ebula 版本:release3.1.0
部署方式:分布式
安装方式:源码编译
是否为线上版本:Y
硬件信息
磁盘 nvme
CPU 64核、内存信息 512g
问题的具体描述
consle 连接graph 执行sumjob ingest
查看storage的内存和cpu。只有3-5个线程在做compaction,然后发查询命令
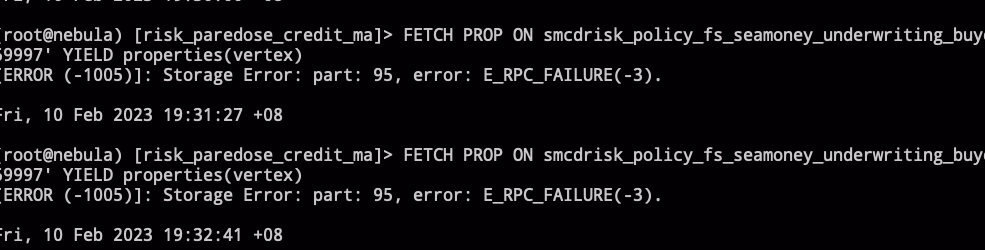
FETCH PROP ON smcdrisk_policy_fs_seamoney_underwriting_buyer_id '59997' YIELD properties(vertex)
,转换为rpc调用就是 future_getProps, 报错,
graph日志报错:
在storage rpcserver层加日志,没有ingest的时候,查询可以正常打印,ingest的时候,没有打印
查看了文件描述符,和内存,cpu,都很空闲。telnet storage的9779也没问题
1 个赞
storage这边除了compaction的日志,木有其他任何有用的日志了
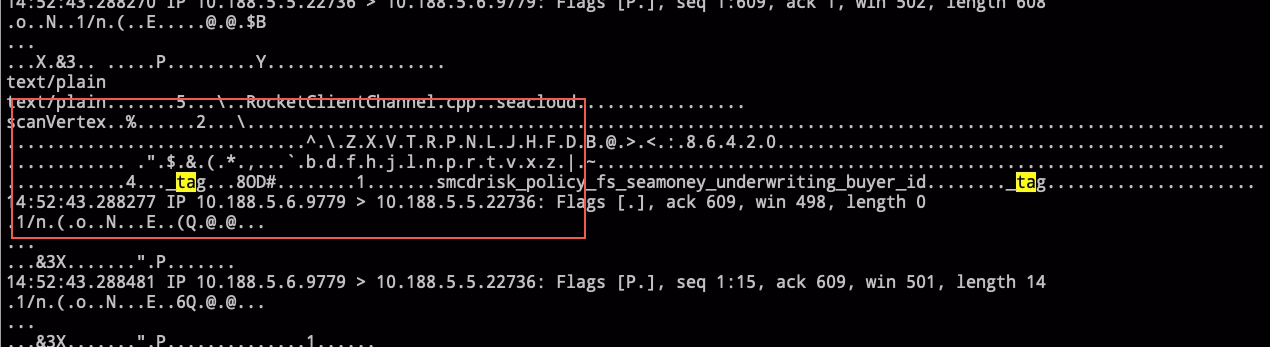
抓了下包,看着是graph有给storage 发器tcp包,但是不知道为什么storage这边没有去读
这个是tcp层graph 发送给storage的包
这个consle的错误
还看见一个ASK_EXPIRED 响应
1,三台机器,每台机器一个storage,meta,graph,server ip port。按照官方的,
storage 9779, graph 9669, storage 9559
space 信息
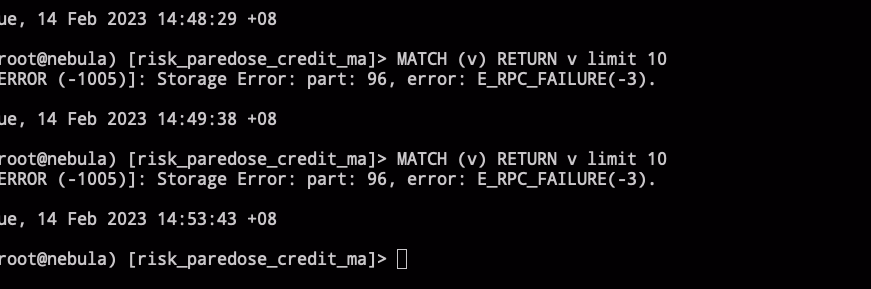
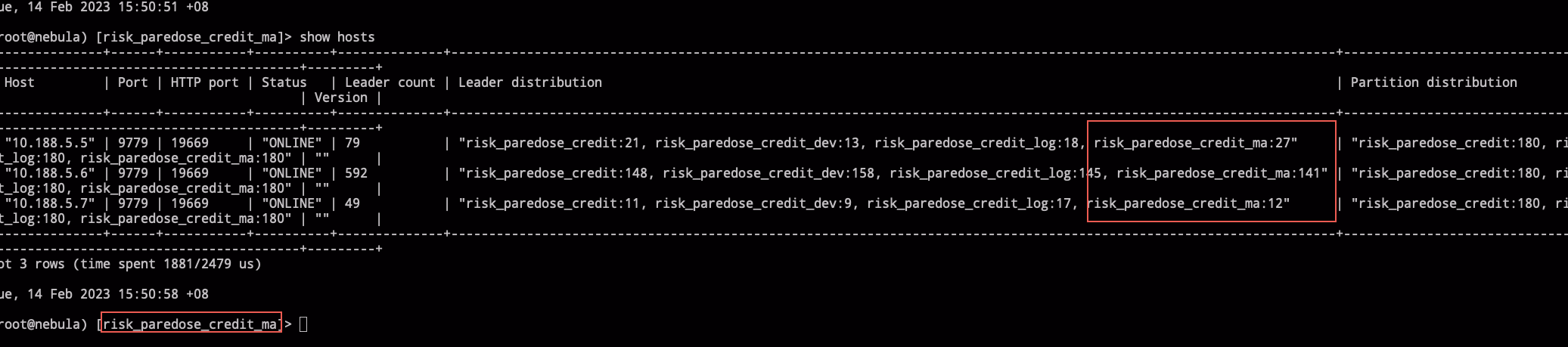
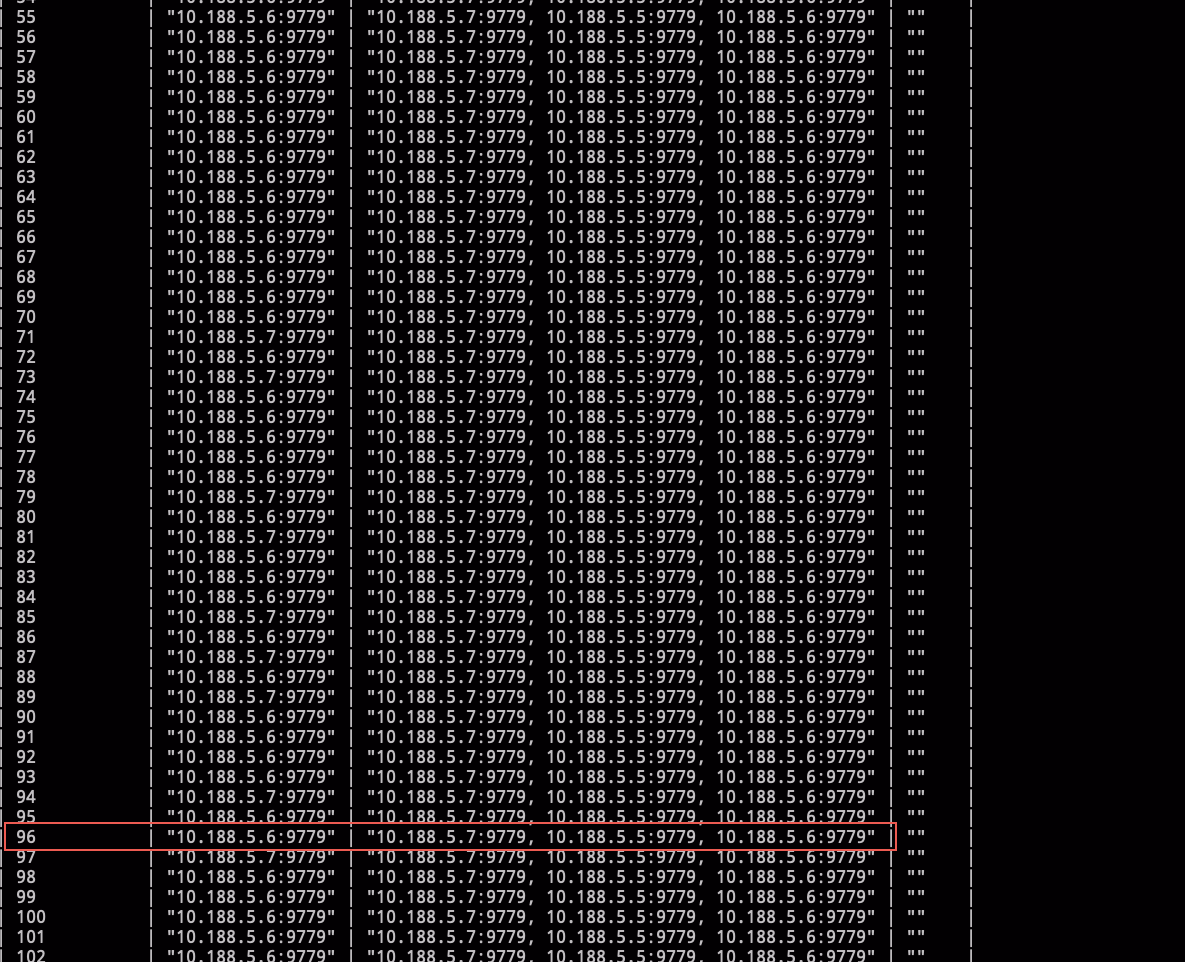
相关 part leader 对的上,part 96 是在做 ingest 和 compaction 的机器
show parts信息
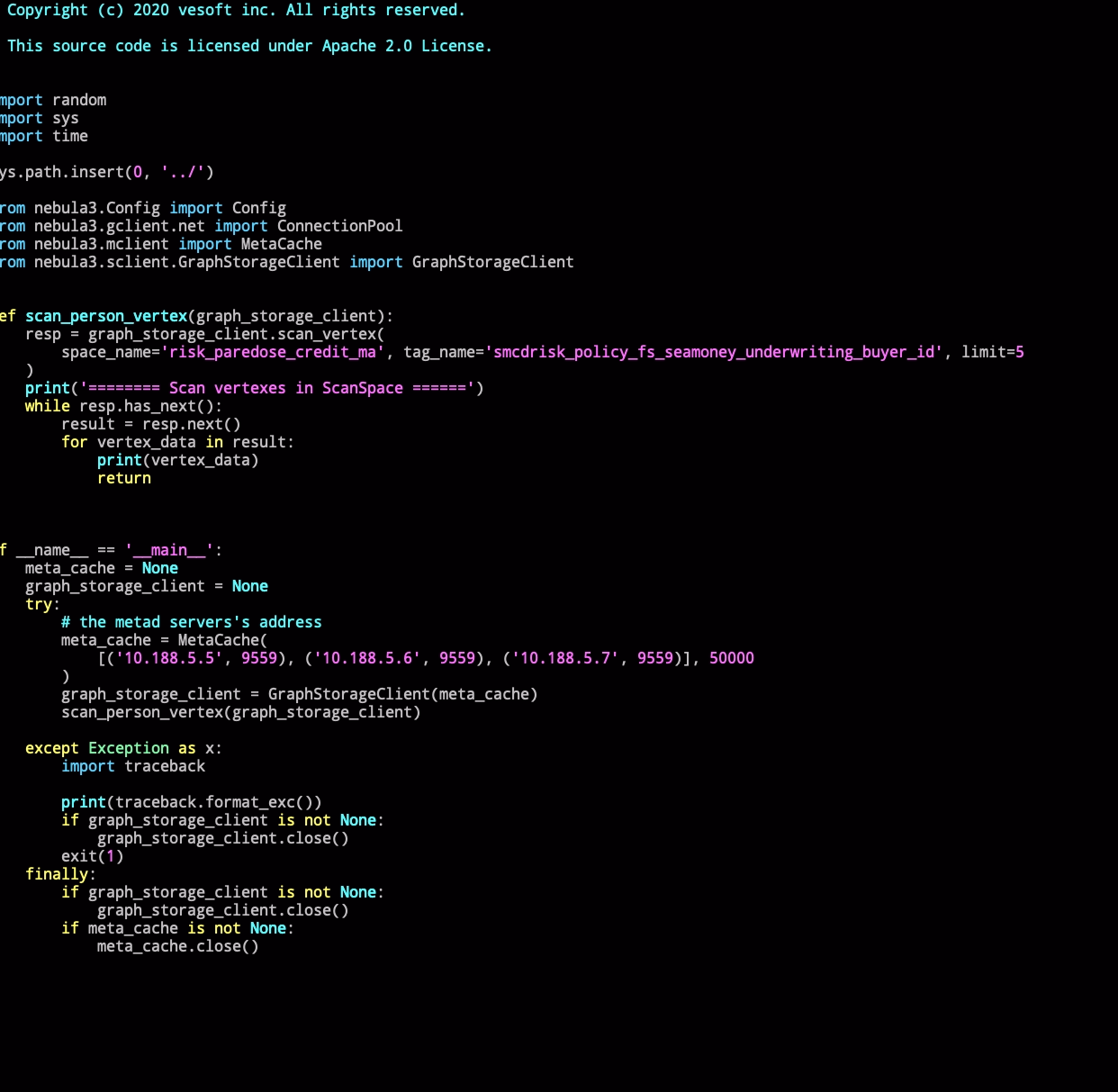
另外我单写了python的客户端 直接连接storage发请求,是可以成功的
spw
9
show jobs 看一下?ingest 和 compaction 多久了?
spw
10
按说不应该,两个客户端都是包的 thrift 的生成代码;如果是这样的话,有可能是 thrift rpc 框架可能有哪里有问题。
二十多分钟了。但是我理解inget和compaction这个不应该影响rpc请求吧,storage也就是rocksdb的线程再做compaction,为什么会影响storage rpc的读取呢
不执行compaction的时候console能正常的fetch?compaction之后console就不行了??
复现应该还是很好复现的,用exchange 生出一份比较大的数据(500G到1T都行),然后submit job ingest,在ingest的时候一直查询graph,最好是用同一份sst文件,反复做ingest,不要关闭自动compaction
spw
15
这种情况确实会由于 RocksDB 负载过高超时;但是怎么都会进 processor 的,看你的描述不进 processor 就很诡异。
当然,这可能与 thrift server 的线程池有关, 但不确定是怎么打满的。
可以手动复现下试试,目前因为我们ingest比较多,所以出现了很多了已经
当时我执行了top -H -p storagedPId, 看着thrift线程池没有啥cpu消耗
spw
20
好,另外,你自己也可以再试试 fetch prop 卡住的时候,去 storaged 上通过 pstack 看看卡在哪里了。