我们现在业务上有一个需求,普通的关系型数据库没有好的解决方案,所以想考虑使用一下图数据。
我们的需求是这样的:
现在我们需要对数据进行聚合统计。
比如 从某个节点开始,遍历到它所有的下级。 统计一段时间以内所有节点产生的订单聚合信息(总额,数量或者其他)。
这是我们一个比较简单的需求。 我现在对NebluaGraph 的了解是,你们的产品可以支持大量的节点和关系的查询。
1 个赞
wey
2023 年1 月 12 日 02:31
2
如果是单点出发的多跳查询,都算是比较 graphy(偏图的)
把少数点出发向外跳转返回结果的查询(如果数据主库上 hold 不住)放到图库上是最典型的选型场景。
NebulaGraph 擅长处理总量千亿点、万亿边的数据,这也是为什么很多大厂选择 NebulaGraph,好处就是不用担心未来业务增长一两个量级,图库这层需要换方案。
不过实际的情况下,平均起来点之间的连接程度(比如平均点的度)对于具体查询的表现可以差很多,如果不加以条件过滤、剪枝,稍微连接紧密一点的图上,很少几跳就可以覆盖全图数据了。
从你的上下级的需求看,我不认为一个查询会覆盖全图,初步推测是没有问题的,当然,做 PoC 去验证是最能回答你的问题的。
你可以从数据建模、导入、到业务 query 的撰写开始,在 NebulaGraph 社区一点点讨论着搞起来试试哈,NebulaGraph 社区非常欢迎和你一起研究怎么满足你的需求,或者甚至最后发现不适合(比如实际上是非图的 query pattern、需要图计算平台的 AP 场景),也许还能给出其他方案的建议。
1 个赞
好的,非常感谢您的回复,后续我会实际搭建数据库去试一下。
另外我重新回顾了一下我的问题,可能有些地方描述的不是特别好。
我重新描述一下问题,一共有两个问题。
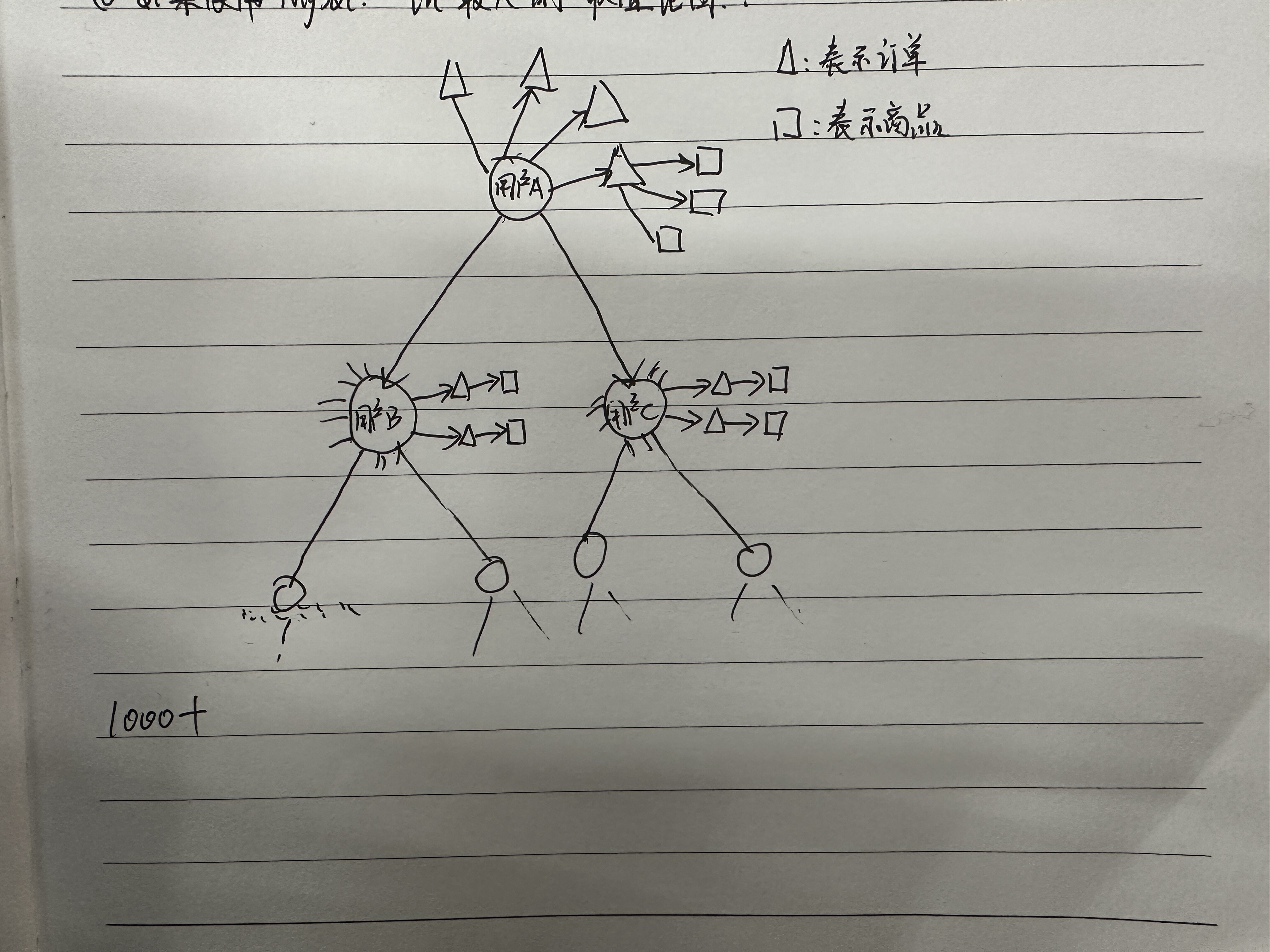
我们的实际需求是,从二叉树的顶点出发,查找 顶点到二叉树下面所有子节点(深度 1000+)路径节点产生的订单总数,以及金额统计? 图数据库是否能有效支持?
第二个问题
定义 tag 用户
每生成一个用户,新增用户到 上下级关系网。
这种建模方式,是否能适用于我上述的这个查询需求?
取子树那里GO应该会比较快,用where来做个剪枝
可以试试,挺好玩的场景。
好奇问下为什么会有那么深?是上下游推荐这样的金字塔嘛?
如果是单纯的上下级DAG还好,如果你下级有个回环到某个上级,这里路径去重的计算量就很大了。
1 个赞
嗯,对的。业务是直销的业务模式,用户上线级关系是典型的金字塔关系,且关系没有回环。关系也特别简单。
按照您这边的说法,我可以去尝试了。非常感谢
你好,我按照您这边的说法,试了一下,但是查询效率很差,可能是我哪里的写法有问题
第一行 我取的是 节点 B11511111 这个用户子树下的所有ID。 大概数量有56800个。
查询时间大概3S 左右。 我的数据库服务器是8C16G的配置。
请问有什么办法可以优化吗?
试试把properties($$).prop 换成 $$.tag.prop的形式
非常感谢。确实 起作用了,查询原来时间是3秒,修改以后变成了1.9秒。
但是与我预想的差距还有点远。我希望毫秒级的处理完成,还有改进空间吗?
min.wu
2023 年1 月 16 日 04:07
12
storaged有个配置参数,你可以手动加上试试。
1 个赞
不好意思,3.3.0版本的文档,没有找到 query_concurrently 这个配置
感谢,这个条件加了以后 又快了0.1秒
min.wu
2023 年1 月 16 日 07:21
19
我看profile的大头是 GetDstBySrc 每次要2ms,然后要跑1000次?
嗯,查询语句有点问题,我重新写了一下。
按照你这边的要求,我加上了 多线程查询的参数 query_concurrently=true。效率确实提升了1倍。
现在查询时间为1秒左右。
但是这个时间太长,还达不到预期的结果。
这个是优化过后的查询语句
go 0 TO 10000 steps from "B11511111" over develop yield id($$) as id |
go from $-.id over buy where $$.czt_order.payment_on < datetime('2023-01-07') and $$.czt_order.payment_on > datetime('2023-01-01') yield $$.czt_order.total as price |
yield sum($-.price)
这个是profileresult (1).csv (153.7 KB)
min.wu
2023 年1 月 16 日 08:18
21
存储计算分离好像不适合这种非常深度的场景