Spark 单独安装,不过要能访问到 nebulagraph 的 graph, meta, storage 服务。
Nebula-algorithm 就是要保证 jar 包被提交、执行的时候被 pyspark 引用 到
Spark 单独安装,不过要能访问到 nebulagraph 的 graph, meta, storage 服务。
Nebula-algorithm 就是要保证 jar 包被提交、执行的时候被 pyspark 引用 到
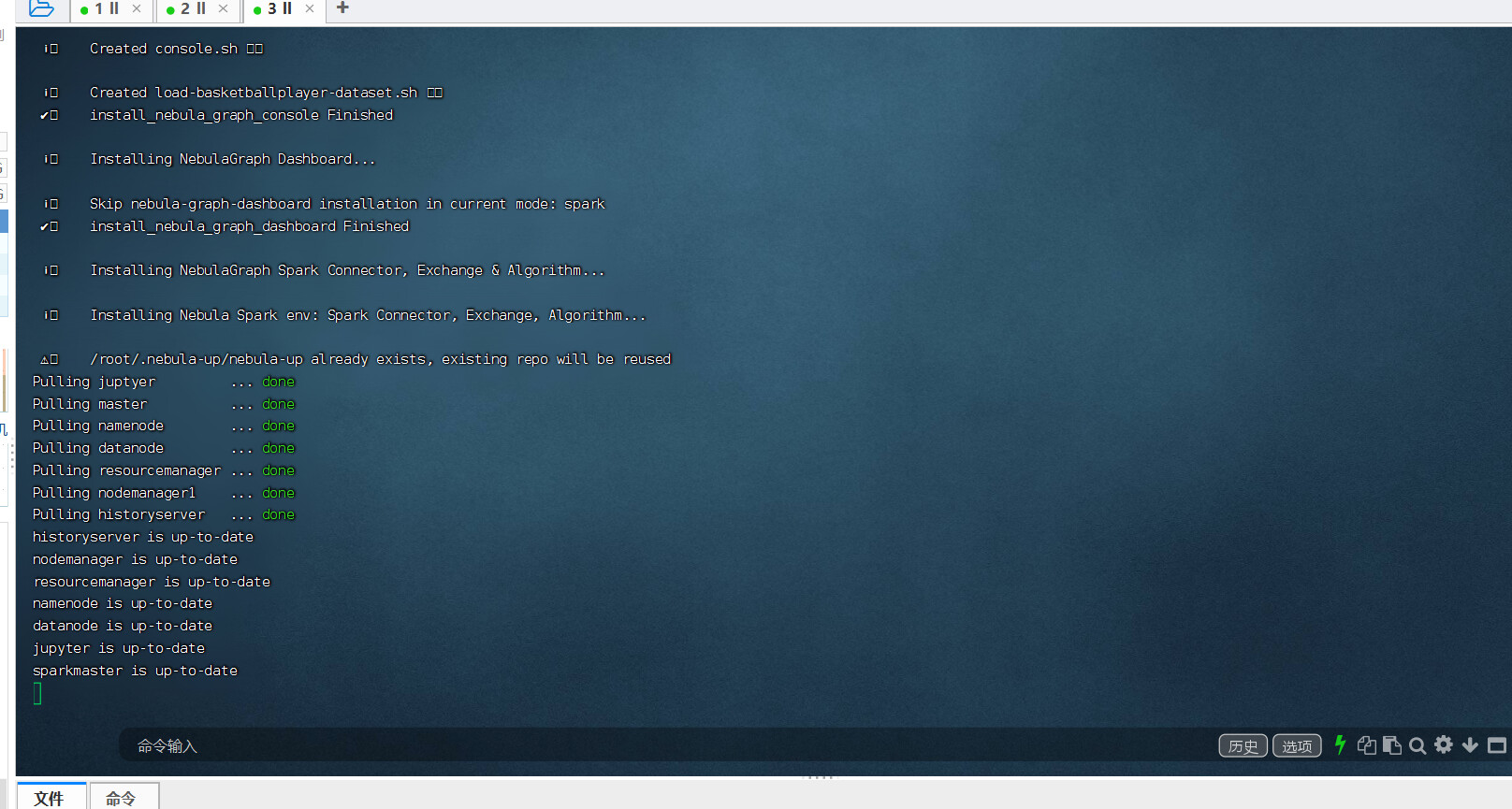
这个过程是会拉取 docker 镜像,还会拉取一个数据集(live journal)和 nebula algorithm 的 jar 包,一次要个几个 GiB 的下载量哈,跑多久了?
另外,我昨天更新了 nebula-up 你这么执行之后,会自动给你启动一个 jupyter notebook,里边一切都准备好了,里边有一个 pagerank 的 notebook 可以打开按行执行哈
notebook 就是你这个服务器的 8888 端口,默认 token 是 nebula
第一次跑有三十分钟然后我以为是网络原因手动停止了 ,然后现在是第二次执行命令有十来分钟了
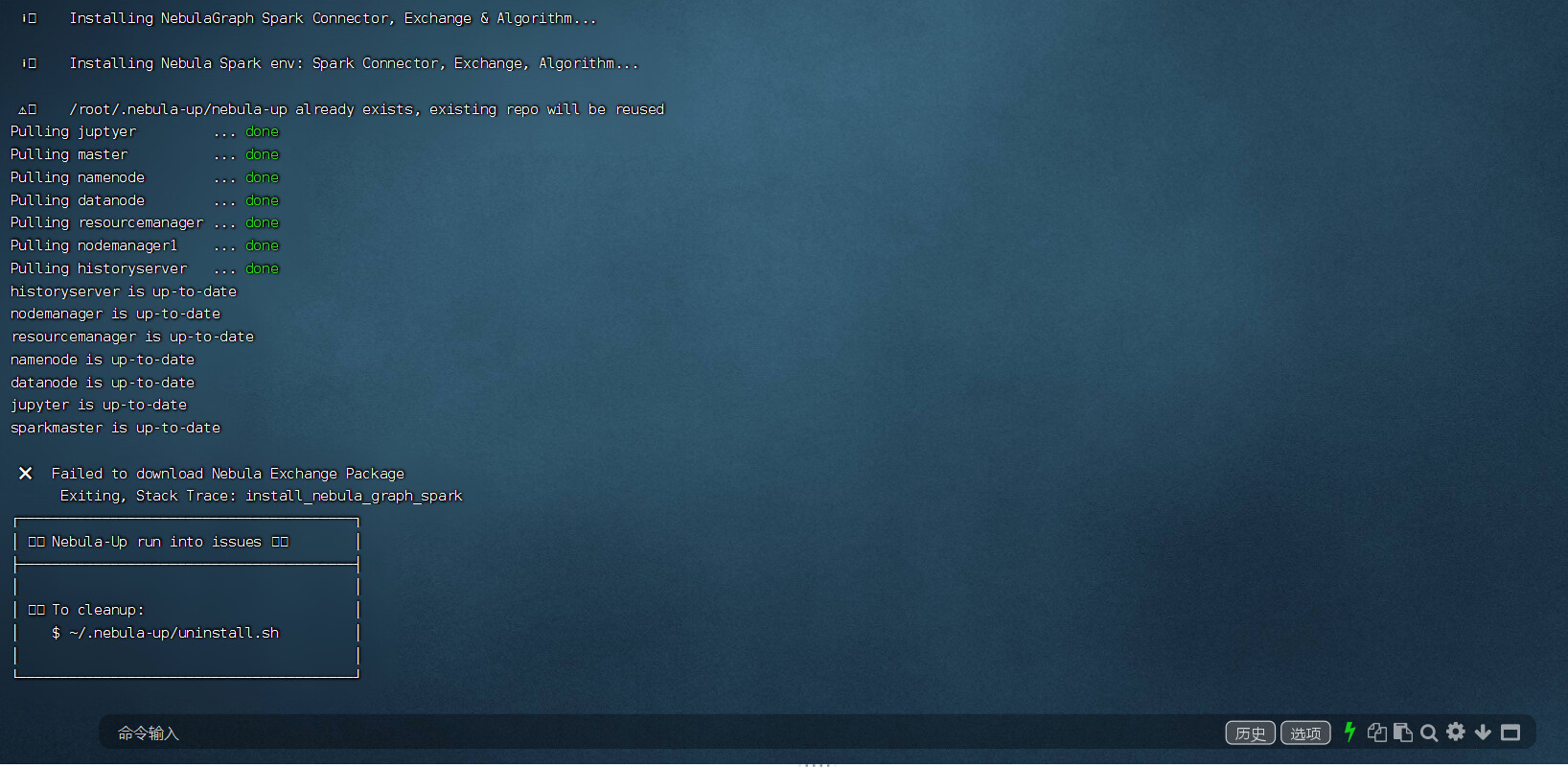
好的,可以稍微等一下,中间有 wget 的过程确实比较让人心慌(卡主)
应该是网络原因,你可以看看 执行 tree ~/.nebula-up/nebula-up/spark/ 比较一下这里边缺啥,如果 nebula-algo 在的话,可以手动执行 ~/.nebula-up/nebula-start.sh 启动,然后应该就可以继续了,不用重新安装。
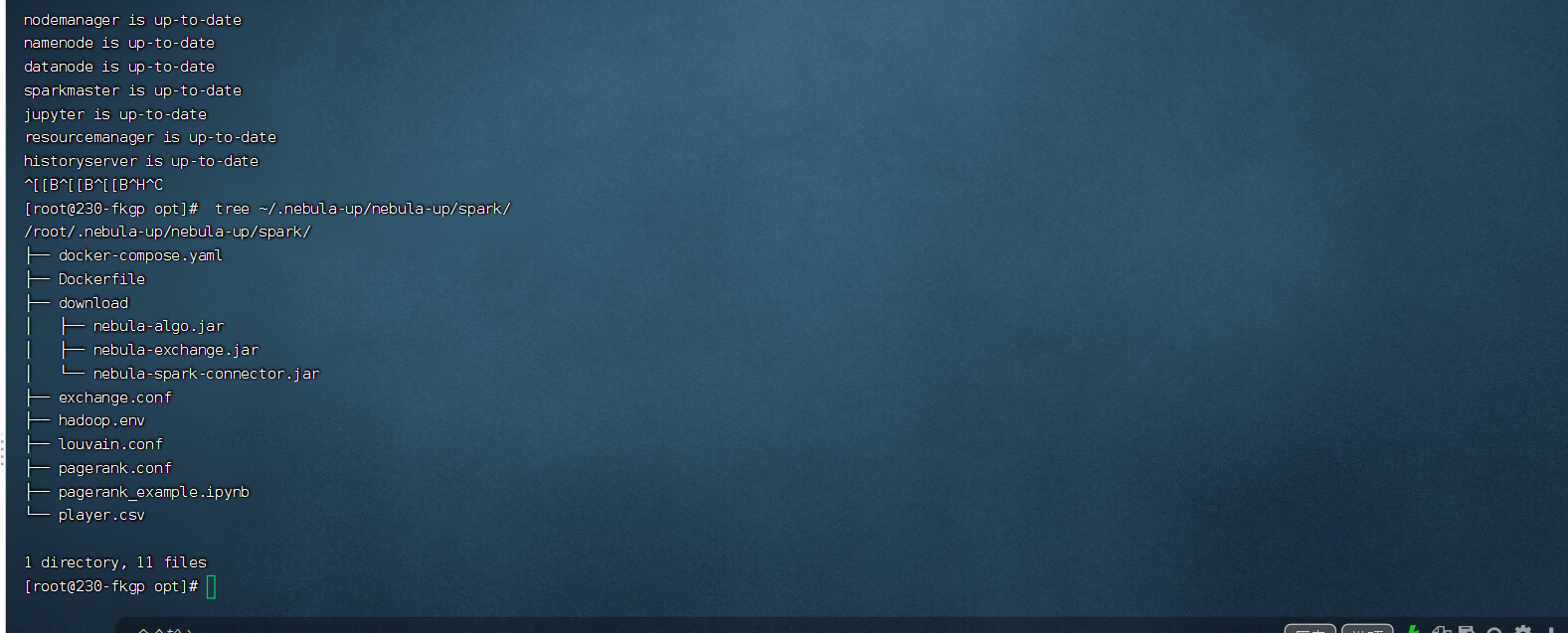
tree ~/.nebula-up/nebula-up/spark/
/home/wei.gu/.nebula-up/nebula-up/spark/
├── docker-compose.yaml
├── Dockerfile
├── download
│ ├── nebula-algo.jar
│ ├── nebula-exchange.jar
│ ├── nebula-spark-connector.jar
│ └── soc-LiveJournal1.txt
├── exchange.conf
├── hadoop.env
├── louvain.conf
├── pagerank.conf
├── pagerank_example.ipynb
└── player.csv
是 live journal 数据集,没关系,不耽误
因为安装步骤被中间下载失败打断了,不是所有的脚本都生成了,没关系,这说明你该有的都有了哈
嗯嗯,这就只是没有启动脚本,东西都全了
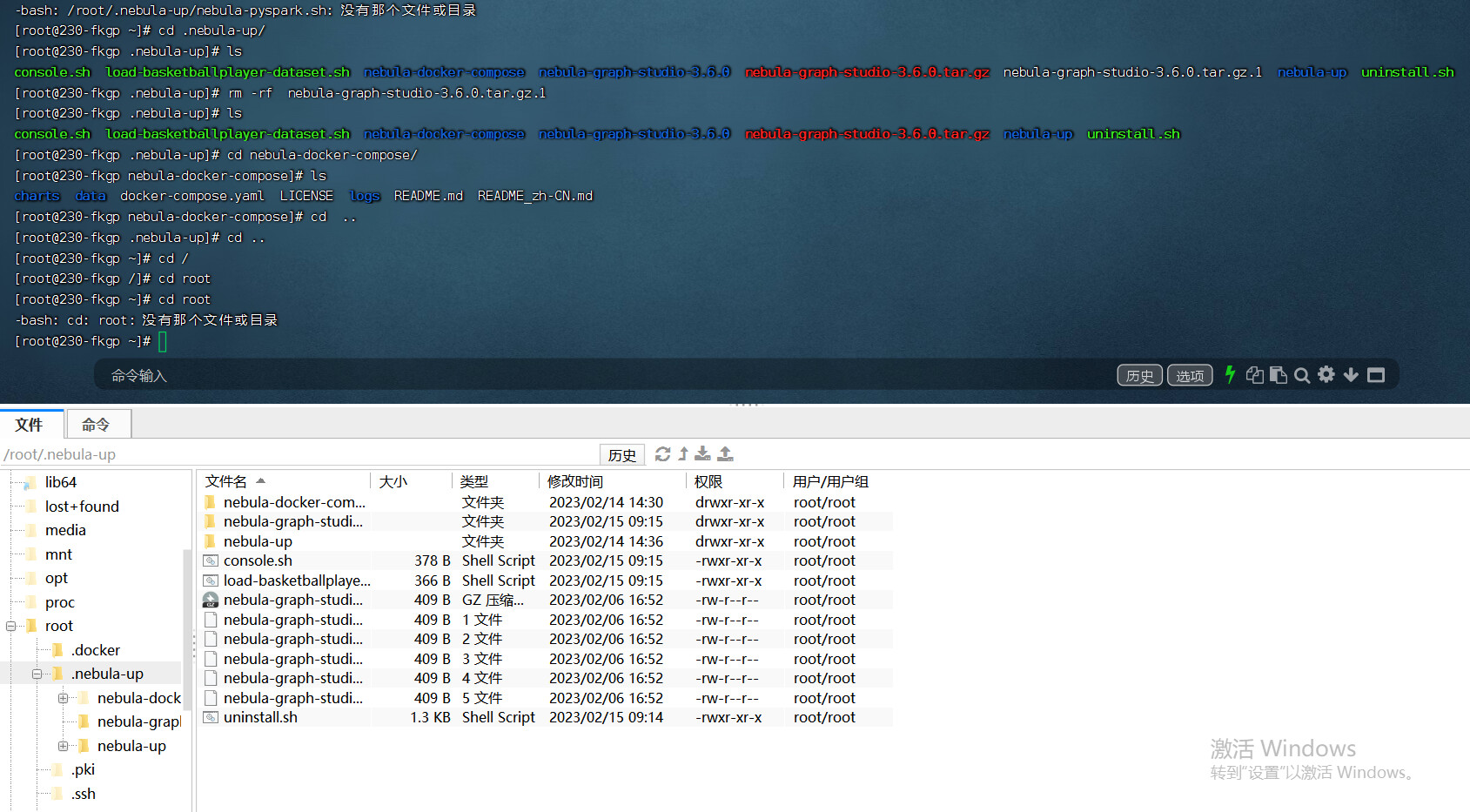
所以说不允许这个也可以
这个脚本只是进入 pyspark shell 的脚本哈
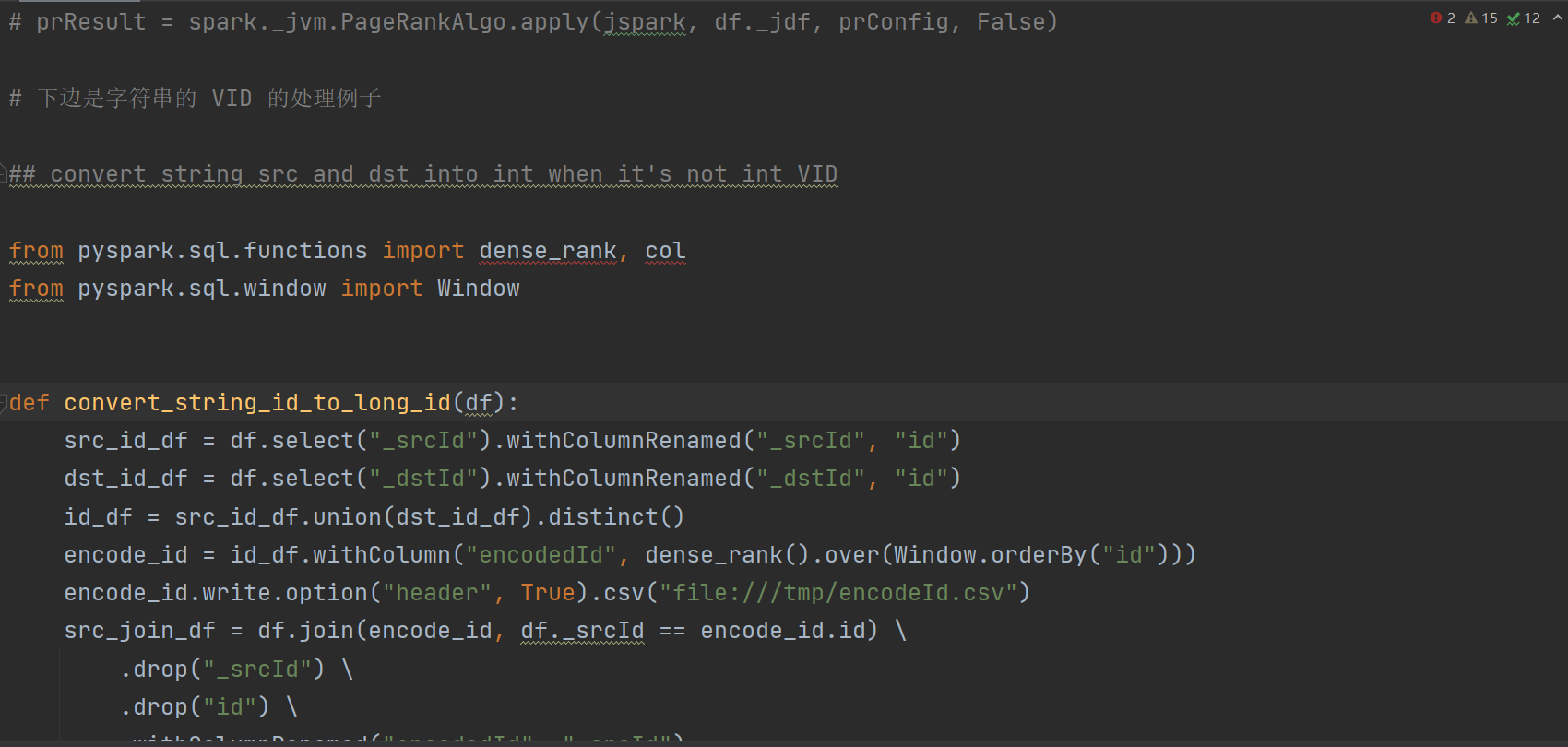
我在路上不方便试,你可以研究一下,这是一个通用的 pyspark 知识。
参考 我 spark 目录下的 dockerfile,那里边有执行 pyspark shell 时候的参数(怎么include jar 包)