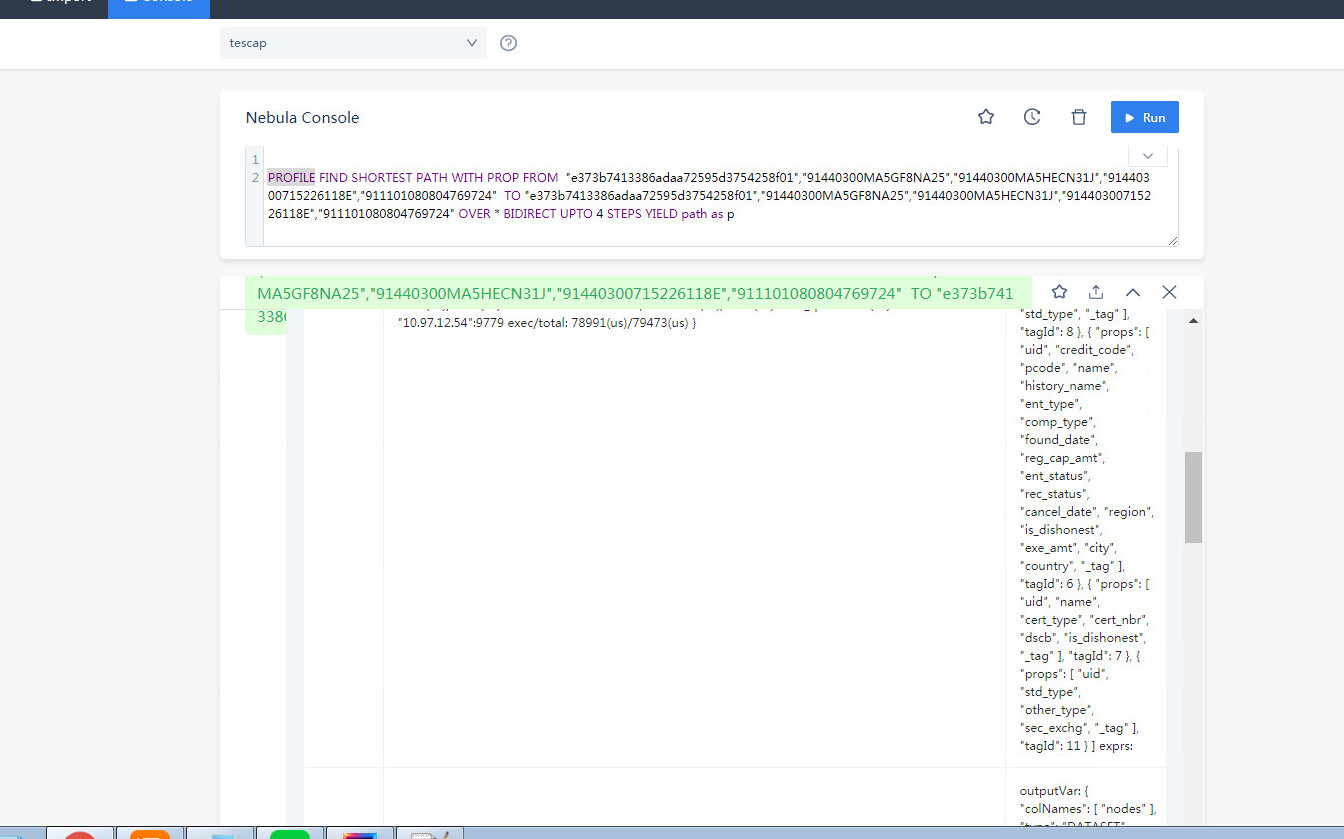
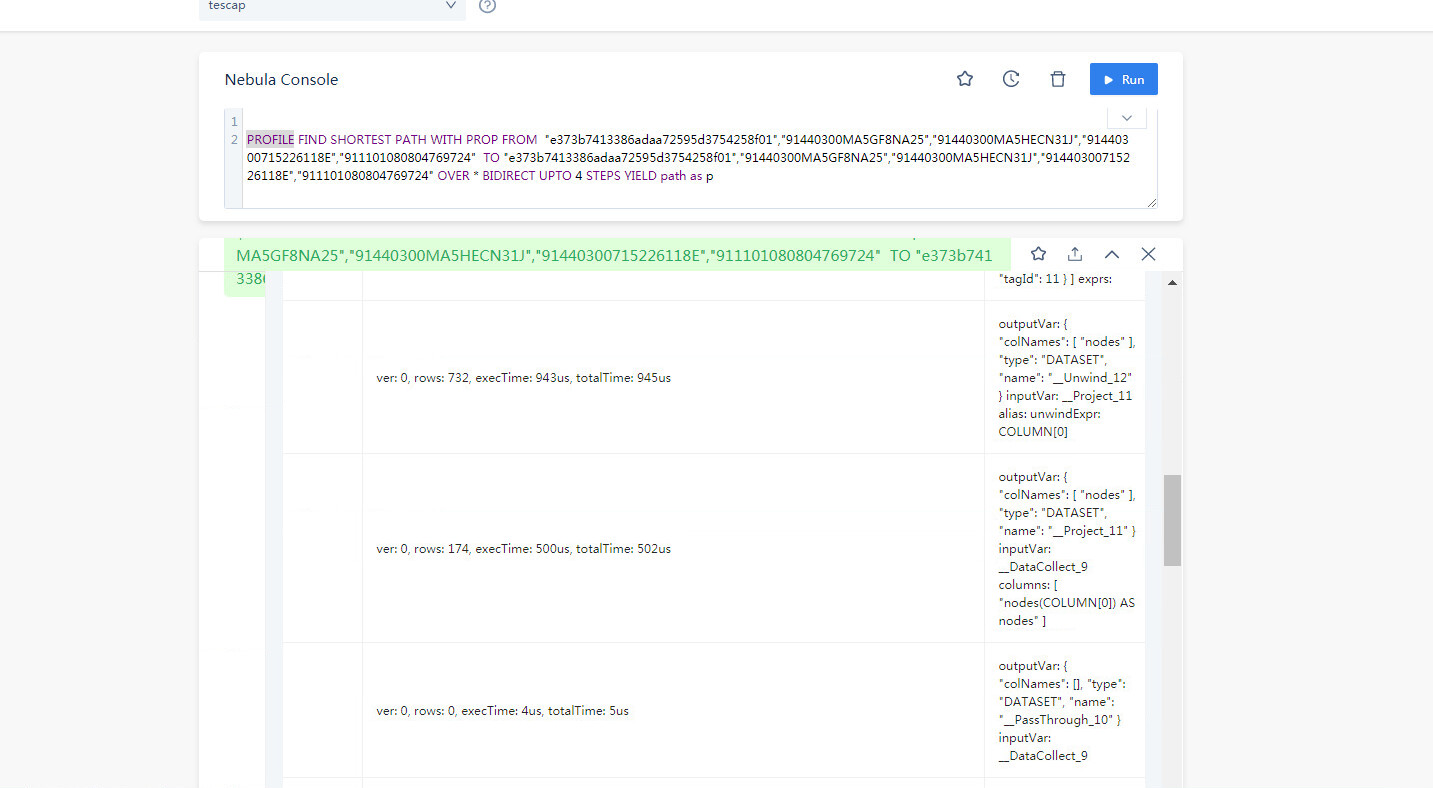
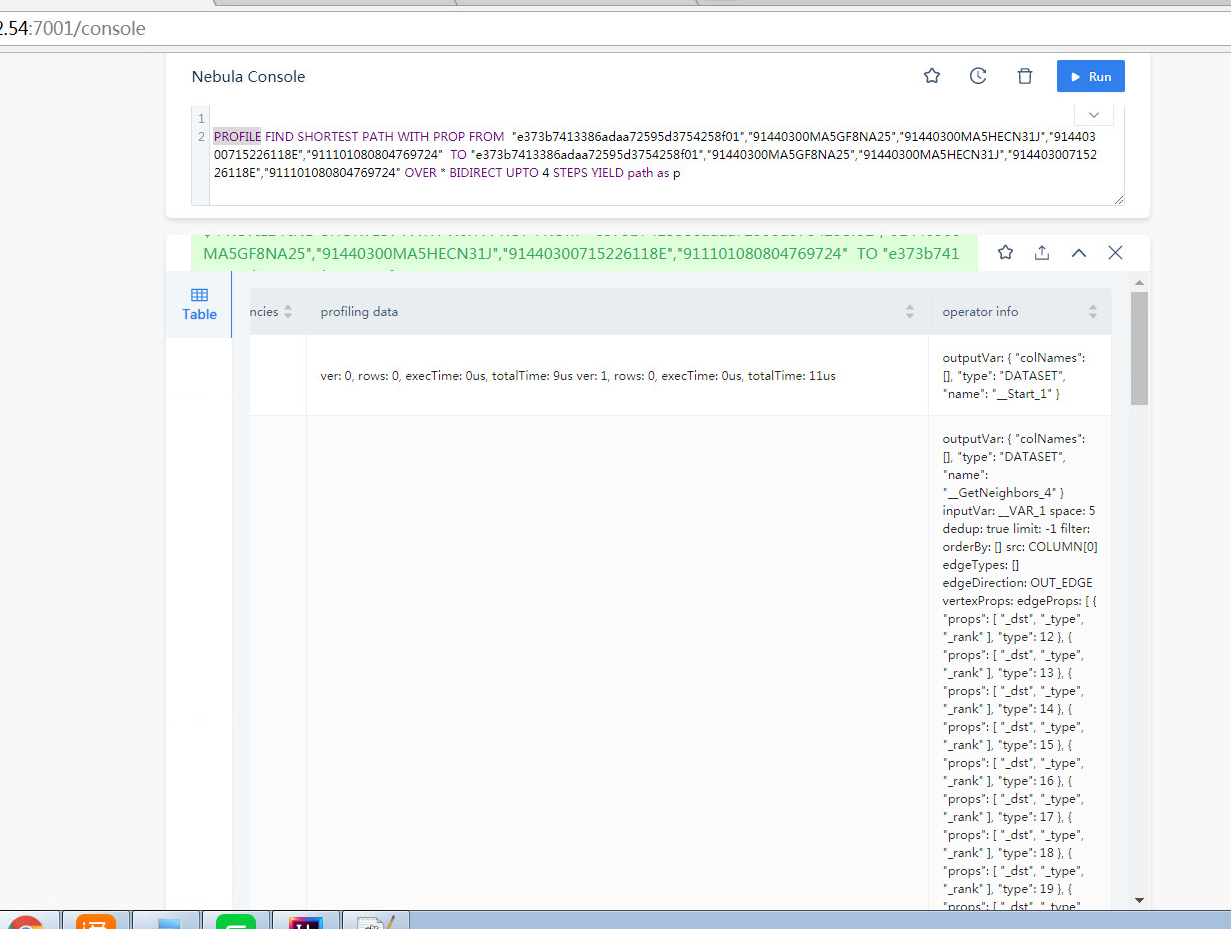
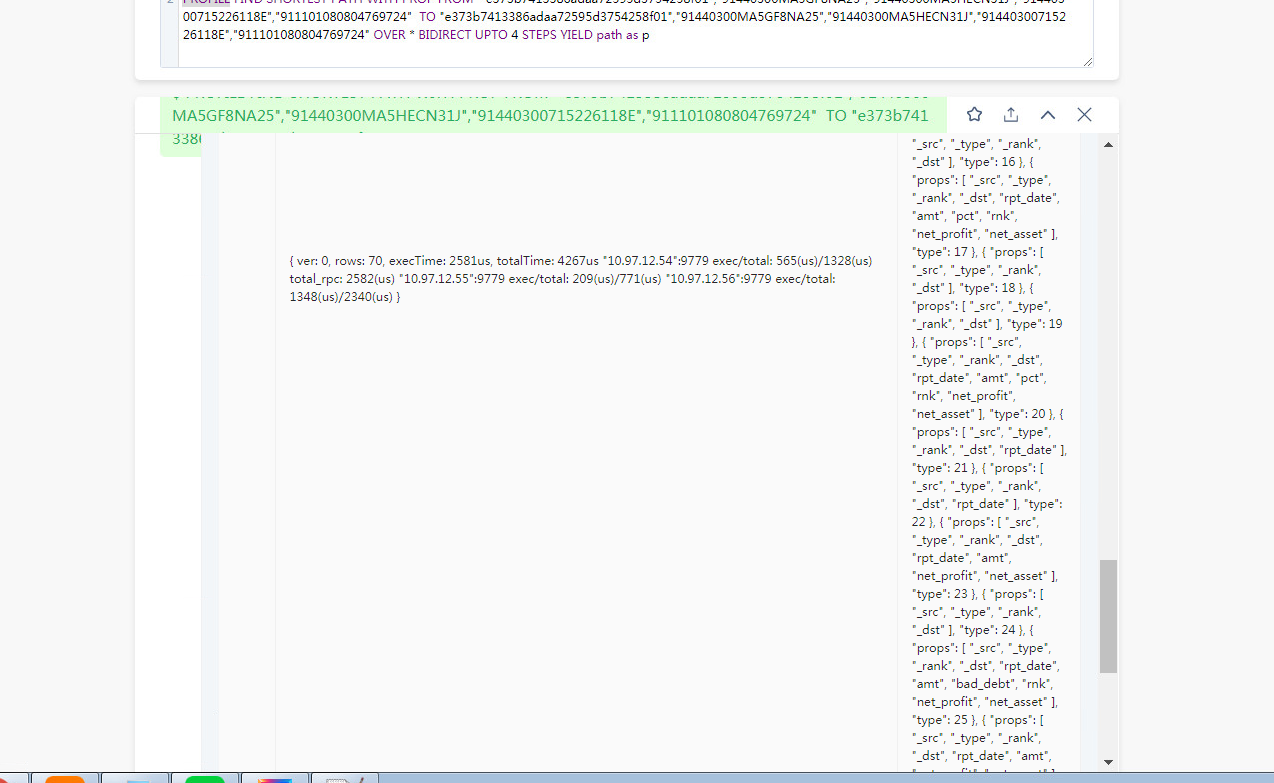
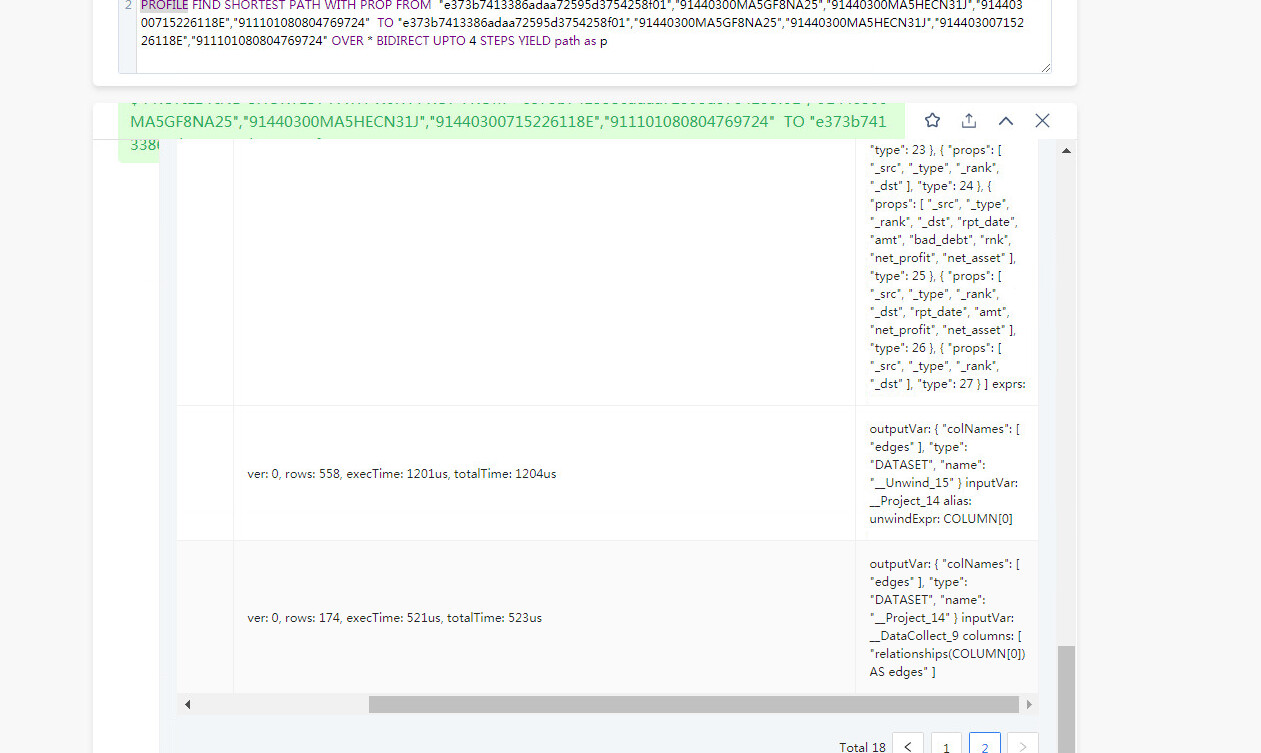
FIND PATH 是从两端向外拓展的查询,在有些联通度大的图上,5跳的查询是能几乎覆盖全图的,所以内存占用会比较大,你可以分享你的查询的 PROFILE 结果看看(如果查不出来,减小一度)。
比如在命令行 console 里边
:dot profile.log
PROFILE FIND PATH xxx;
然后把当前路径的 profile.log 贴上来
才看到你是 vertex_list 的,这个数据量是很大的,因为 5 个点,两两组合就有十对起点终点(C52 = 10),十对起点终点探索、所有类型边双向5步,很容易就是好几倍的全图数据了,你可以 PROFILE 看看哈。
另外,还有一种可能如果不是均匀地联通度高,而是存在少数超级节点,这样的话可以考虑阶段超级节点的扫描(不过这本质上牺牲了正确性),截断的方式是配置 max_edge_returned_per_vertex 可以搜索一下论坛和文档里哈。
这种情况会造成我们一共有30g可用内存,但是我们明明总数据量只有500m 也撑不住吗?
嗯嗯,老师 我先试试 profile
这是十个两端的拓展,每一个都是独立的,所以数据在内存里是重复的,如果是十份的全图数据的话,很容易炸掉,另外,一个 query 目前是在一个 graphd 里的,不会分布在多个 graphd 上
哦哦,那老师,如果我想要查出来的话,目前有一个需求是 要求1个起点20个终点,他们互相之间的最短路径,也就是21个点互相之间的最短路径,那么如果是这样,我能做的是加内存吗?如果是加内存的话,我需要怎么知道我到底需要多少内存呢
而且测试环境是500m,但是生产环境的数据量是60g,因为我需要处理生产的这种全部点边的21个点之间的最短路径,有什么很好的办法去看一下我需要多少内存来做这件事没,而且还有就是,假如遇到了超级节点,我应该怎么找到它呢
老师,这个cgroup 是?我没太了解这个,这个是什么手段呀
老师,您说的这个,max_edge_returned_per_vertex 这个截断,是指的是对于超级节点只查询部分数据吗?
嗯嗯,就是一个点探索出去的时候,一个点超出这个数量边就不扫了。
这是 linux 里的 control group 机制,你可以忽略,只是能让你 ssh 不收影响,之后用 nebulagraph 自带 mem tracker 可以规避
嗯嗯,明白了