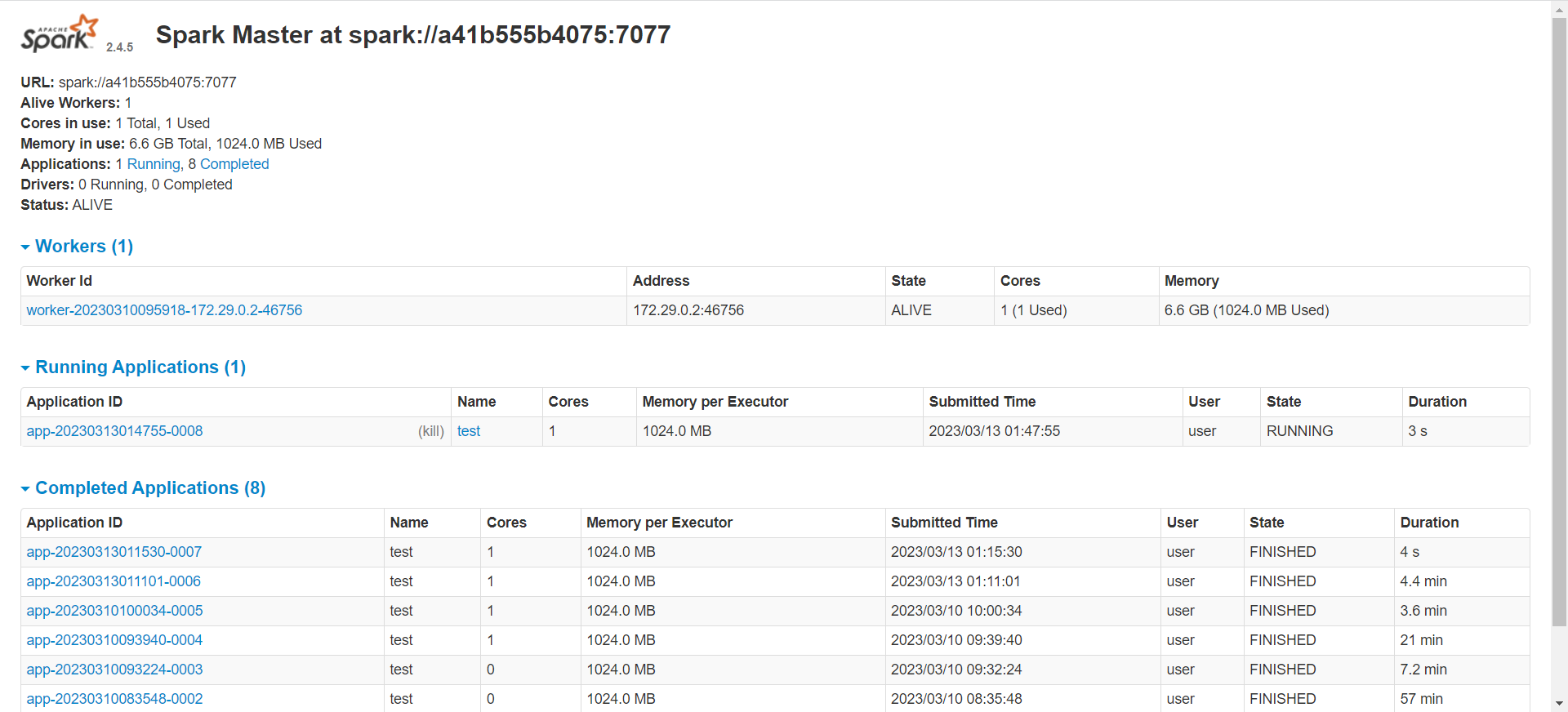
为什么我在docker-compose中设置了cores还显示0呢

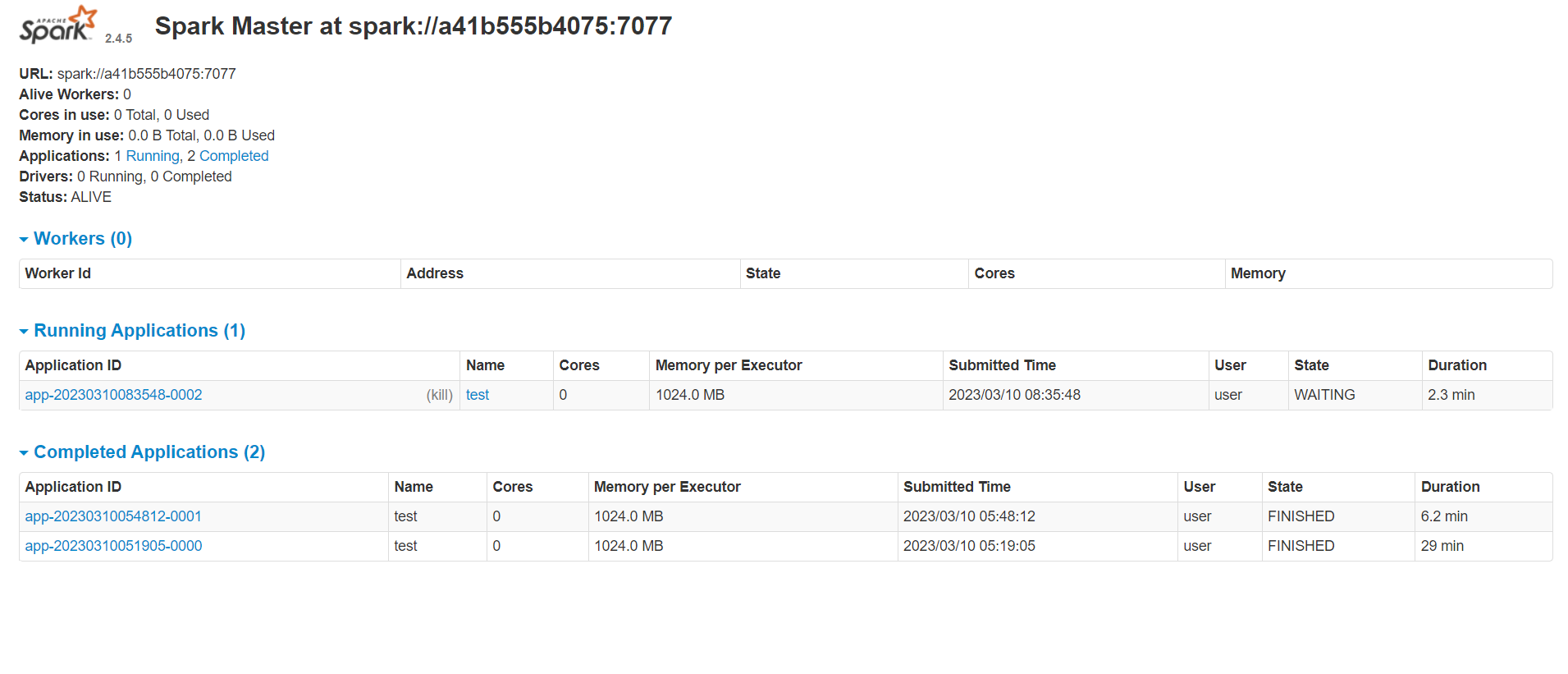
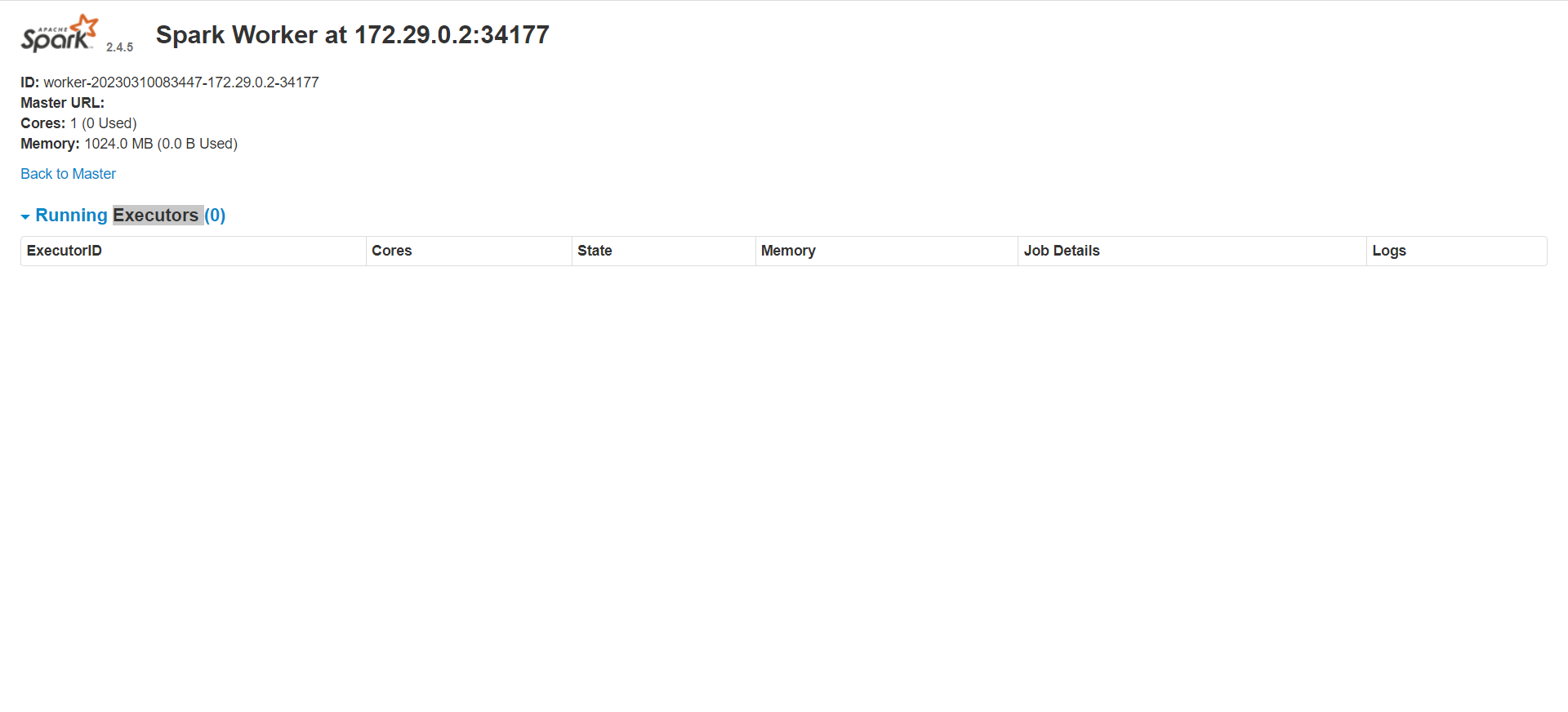
我单独去打开8081端口的网页还是没有worker服务
你的worker进程有没有启动呢,如果worker进程没启动,怎么配置都没用。 可以通过jps命令查看下,正常spark集群启动后会有名为master和worker的进程。
你只有一个worker,只有一个core。 程序中申请了4个,没有足够的资源可以分配给你
我试过修改过后的代码还是这样
import os
from pyspark.sql import SparkSession, Row
from pyspark import SparkContext
spark = SparkSession.builder\
.config("spark.dynamicAllocation.enabled","false")\
.master('spark://192.168.1.230:7077')\
.config("spark.jars",r"D:\PycharmProjects\pythonProject2\download\nebula-spark-connector.jar")\
.config("SPARK_WORKER_MEMORY","1G")\
.config("spark.executor.instances","1")\
.config("spark.executor.cores","1")\
.appName("test").getOrCreate()
df = spark.read.format("com.vesoft.nebula.connector.NebulaDataSource").option(
"type", "vertex").option(
"spaceName", "demo").option(
"label", "player").option(
"returnCols", "name").option(
"metaAddress", "192.168.1.230:33468").option(
"partitionNumber", 2).load()
df.show(n=2)
运行结果
E:\anaconda\envs\successful\python.exe D:/PycharmProjects/pythonProject2/1.py
Warning: Ignoring non-Spark config property: SPARK_WORKER_MEMORY
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
[Stage 0:> (0 + 0) / 1]23/03/13 10:17:32 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
23/03/13 10:17:47 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
23/03/13 10:18:02 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
23/03/13 10:18:17 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
[Stage 0:> (0 + 0) / 1]