目前为止在nebula中不支持一个属性具有多个值的list存储。在我们的应用场景中,需要分别录入多批次数据,其中不同批次数据使用唯一id进行数据融合,但是不同批次数据中同一个属性(比如姓名)值可能不同,我们在具体使用中需要将同一id及属性对应的属性值都进行存储,比如由于拼写错误,不同批次的同一个人的姓名可能采集成多个,我们需要将其记录为同一个人的姓名。
在之前使用的dgraph中,该情况的不同属性值可以使用list存储,但是nebula不支持list,请问nebula应该怎么支持该种场景?在具体场景中数据规模较大,如果使用自旋边,由于不确定哪些属性具有多值,所有属性均需设计为自旋边,且自旋边的rank无法提前指定,需使用代码每次生成,速度较慢,违背使用nebula快速入库的初衷,请问有什么好的方法解决这种一个属性多值问题吗?
1 个赞
wey
2
想知道被合并的属性会成为图的访问条件么?比如 tagFoo.name:list[] , 会有 WHERE "foo bar" IN tagFoo.name 这样的过滤条件作为查询起点么?
另外合并是应用层批量的 get and set 么?
如果没有过滤这些复合属性作为查询起点的情况,都是典型的给定 vid 做图拓展,然后属性只是作为返回值(或者拓展过程中的条件过滤),可以考虑利用字符串属性,存成 map/json string,读查询的时候用 json_extract 是可以解析的。
json_extract 主要的限制是不能用在查询的起点,因为需要扫描所有的数据
wey
3
另外就是,可以根据你最终图访问的模式,从图建模角度考虑怎么实现。
比如同义的部分能否用不同的点来表示(当然这也会改变查询的模式),要看看取舍是否值得
使用场景的一个例子是: 身份证号为“123”的用户,在表1其姓名为张三,在表2其姓名为张二,在具体使用时可能需要进行“扩展姓名为张三的人的关系“这样的查询,但是比如姓名这一属性仅仅是基于id的展示以及查询,我们在统计用户属性时,包括姓名、性别、年龄等属性由于数据识别错误都可能有多个,都需要保存于图谱中,请问该种情形应该如何存储?如果使用不同的点表示同一个人的不同名字感觉有点奇怪。
考虑过在 workflow 里面加入一步数据清洗吗?把错误的数据按某种规则处理一下,比如姓名统一以最早的数据为准等等。
1 个赞
这个比较恶心的是我们的 数据有可能是手动录入的,不能排除错误数据,一般我们会生成一个来源表记录该条数据的来源,另外比如一个人有多个曾用名 ,也需要使用list的方式来记录曾用名
list 做属性目前确实不支持。针对数据有错误的问题,还是建议正面解决数据错误。可以考虑设置一个曾用名属性,里面通过字符串拼接的方式存储所有曾用名。如果插入数据的时候发现名字有冲突,就把新的名字更新到曾用名里面去。最后定期执行任务去处理所有的曾用名,按照某个规则给它清洗一下。
谢谢您的回答,就是这样操作的时候如何发现名字有冲突,为了追求入库速度一般都是直接把原始csv等文件直接入库,而且每批次的数据都比较大,这样插入数据的时候如何发现名字会有冲突,而且发现冲突如何在入库过程中进行拼接,这个没想明白
一个最典型的示例,我们会从网上爬取新闻进行抽取分析,特定人物可能有简体姓名,同时可能有繁体姓名,他们对应的公司都是同一个,因此为了分析方便,在抽取完成后都应该入到同一个人物tag中,在这种情况下请问有好的存储方式吗?
还是一样的建议,内核数据结构没有很适合你这里需求的方式,还是要直接处理数据错误。如果是在线手动输入的,对吞吐量的需求应该不会很大,可以在链路上做一些查询和判断逻辑判断冲突。如果是离线异步导入,比如从 csv 往数据库里面导入,最好是加一步数据清理,清理一下 csv。
1 个赞
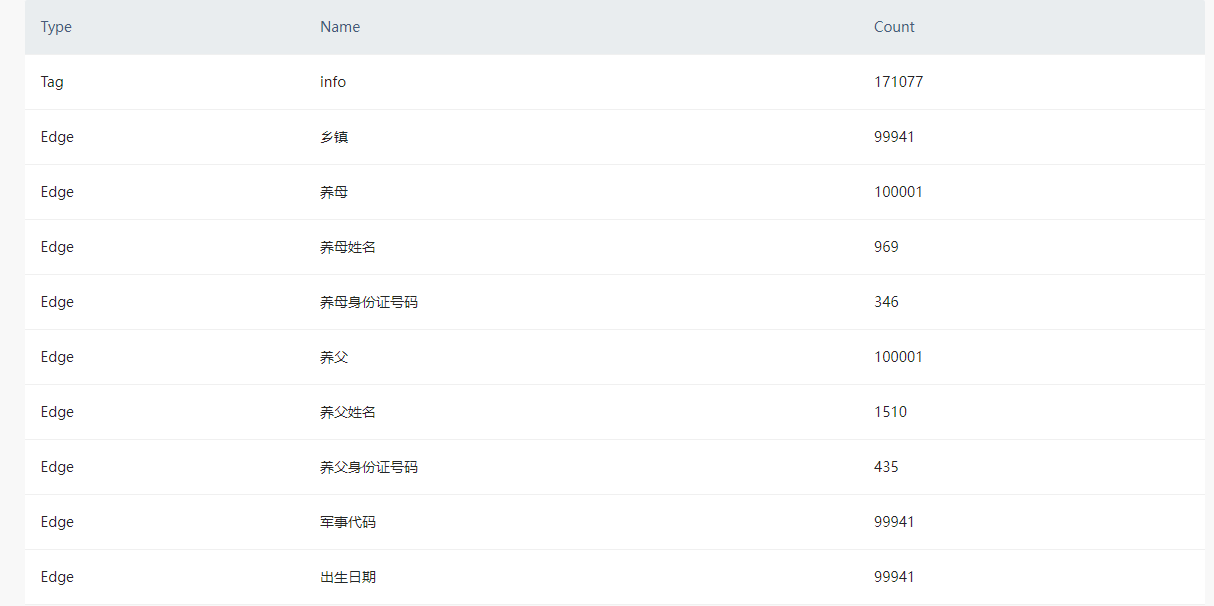
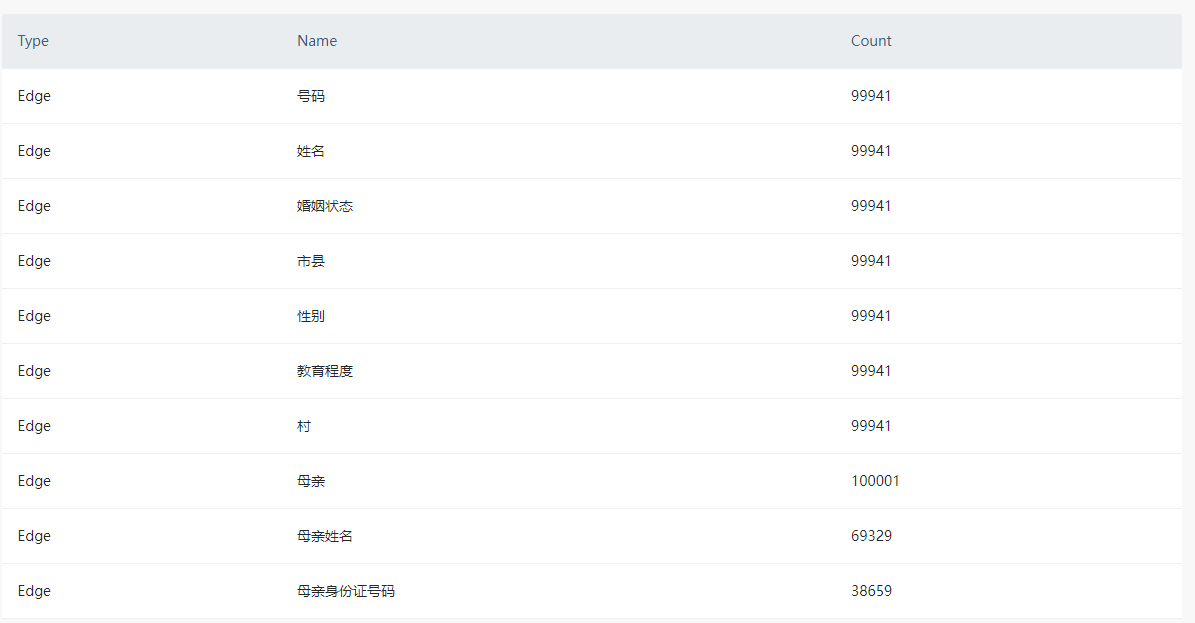
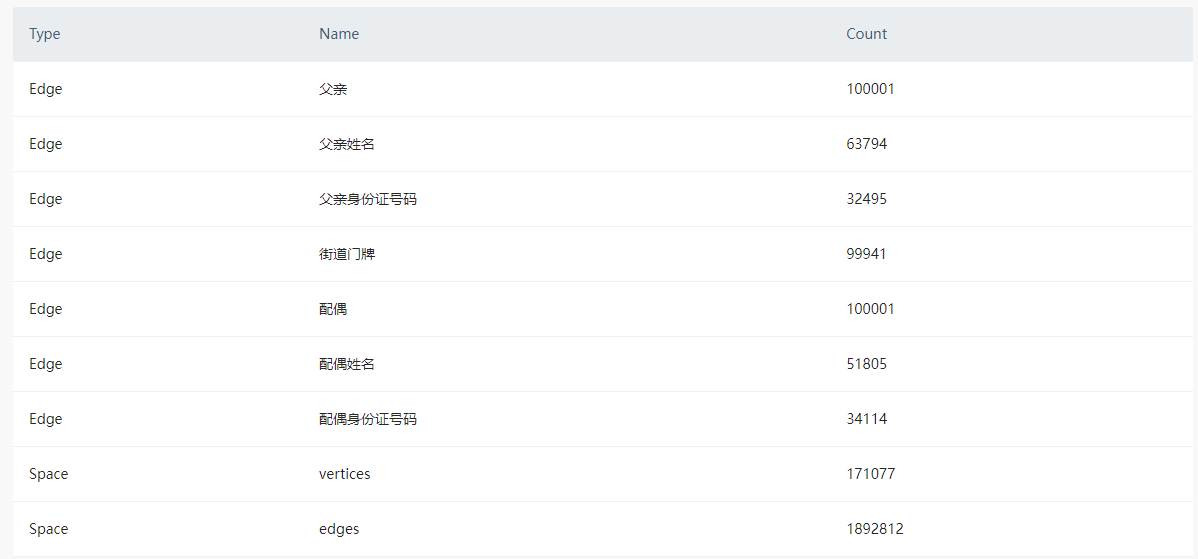
我们有一批数据,原始大小40.5M,有59个列,共10万行数据。我们把其中38个列每列单独拆分成一个自旋边,并且导入的时候同时给每个自旋边关系指定各自的rank列,导入时数据膨胀到1.27G,导入速度为94s,想问一下采取什么方法能提升一下导入速度呢?
spw
17
使用场景的一个例子是: 身份证号为“123”的用户,在表1其姓名为张三,在表2其姓名为张二,在具体使用时可能需要进行“扩展姓名为张三的人的关系“这样的查询,但是比如姓名这一属性仅仅是基于id的展示以及查询,我们在统计用户属性时,包括姓名、性别、年龄等属性由于数据识别错误都可能有多个,都需要保存于图谱中,请问该种情形应该如何存储?如果使用不同的点表示同一个人的不同名字感觉有点奇怪。
拆成点不奇怪呀,如下建模:
(唯一标识:身份证号)-[身份]->(身份1: 姓名,年龄等信息)
|-[身份]->(身份2: 姓名,年龄等信息)
spw
18
这些点和边为什么拆的这么细碎?可以将属性进行下分组,放到 Tag 和 Edge 里?会节省一些空间,比如,可以设计以下点:
- 人(姓名,性别)
- 行政区(省市县)
- 具体地点(街道)
边:
- (儿女:人)-[:父亲关系]->(父亲:人)
- (儿子:人)-[:母亲关系]->(母亲:人)
- (丈夫:人)-[:配偶]-(妻子:人)
- (儿女:人)-[:养父关系]->(父亲:人)
- (:人)-[居住于]->(具体地点)
- (具体地点) - (从属于)-> (行政区)
我理解的拆的比较碎是因为每次入数据时不知道是否重复,如果为了查询是否重复再询问则时间花销更大
而且之所以拆是因为入库分多批次,无法提前知道有多少数据的属性存在多个,如果拆成点那入新批次的数据之前是否需要将新数据在nebula中进行检索,排除相同的再入库,如果有新的属性也应该重新更新schema?