你的maven什么版本? 如果太低 建议升到3.6试试
maven是3.8.7
你发一下执行打包命令所在的目录吧, 在当前目录下ls看一下
我是在windows环境下安装的- -想编译了直接把jar拷过去
我们在mac和centos下都正常,github action里面打包也ok,不知道和系统下的编码有没有关系
你试下这个帖子中的说法,把子模块中的groupId去掉[ERROR] Could not find the selected project in the reactor: xxx.xxx:xxx @_tag心动的博客-CSDN博客
直接下jar包,然后按照文档示例
${SPARK_HOME}/bin/spark-submit --master “local” --class com.vesoft.nebula.exchange.Exchange /root/nebula-exchange/nebula-exchange/target/nebula-exchange-3.4.0.jar -c /root/nebula-exchange/nebula-exchange/target/classes/maxcompute_application.conf
直接运行可不可以呢
可以啊
老师们下午好,直接下载jar文件部署成功了,但是在提交命令这一步报了这样的错。
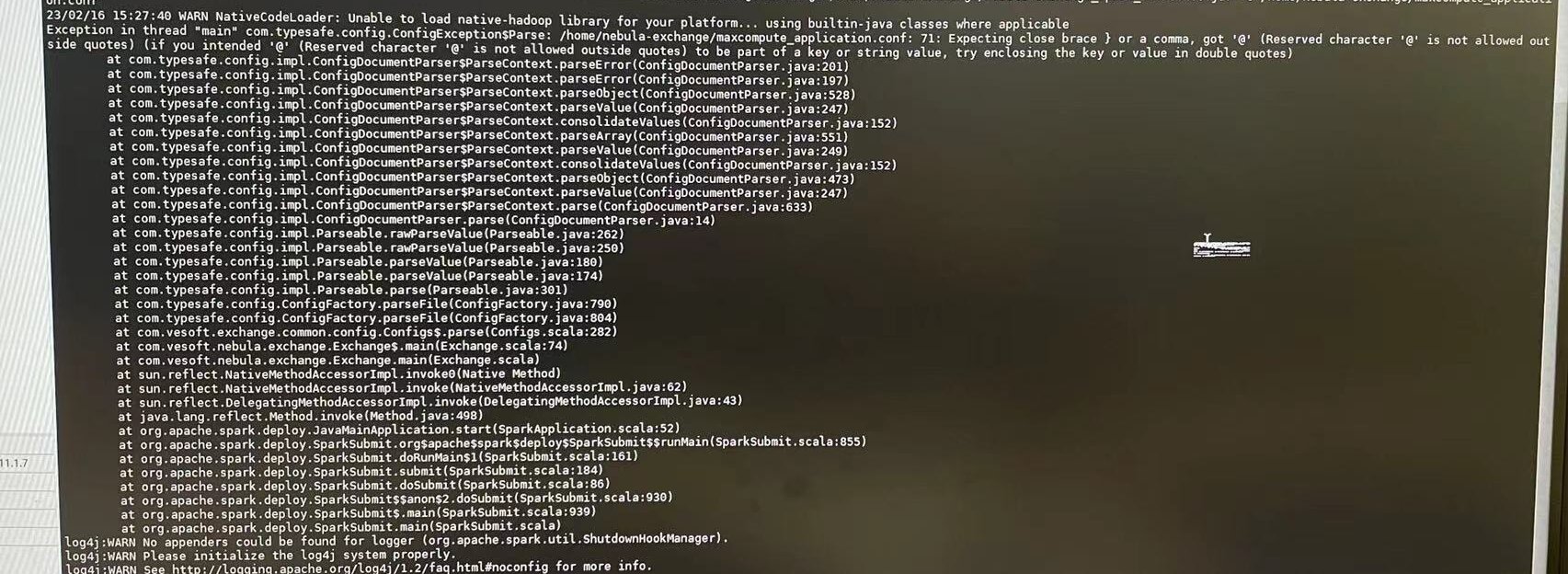
Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
Exception in thread “main” com.typesafe.config.ConfigException$Parse: /home/nebula-exchange/maxcompute_application.conf: 71: Expecting close brace } or a comma, got ‘@’ (Reserved character ‘@’ is not allowed outside quotes) (if you intended ‘@’ (Reserved character ‘@’ is not allowed outside quotes) to be part of a key or string value, try enclosing the key or value in double quotes.
版本都和官网要求的一样,spark版本为spark-2.4.0 nebula-exchange版本为 nebula-exchange_spark_2.4-3.4.0.jar
/home/spark/bin/spark-submit --master “local” --class com.vesoft.nebula.exchange.Exchange /home/nebula-exchange/nebula-exchange_spark_2.4-3.4.0.jar -c /home/nebula-exchange/maxcompute_application.conf
提交任务的命令是这个
配置文件 maxcompute_application.conf 第71行格式不对
我更改了试了一下,通了。但是一直停在这一步,studio里看也没数据 ![]() 请老师帮看看是什么问题
请老师帮看看是什么问题
控制台语句:
23/02/17 17:32:24 WARN MemoryStore: Not enough space to cache rdd_2_0 in memory! (computed 369.9 MB so far)
23/02/17 17:32:24 INFO MemoryStore: Memory use = 29.3 KB (blocks) + 357.2 MB (scratch space shared across 1 tasks(s)) = 357.2 MB. Storage limit = 366.3 MB.
23/02/17 17:32:24 WARN BlockManager: Persisting block rdd_2_0 to disk instead.
不太懂rdd_2_0是个什么东西
rdd_2_0是rdd的一个分区, 你有多少数据量,看下有没有error日志
我有大概千亿的数据量
星期五的时候调通了,但是两天只进了1.3亿数据,不知道是哪的问题
你找下你的集群日志,看是不是任务已经重试多次后失败了
我看控制台数据是一直在更新的,数了下每秒有100多条
我感觉是哪里没设置对
任务分配了多少cores,你的exchange配置文件中partition和batch分别是多少
是不是这个 spark.deiver.cores ? 就按照文档设置的,1
partition:32
batch:256
不是这个,你把你的spark-submit命令发上来看下吧
千亿数据的规模,batch可以根据你一条数据的size来配,如果属性很少可以配成3000-5000
partition配置成你可以分配的总cores的2-3倍,cores的数量看你集群资源
命令是这个:
/home/spark/bin/spark-submit --master “local” --class com.vesoft.nebula.exchange.Exchange /home/nebula-exchange/nebula-exchange_spark_2.4-3.4.0.jar -c /home/nebula-exchange/maxcompute_application.conf
分配核数spark-env.sh里设置了SPARK_WORK_CORES为30
你咋用local模式啊,那是单并发了, 你有spark集群的话可以改一下–master的值,然后指定这几个参数,具体的值根据你的机器来
–total-executor-cores=120
–executor-cores=12
–executor-memory=10g
–driver-memory=2g \