本文系 NebulaGraph 社区版 v3.5.0 的性能测试报告。
在 v3.5.0 版本中,NebulaGraph 优化了相关的 FIND ALL PATH 性能,支持了免索引查询等等功能。具体的 v3.5.0 的 release note 参见:https://discuss.nebula-graph.com.cn/t/topic/13139
而本次性能概述如下:
FIND ALL PATH的深度性能有大约 50-500% 的提升,其中 1 to 5 steps 大约有 600% 的提升;- Match2HOP_count 的性能有 15% 幅度的提升;
- 解决
GO使用属性过滤时,返回结果不正确问题。部分 case(Go1~3 StepEdge、和Go1~3 StepEdge_count)存在小幅度的性能下降;
此外,如果对于深度(10 跳以上)性能有较高诉求,可使用企业版本。
测试环境
服务器和压测机皆为物理机:
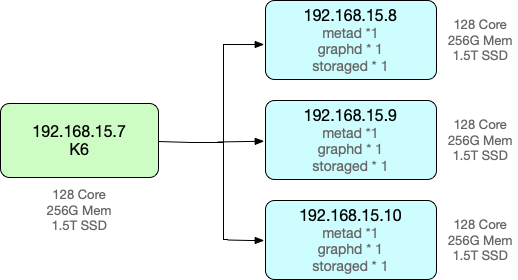
测试数据
测试数据采用 LDBC-SNB SF100 数据集,SF100 数据集大小为 100 G,共有 282,386,021 个点以及 1,775,513,185 条边。测试用的图空间分区数为 24,副本数为 3。
关于 LDBC-SNB
关联数据基准委员会(LDBC,Linked Data Benchmark Council),是图(Graph)和 RDF 数据管理的基准指南制定者。社交网路基准(SNB,Social Network Benchmark)是关联数据基准委员会(LDBC)开发的软件基准(Benchmark)之一。关于 LDBC-SNB 数据集,具体请参考以下文档:
- LDBC-SNB Specification:https://ldbcouncil.org/ldbc_snb_docs/ldbc-snb-specification.pdf
- LDBC-SNB Docs:https://github.com/ldbc/ldbc_snb_docs
- LDBC-SNB测试数据集生产工具:https://github.com/ldbc/ldbc_snb_datagen_spark
NebulaGraph Commit
- nebula-graphd version d1e2118
- nebula-storaged version d1e2118
- nebula-metad version d1e2118
测试说明
- 压测工具使用基于 Go 语言的 k6,具体请参阅 k6 官方网站;客户端使用的是 nebula-go
- 图表中横坐标轴的 “50_vu”、“100_vu” 等中的 “vu” 表示的是 k6 使用的概念 “virtual user”,即性能测试中的并发数;50_vu 表示 50 个并发用户,100_vu 表示 100 个并发用户,以此类推…
- 性能基线使用正式发布的 v3.4.0 版本
- ResponseTime = Latency(服务端处理时长)+ 网络回传结果时长 + 客户端反序列化结果时长
基线测试
注:下图涉及的词语解释
- QPS 即吞吐率
- Latency 即服务端耗时
- ResponseTime 即客户端耗时
- RowSize 即请求返回行数
用例和结果
查询带边属性
GO {} STEP FROM {} OVER KNOWS yield KNOWS.creationDate
一跳·吞吐率
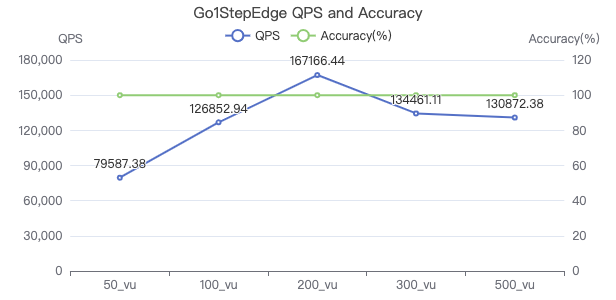
一跳·服务端耗时(ms)
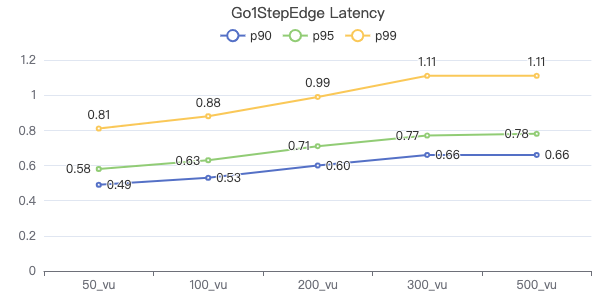
一跳·客户端耗时(ms)
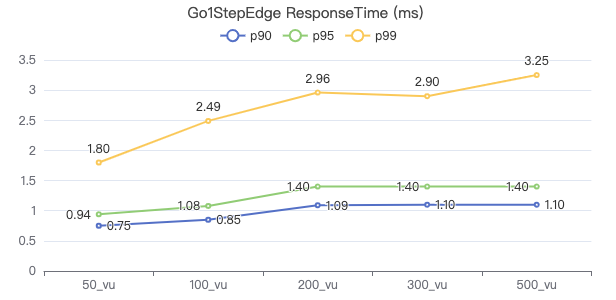
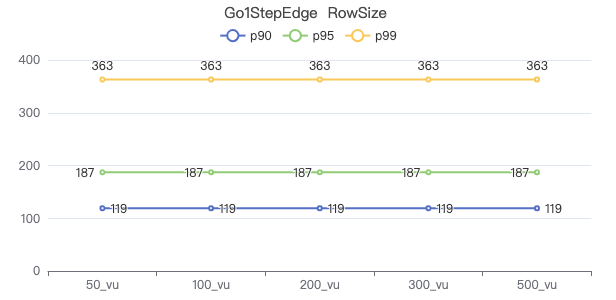
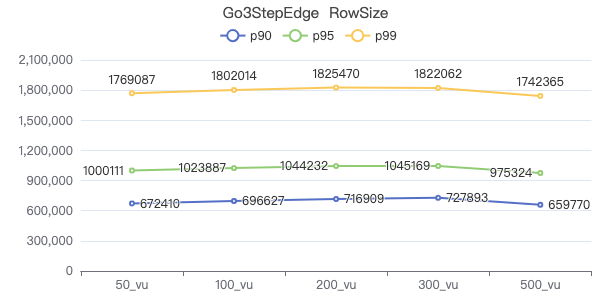
一跳·请求返回行数
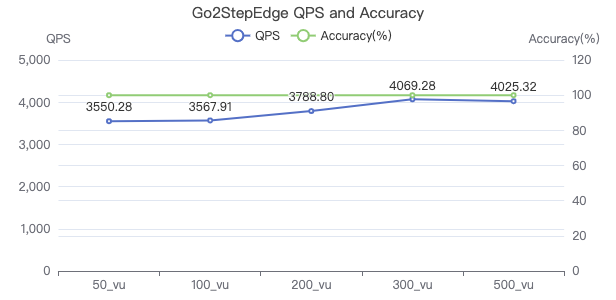
二跳·吞吐率
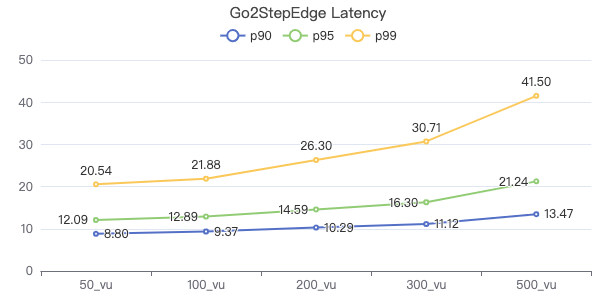
二跳·服务端耗时(ms)
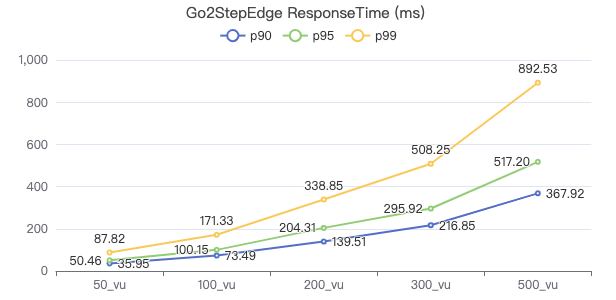
二跳·客户端耗时(ms)
二跳·请求返回行数
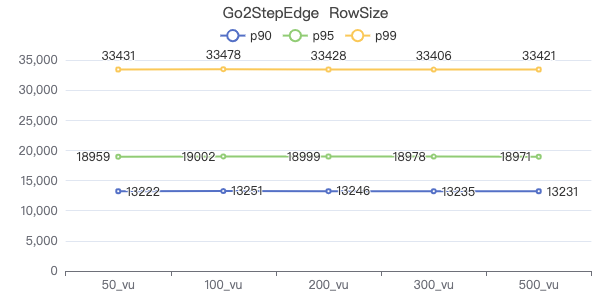
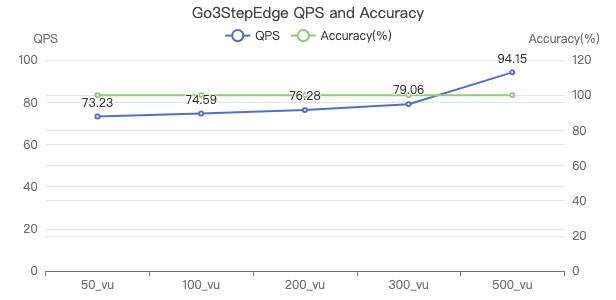
三跳·吞吐率
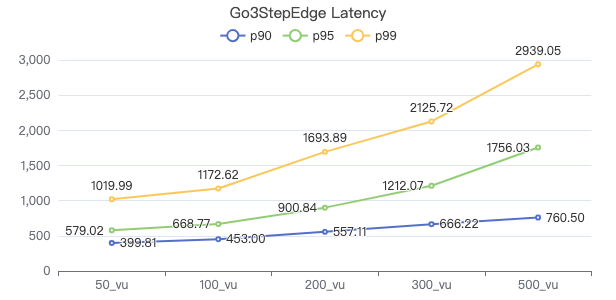
三跳·服务端耗时(ms)
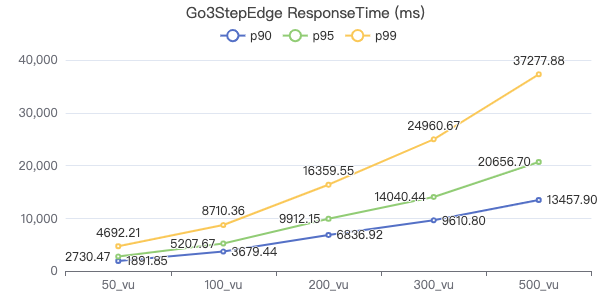
三跳·客户端耗时(ms)
三跳·请求返回行数
查询带目的点属性
GO {} STEP FROM {} OVER KNOWS yield $$.Person.firstName
一跳·吞吐率

一跳·服务端耗时(ms)

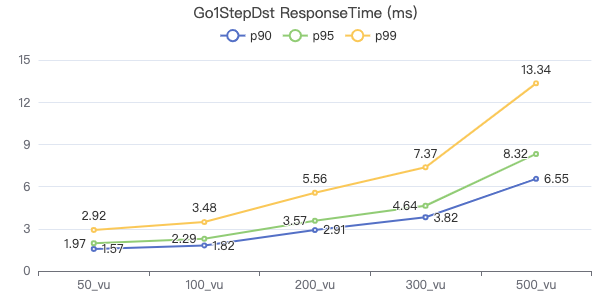
一跳·客户端耗时(ms)
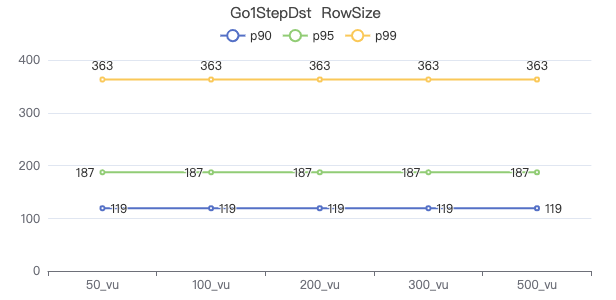
一跳·请求返回行数
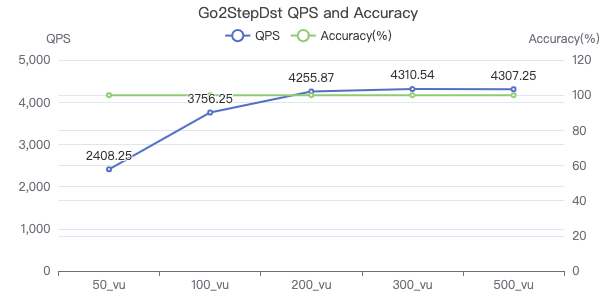
二跳·吞吐率
二跳·服务端耗时(ms)
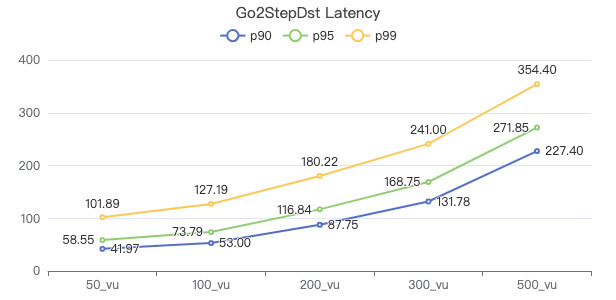
二跳·客户端耗时(ms)
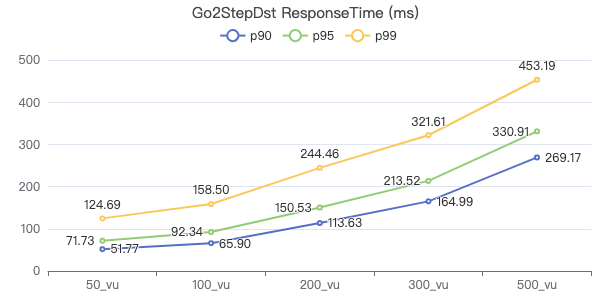
二跳·请求返回行数
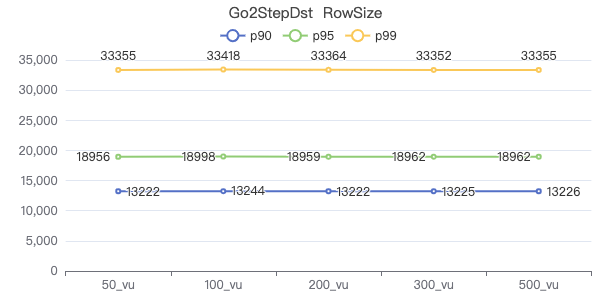
三跳·吞吐率
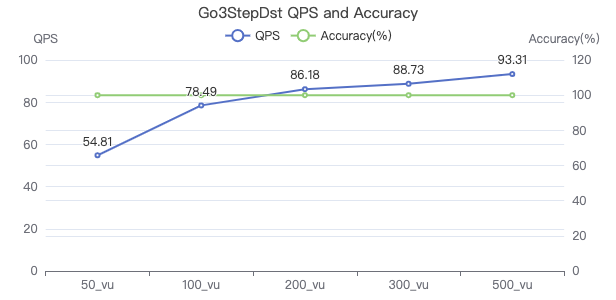
三跳·服务端耗时(ms)
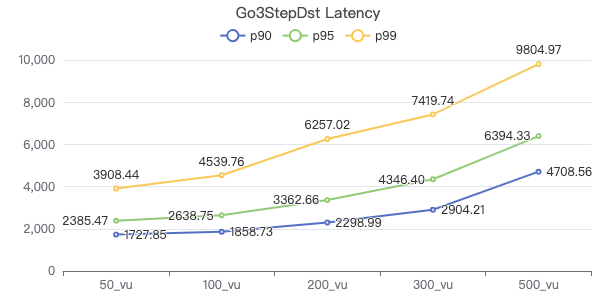
三跳·客户端耗时(ms)
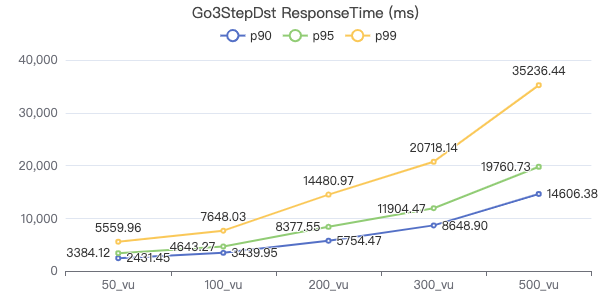
三跳·请求返回行数
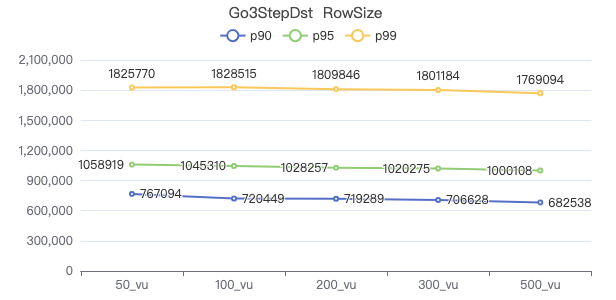
查询带边属性+目的点属性
GO {} STEP FROM {} OVER KNOWS yield DISTINCT KNOWS.creationDate as t, $$.Person.firstName, $$.Person.lastName, $$.Person.birthday as birth | order by $-.t, $-.birth | limit 10
一跳·吞吐率
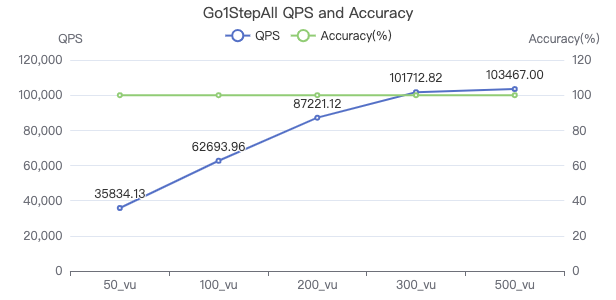
一跳·服务端耗时(ms)
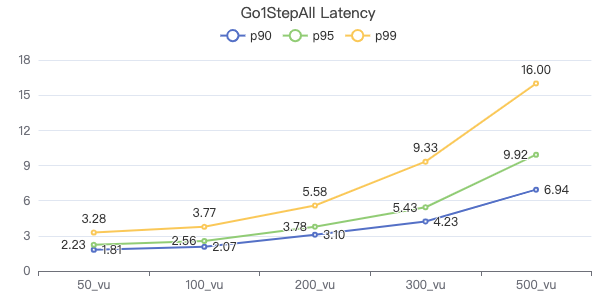
一跳·客户端耗时(ms)
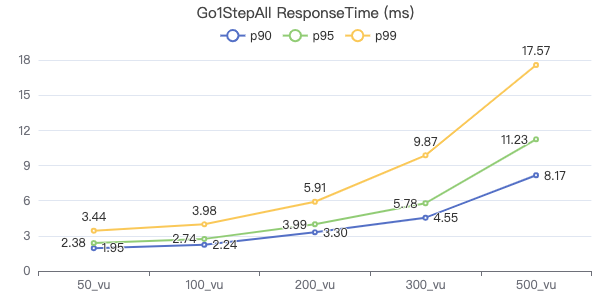
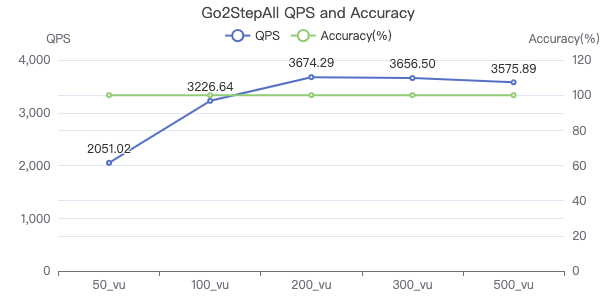
二跳·吞吐率
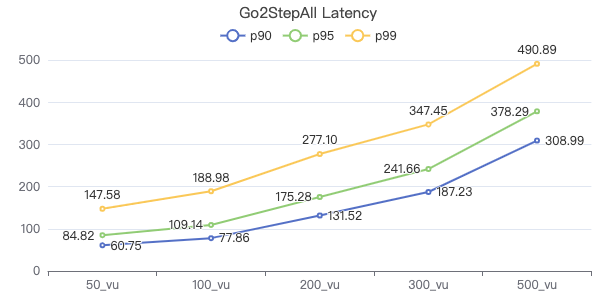
二跳·服务端耗时(ms)
二跳·客户端耗时(ms)
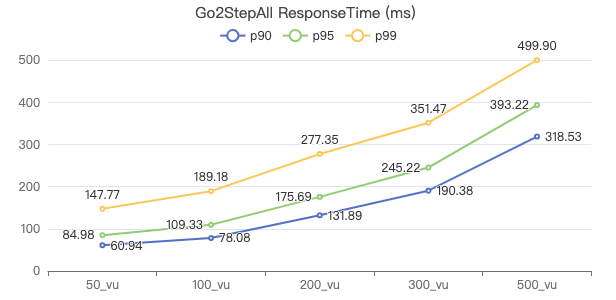
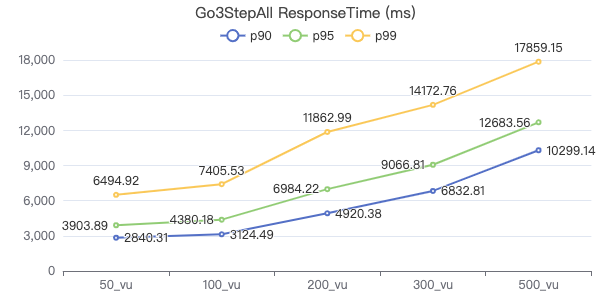
三跳·吞吐率
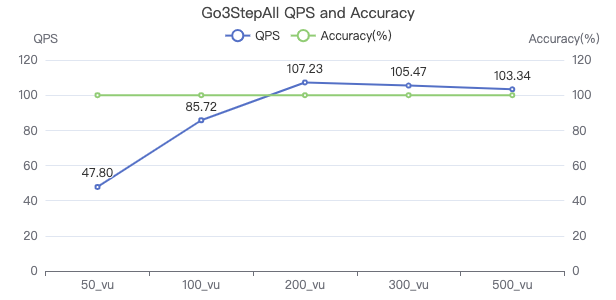
三跳·服务端耗时(ms)
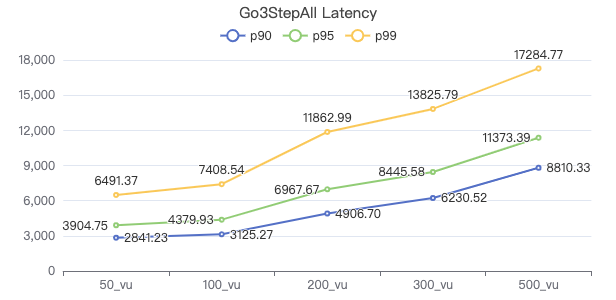
三跳·客户端耗时(ms)
LOOKUP
LOOKUP ON Person WHERE Person.firstName == '{}' YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed
LOOKUP·吞吐率
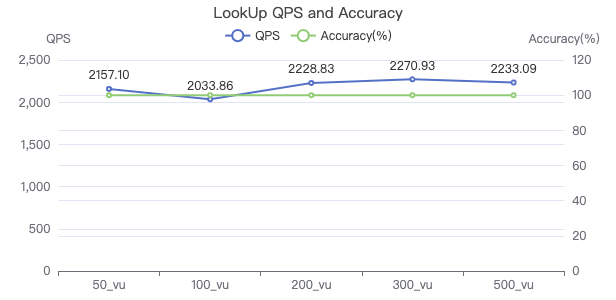
LOOKUP·服务端耗时(ms)
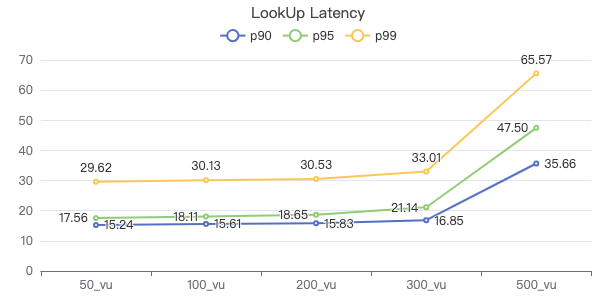
LOOKUP·客户端耗时(ms)

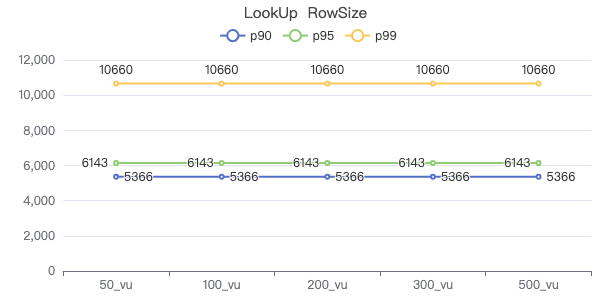
LOOKUP·请求返回行数
FETCH 点
FETCH PROP ON Person {} YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed
FETCH 点·吞吐率
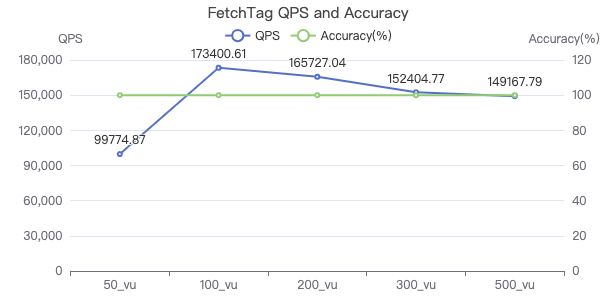
FETCH 点·服务端耗时(ms)
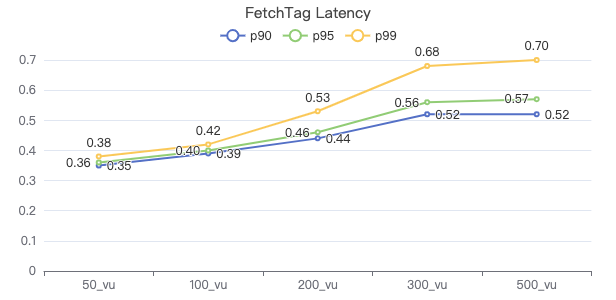
FETCH 点·客户端耗时(ms)
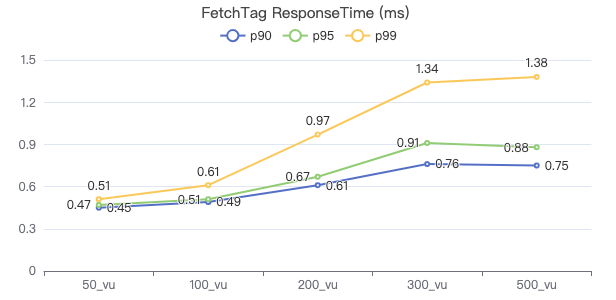
FETCH 点·请求返回行数
FETCH 边
FETCH PROP ON KNOWS {} -> {} YIELD KNOWS.creationDate
FETCH 边·吞吐率
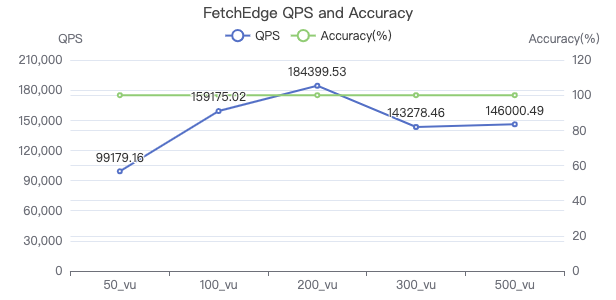
FETCH 边·服务端耗时(ms)
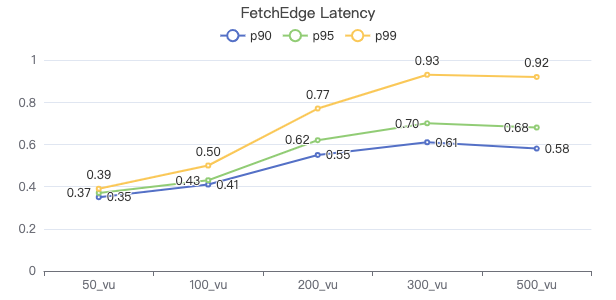
FETCH 边·客户端耗时(ms)
FETCH 边·请求返回行数
MATCH 索引
MATCH (v:Person) WHERE v.Person.firstName == '{}' RETURN v
MATCH·吞吐率
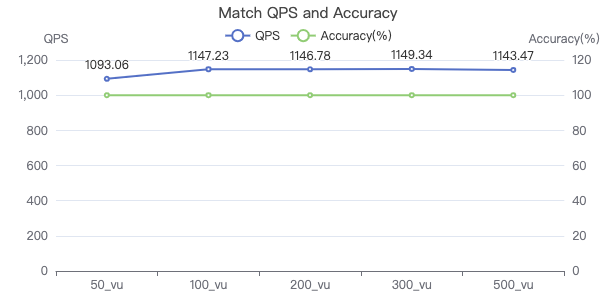
MATCH·服务端耗时(ms)
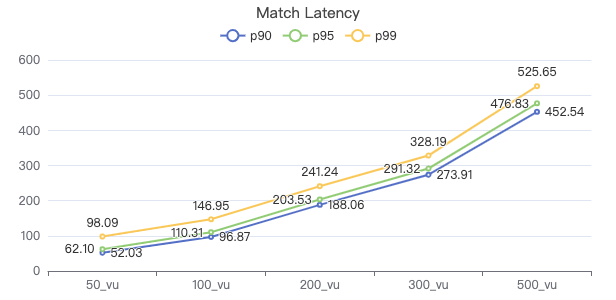
MATCH·客户端耗时(ms)
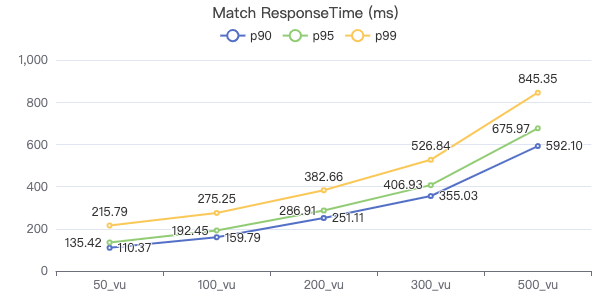
MATCH·请求返回行数
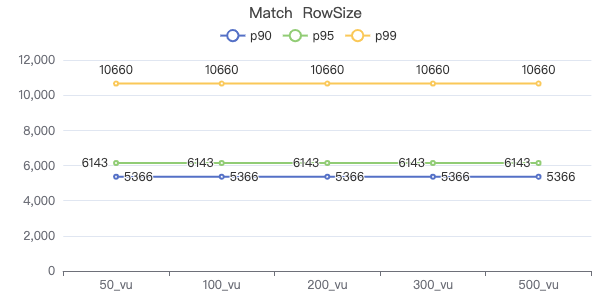
MATCH 一跳
MATCH (v1:Person)-[e:KNOWS]->(v2:Person) WHERE id(v1) == {} RETURN v2
MATCH 一跳·吞吐率
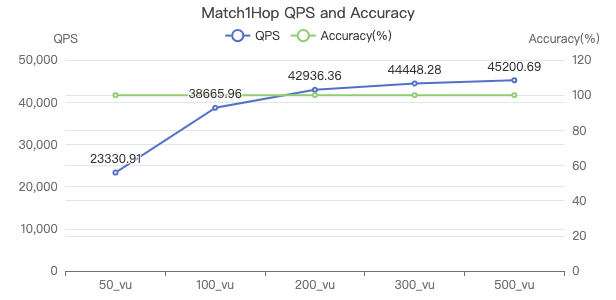
MATCH 一跳·服务端耗时(ms)

MATCH 一跳·客户端耗时(ms)

MATCH 一跳·请求返回行数
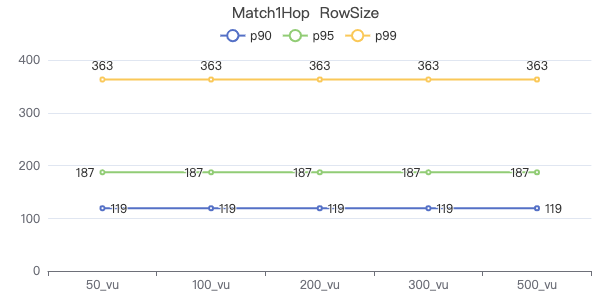
MATCH 两跳
MATCH (v1:Person)-[e:KNOWS*2]->(v2:Person) WHERE id(v1) == {} RETURN v2
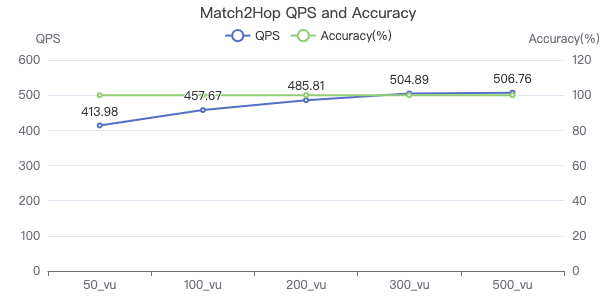
MATCH 两跳·吞吐率
MATCH 两跳·服务端耗时(ms)

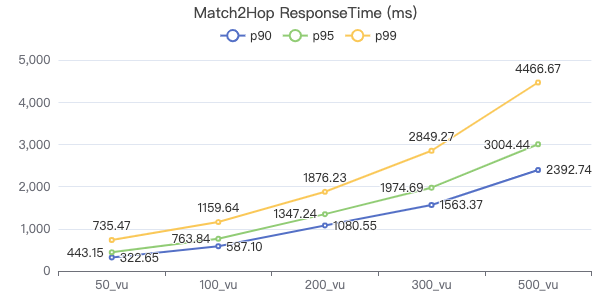
MATCH 两跳·客户端耗时(ms)
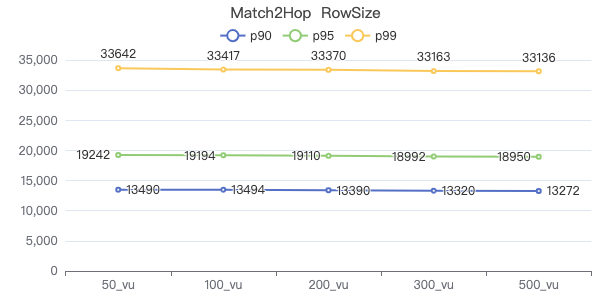
MATCH 两跳·请求返回行数
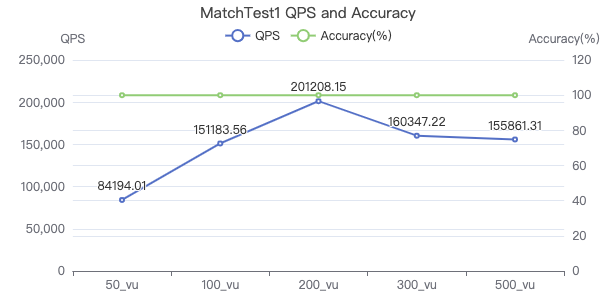
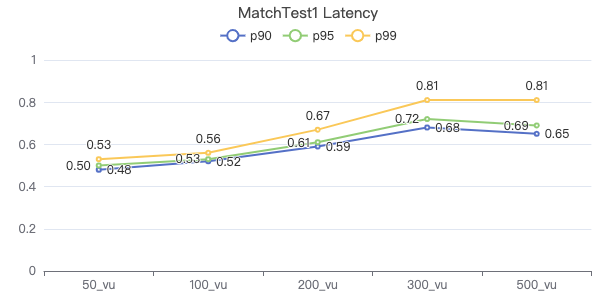
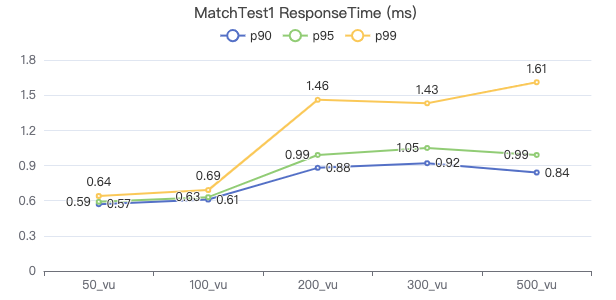
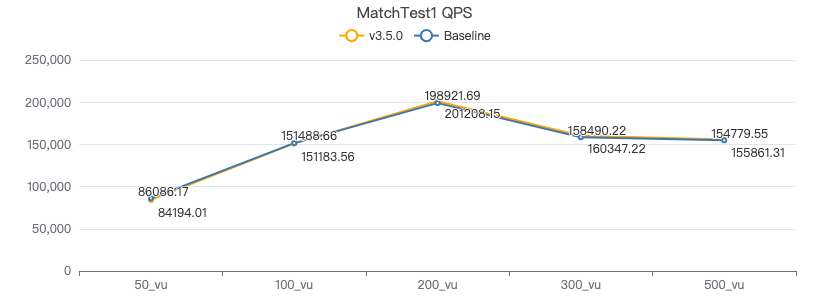
MatchTest1
match (v:Person) where id(v) == {} return count(v.Person.firstName)
吞吐率
服务端耗时(ms)
客户端耗时(ms)
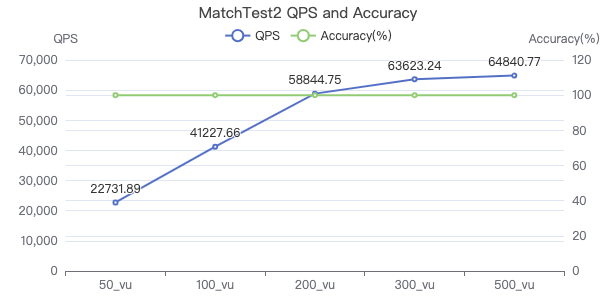
MatchTest2
match (v:Person)-[e:KNOWS]-(v2) where id(v) == {} and v2.Person.locationIP != 'yyy' return length(v.Person.browserUsed) + length(v2.Person.gender)
吞吐率
服务端耗时(ms)
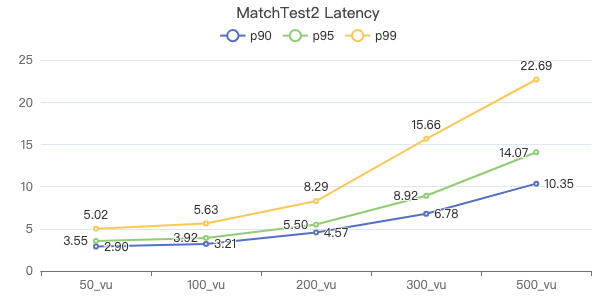
客户端耗时(ms)
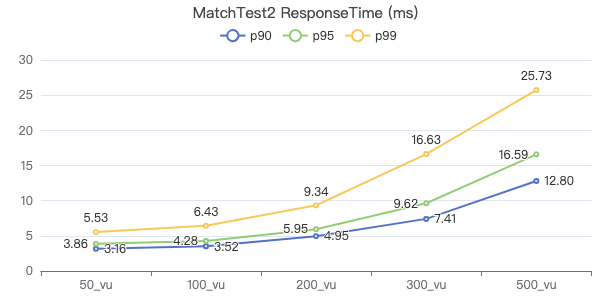
请求返回行数
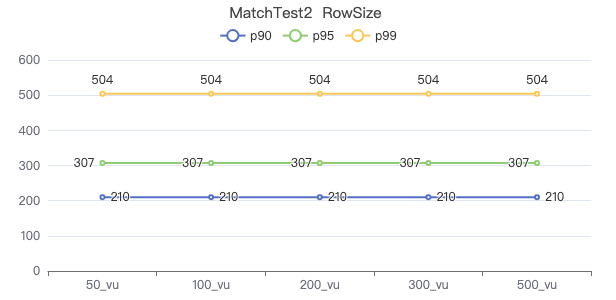
MatchTest3
match (v:Person)-[e:KNOWS]-(v2) where id(v) == {} and v2.Person.locationIP != 'yyy' with v, v2 as v3 return length(v.Person.browserUsed) + (v3.Person.gender)
吞吐率
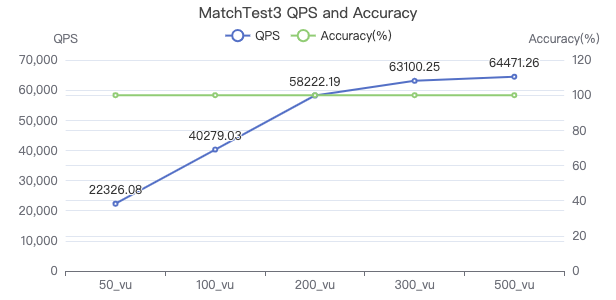
服务端耗时(ms)
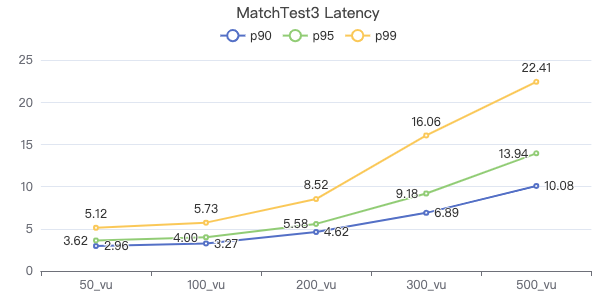
客户端耗时(ms)
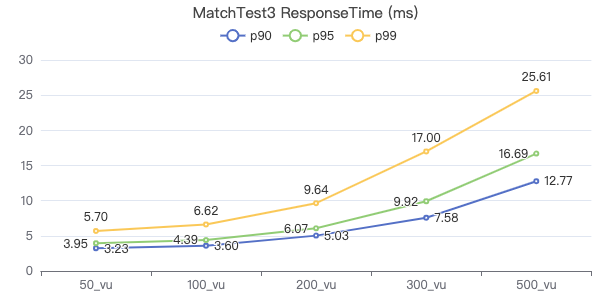
请求返回行数

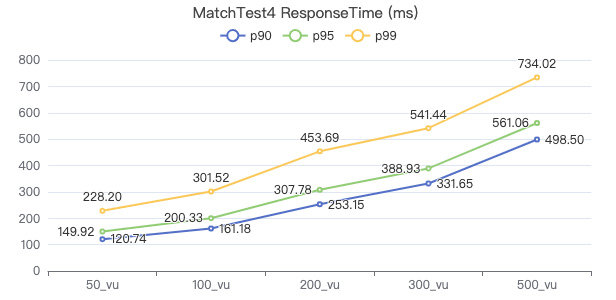
MatchTest4
MATCH (m)-[:KNOWS]-(n) WHERE id(m)=={} OPTIONAL MATCH (n)<-[:KNOWS]-(l) RETURN length(m.Person.lastName) AS n1, length(n.Person.lastName) AS n2, l.Person.creationDate AS n3 ORDER BY n1, n2, n3 LIMIT 10
吞吐率
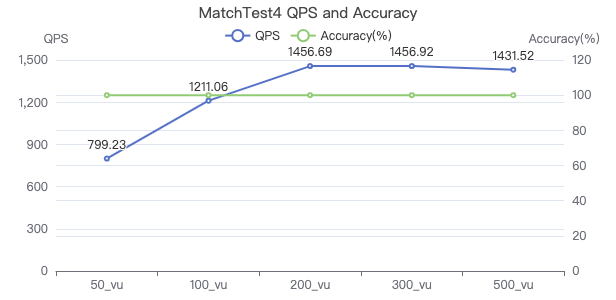
服务端耗时(ms)
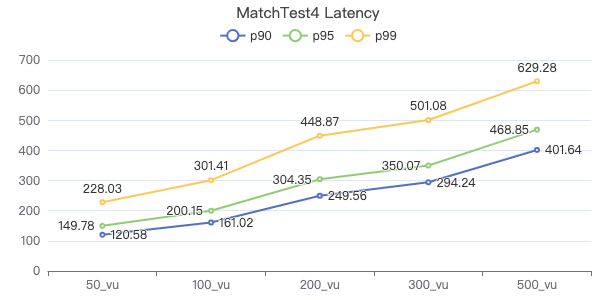
客户端耗时(ms)
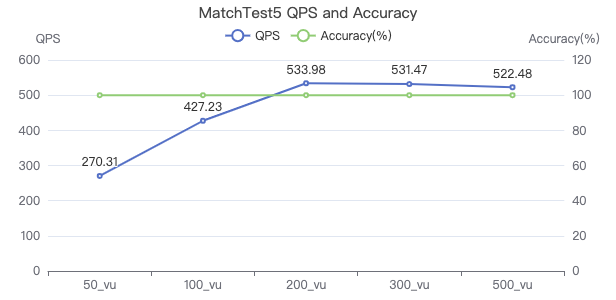
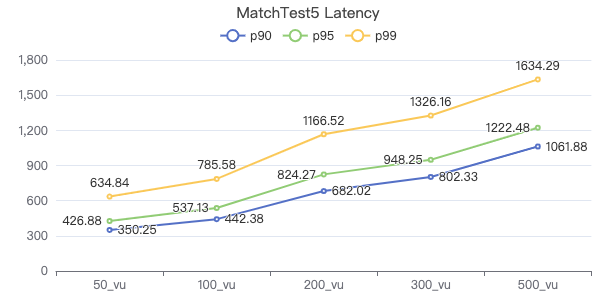
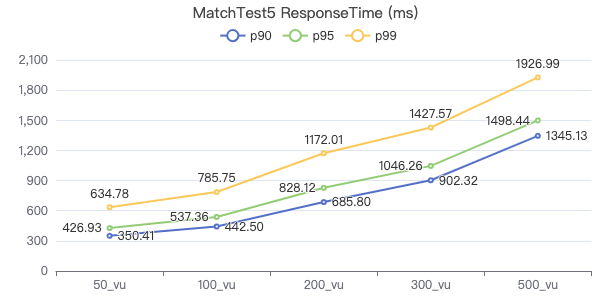
MatchTest5
MATCH (m)-[:KNOWS]-(n) WHERE id(m)=={} MATCH (n)-[:KNOWS]-(l) WITH m AS x, n AS y, l RETURN x.Person.firstName AS n1, y.Person.firstName AS n2, CASE WHEN l.Person.firstName is not null THEN l.Person.firstName WHEN l.Person.gender is not null THEN l.Person.birthday ELSE 'null' END AS n3 ORDER BY n1, n2, n3 LIMIT 10
吞吐率
服务端耗时(ms)
客户端耗时(ms)
查询带边属性 count
GO {} STEP FROM {} OVER KNOWS yield KNOWS.creationDate | return count(*) ;
一跳·吞吐率
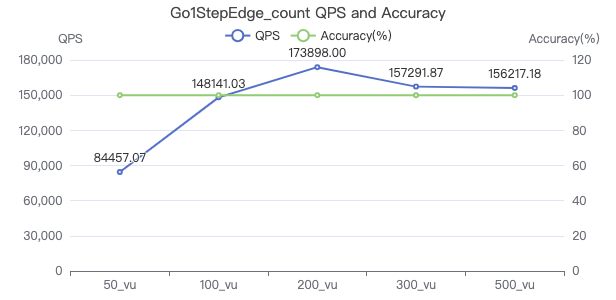
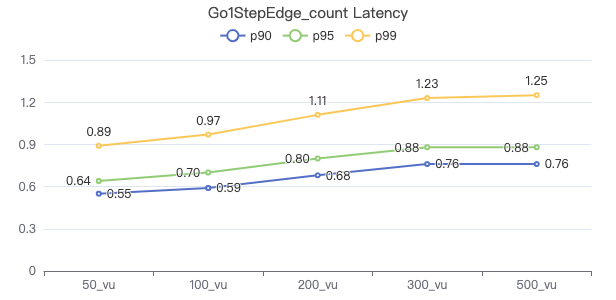
一跳·服务端耗时(ms)
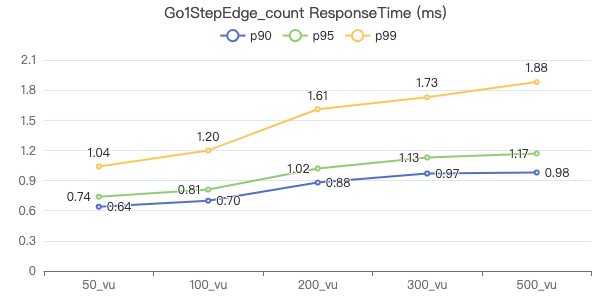
一跳·客户端耗时(ms)
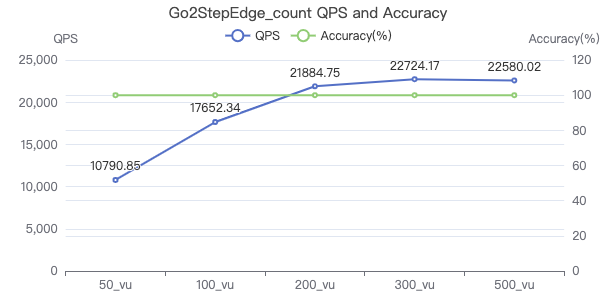
二跳·吞吐率
二跳·服务端耗时(ms)
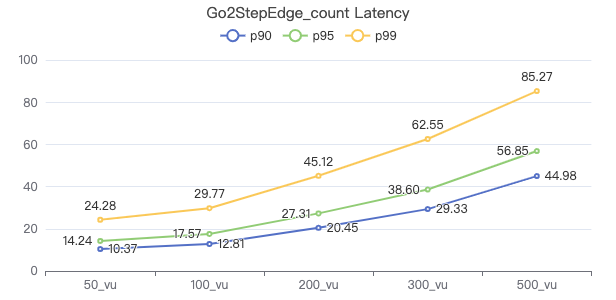
二跳·客户端耗时(ms)
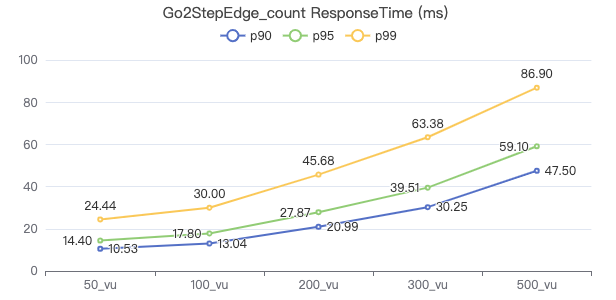
三跳·吞吐率
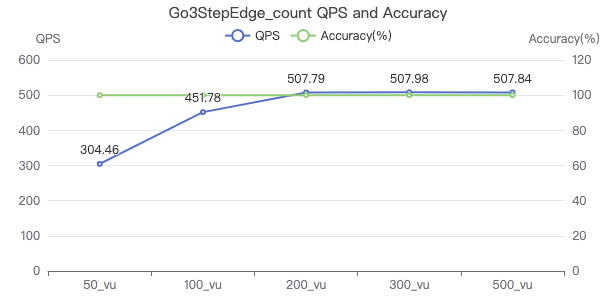
三跳·服务端耗时(ms)
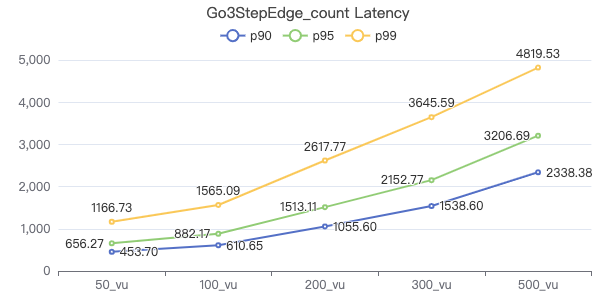
三跳·客户端耗时(ms)
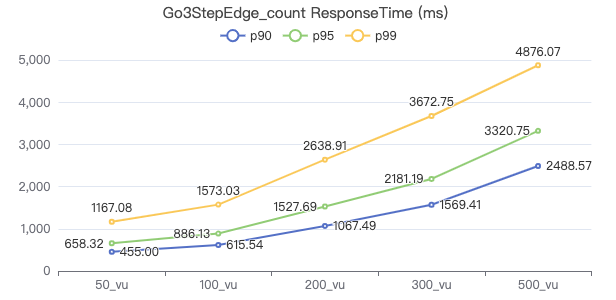
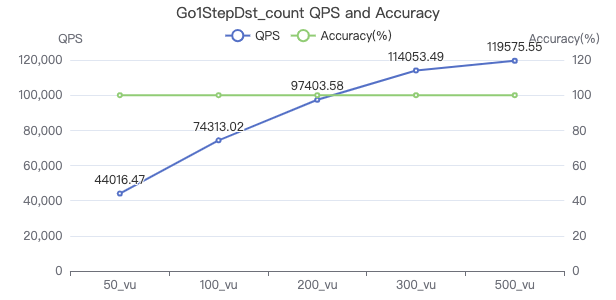
查询带目的点属性 count
GO 1 STEP FROM {} OVER KNOWS yield $$.Person.firstName | return count(*)
一跳·吞吐率
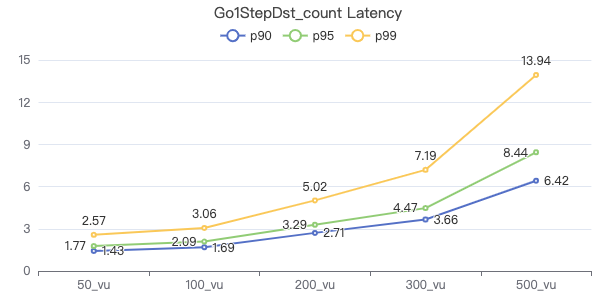
一跳·服务端耗时(ms)
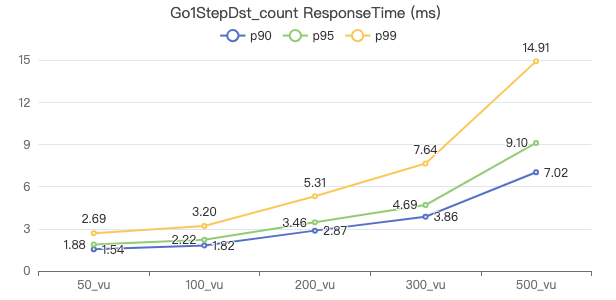
一跳·客户端耗时(ms)
二跳·吞吐率
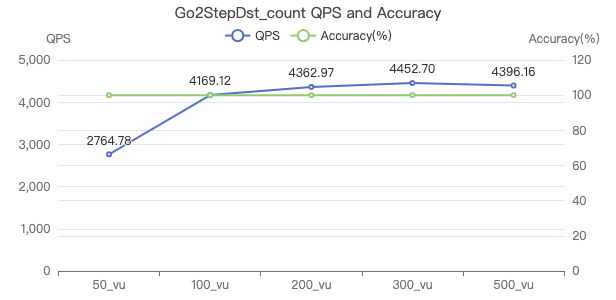
二跳·服务端耗时(ms)
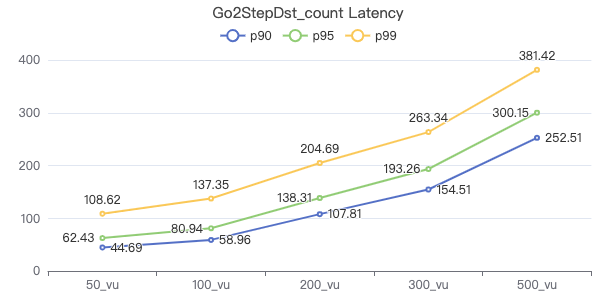
二跳·客户端耗时(ms)

三跳·吞吐率
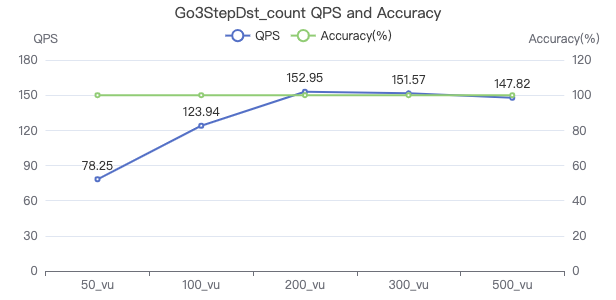
三跳·服务端耗时(ms)
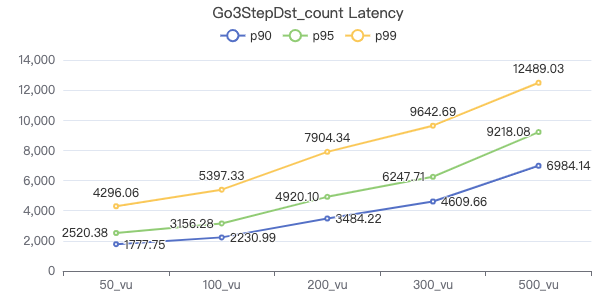
三跳·客户端耗时(ms)
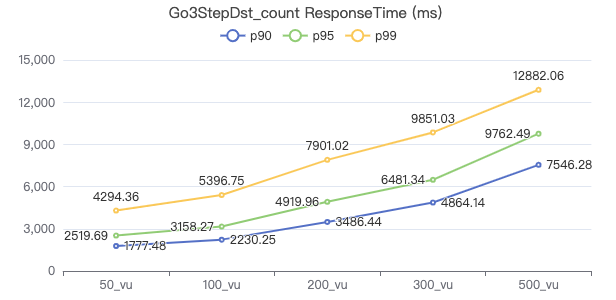
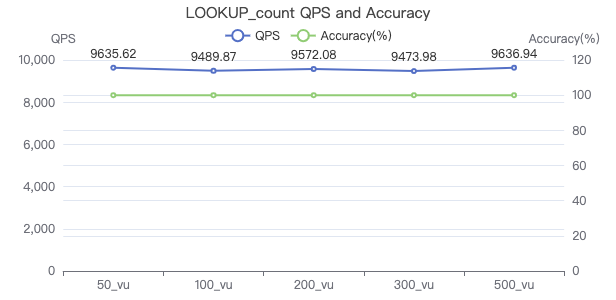
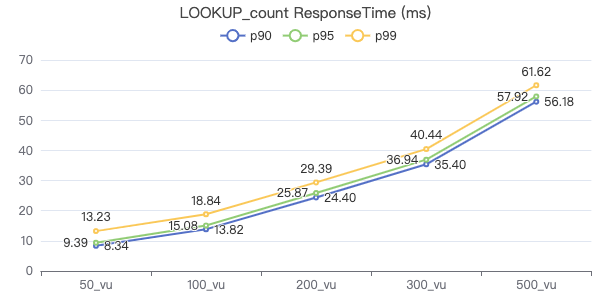
LOOKUP count
LOOKUP ON Person WHERE Person.firstName == '{}' YIELD Person.firstName | return count(*)
吞吐率
服务端耗时(ms)
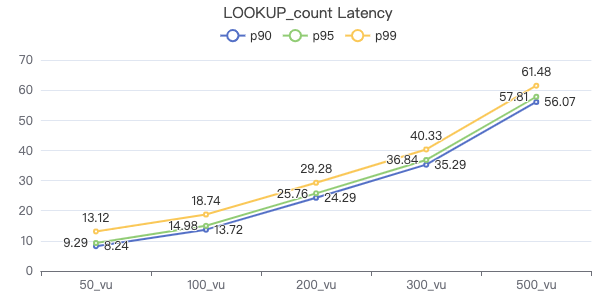
客户端耗时(ms)
MATCH count
MATCH (v:Person) WHERE v.Person.firstName == '{}' RETURN count(*)
吞吐率
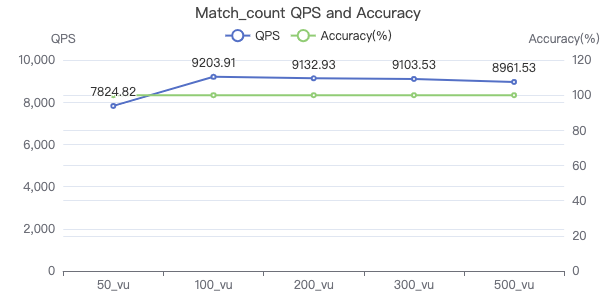
服务端耗时(ms)
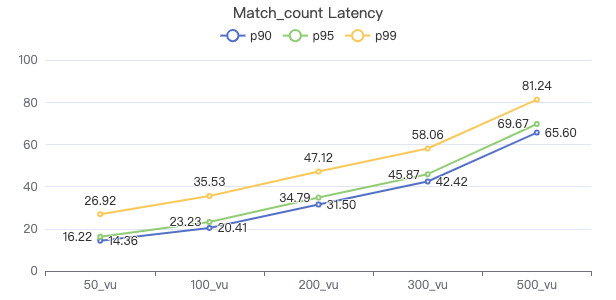
客户端耗时(ms)
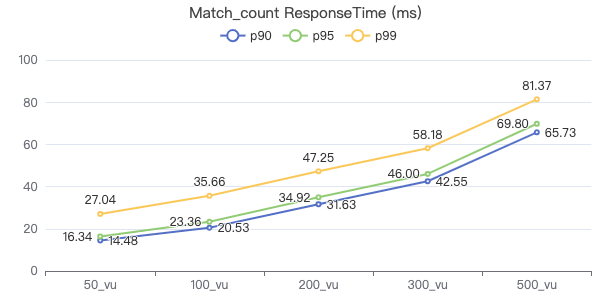
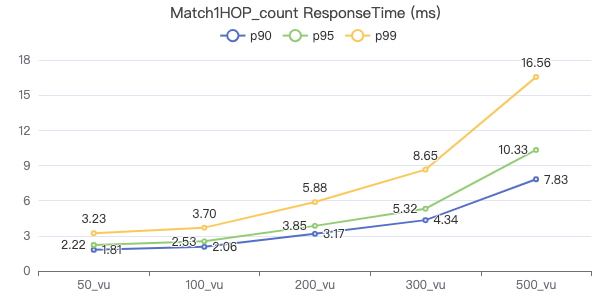
MATCH 一跳 count
MATCH (v1:Person)-[e:KNOWS]->(v2:Person) WHERE id(v1) == {} RETURN count(*)
吞吐率
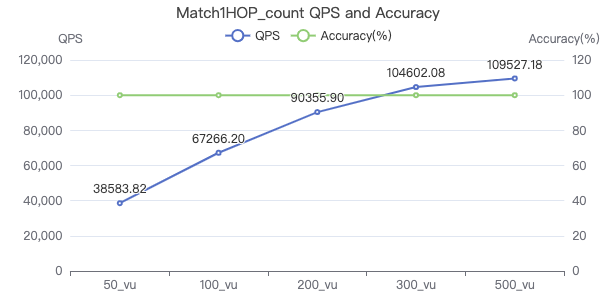
服务端耗时(ms)
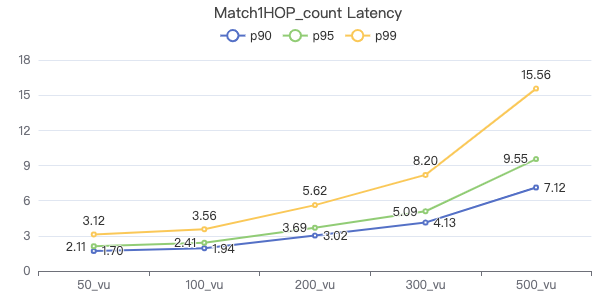
客户端耗时(ms)
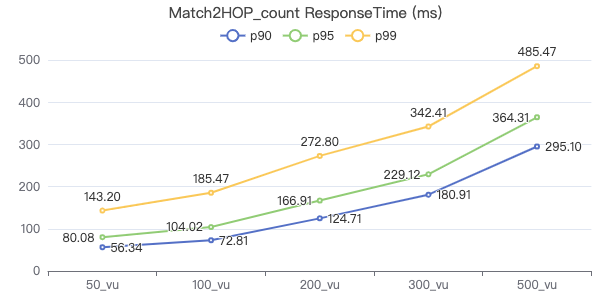
MATCH 两跳 count
MATCH (v1:Person)-[e:KNOWS*2]->(v2:Person) WHERE id(v1) == {} RETURN count(*)
吞吐率

服务端耗时(ms)
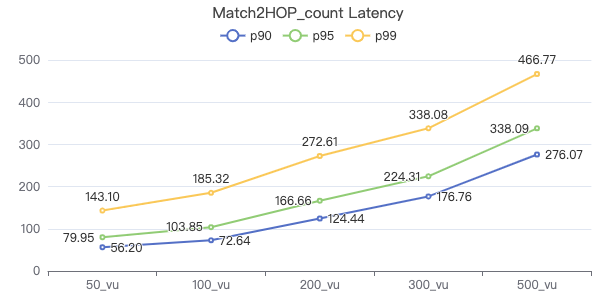
客户端耗时(ms)
插入点
INSERT VERTEX Comment (creationDate, locationIP, browserUsed, content, length) VALUES {}:('{}', '{}', '{}', '{}', {})
吞吐率
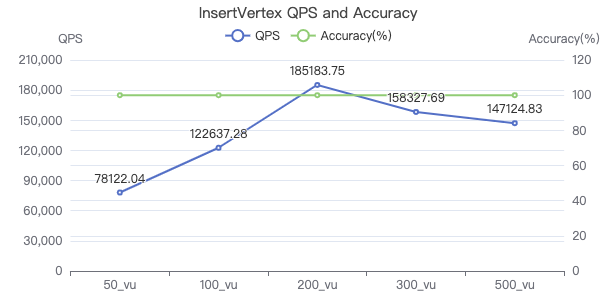
服务端耗时(ms)
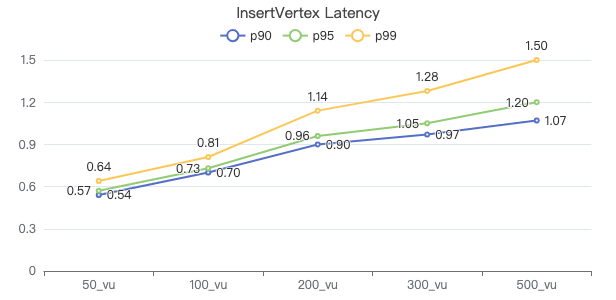
客户端耗时(ms)
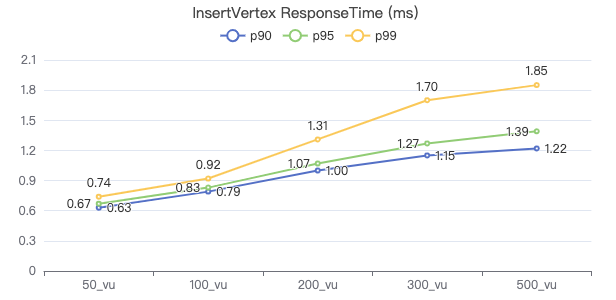
插入边
INSERT EDGE LIKES (creationDate) VALUES {}→{}:('{}')
吞吐率
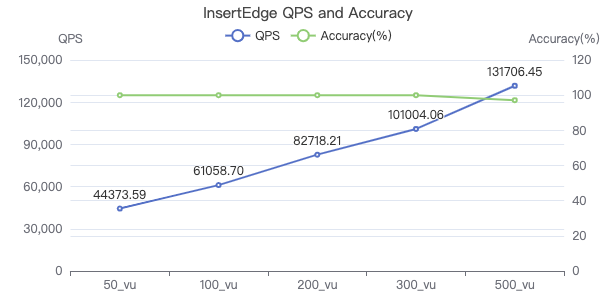
服务端耗时(ms)
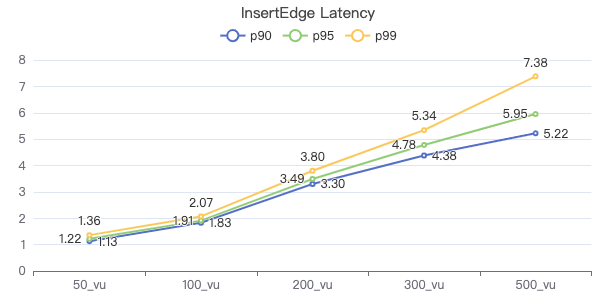
客户端耗时(ms)
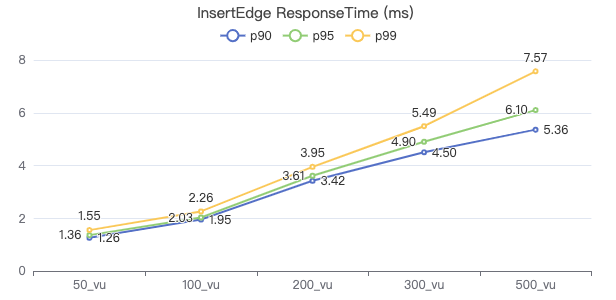
插入带索引的点
INSERT VERTEX Person (firstName,lastName,gender,birthday,creationDate,locationIP,browserUsed) VALUES {0}:(\"{1}\", \"{2}\",\"{3}\",\"{4}\",datetime(\"{5}\"), \"{6}\",\"{7}\")
吞吐率
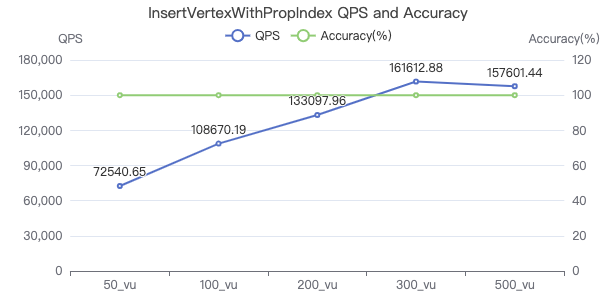
服务端耗时(ms)
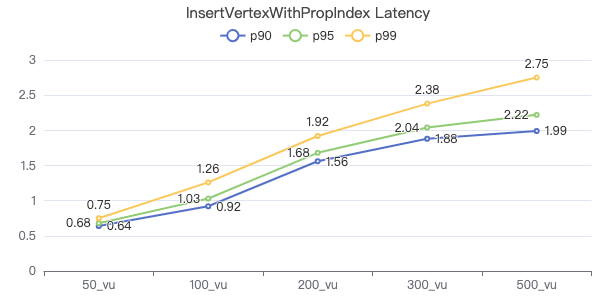
客户端耗时(ms)
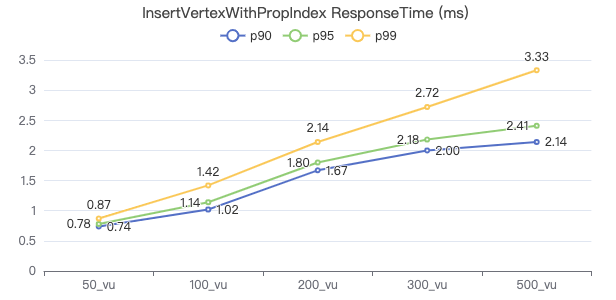
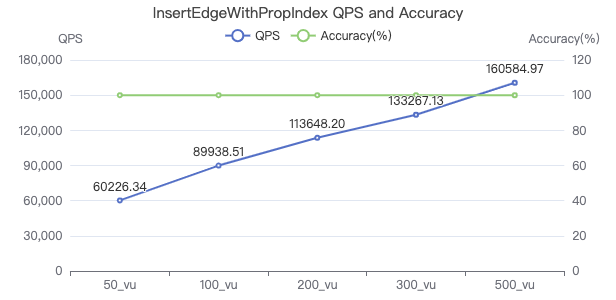
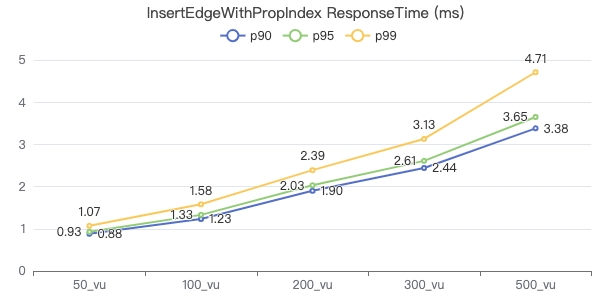
插入带索引的边
INSERT EDGE WORK_AT (workFrom) VALUES {0}→{1}:({2})
吞吐率
服务端耗时(ms)

客户端耗时(ms)
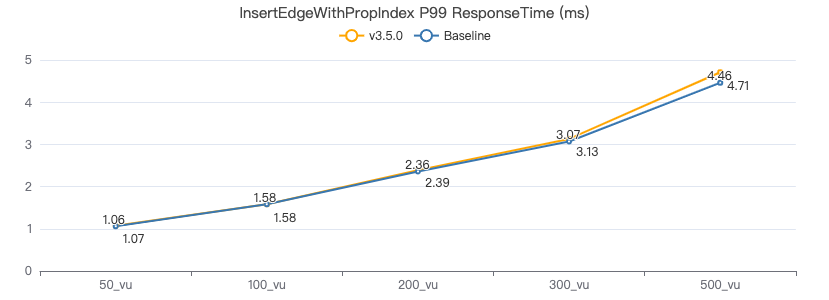
3.5.0 vs 3.4.0(Baseline)
以下数据选取 P99 值。
查询带边属性
GO {} STEP FROM {} OVER KNOWS yield KNOWS.creationDate
一跳·吞吐率
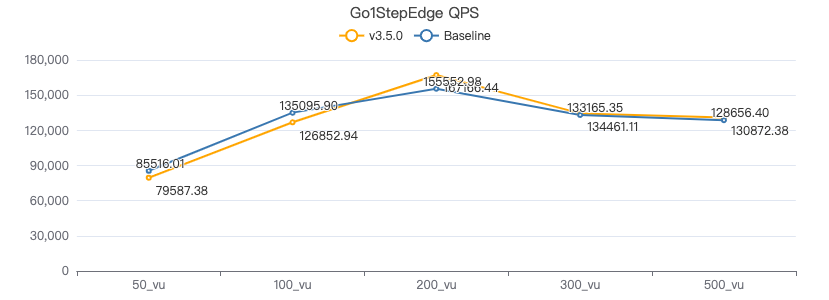
一跳·服务端耗时(ms)
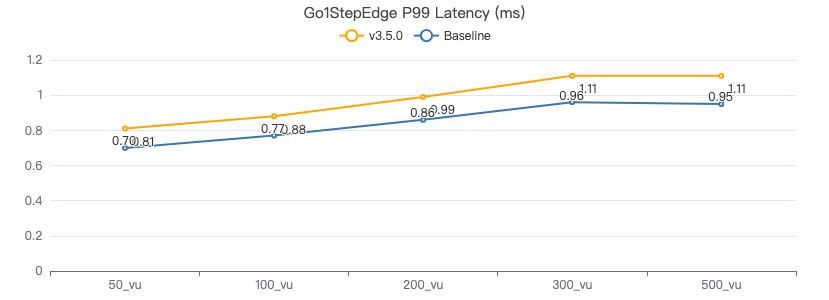
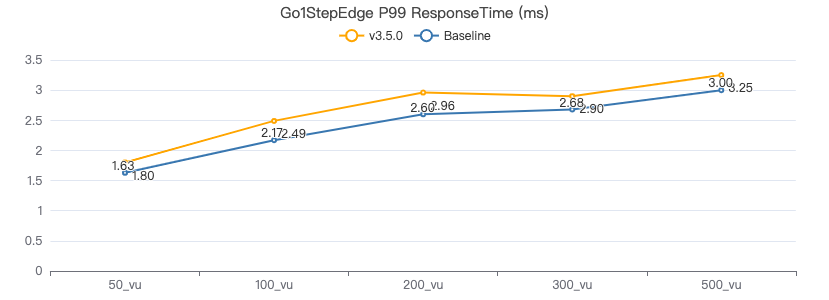
一跳·客户端耗时(ms)
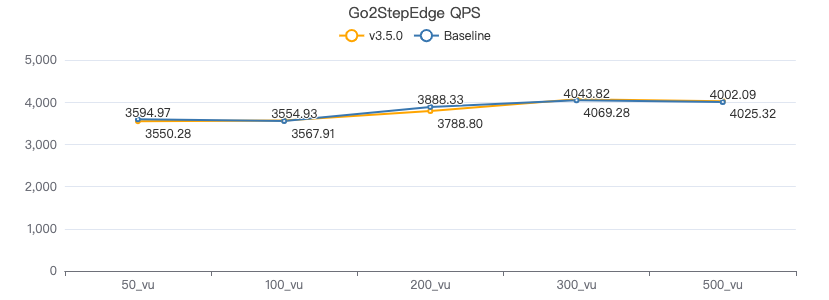
二跳·吞吐率
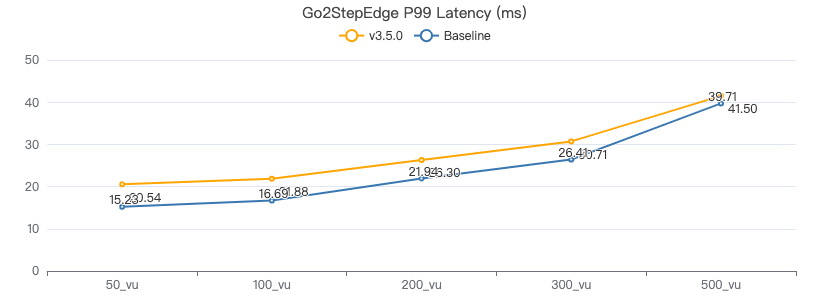
二跳·服务端耗时(ms)
二跳·客户端耗时(ms)
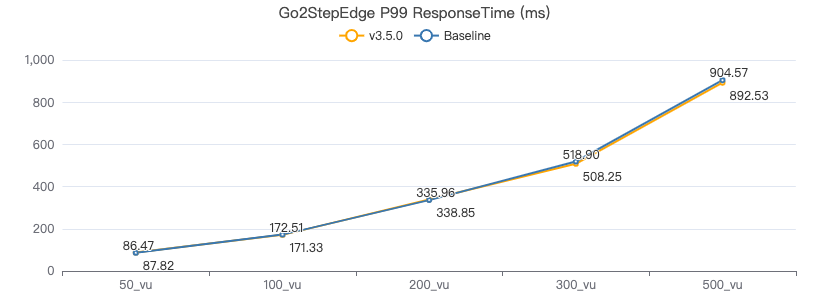
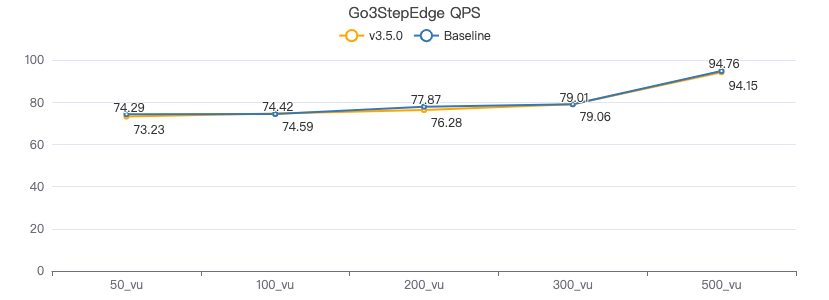
三跳·吞吐率
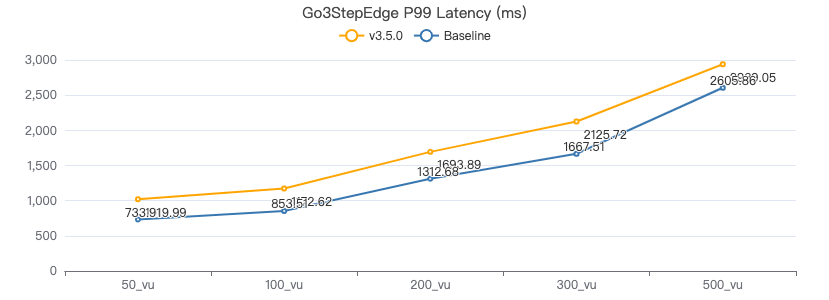
三跳·服务端耗时(ms)
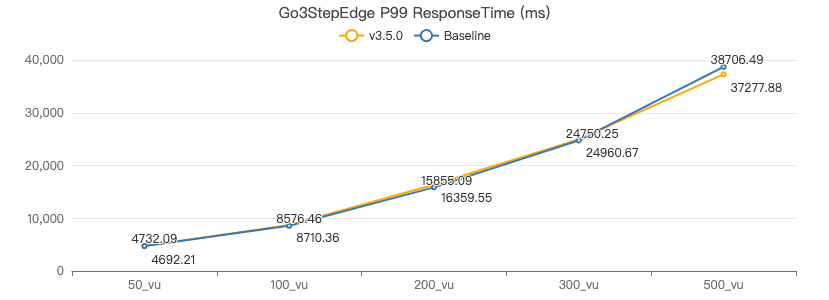
三跳·客户端耗时(ms)
查询带目的点属性
GO {} STEP FROM {} OVER KNOWS yield $$.Person.firstName
一跳·吞吐率
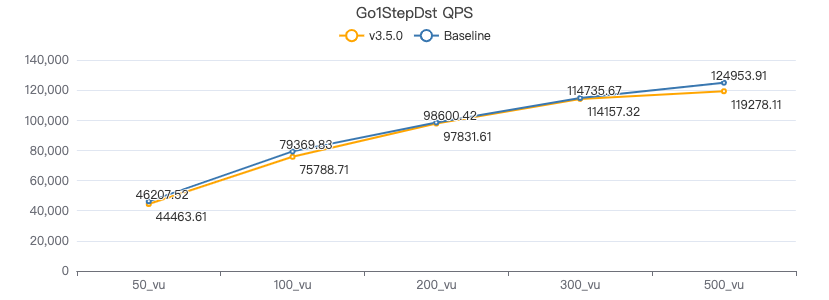
一跳·服务端耗时(ms)
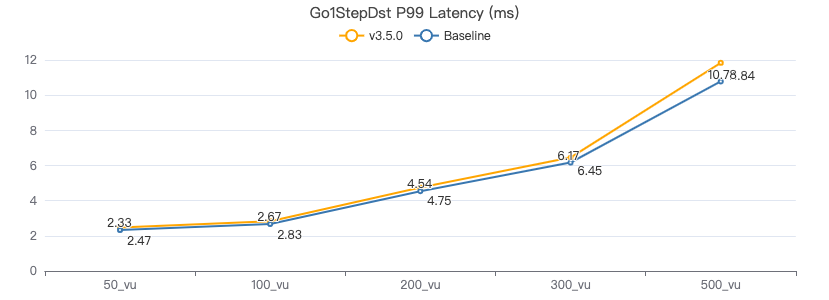
一跳·客户端耗时(ms)
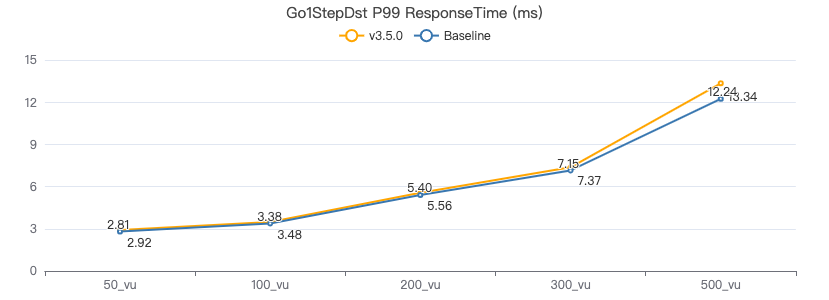
二跳·吞吐率
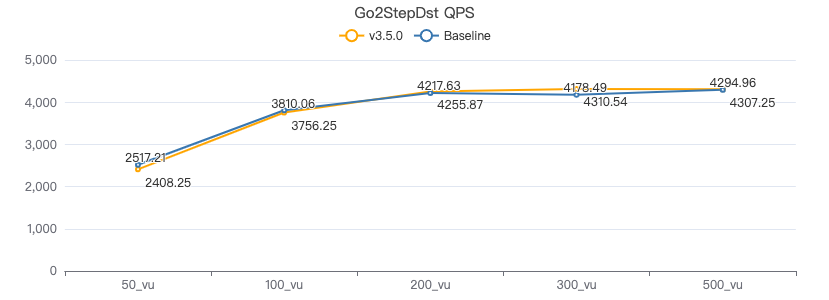
二跳·服务端耗时(ms)
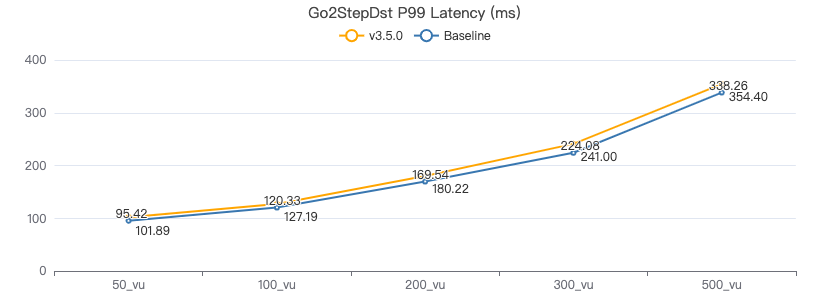
二跳·客户端耗时(ms)
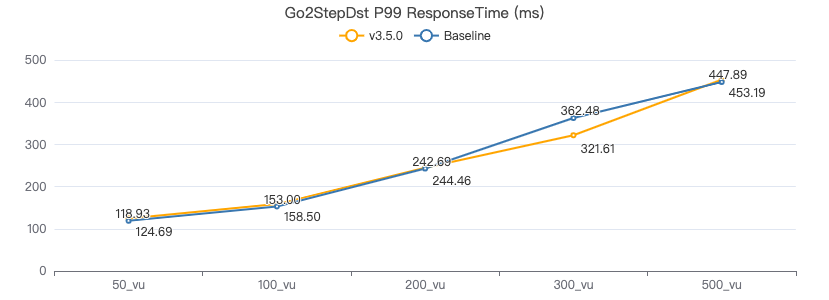
三跳·吞吐率
三跳·服务端耗时(ms)

三跳·客户端耗时(ms)
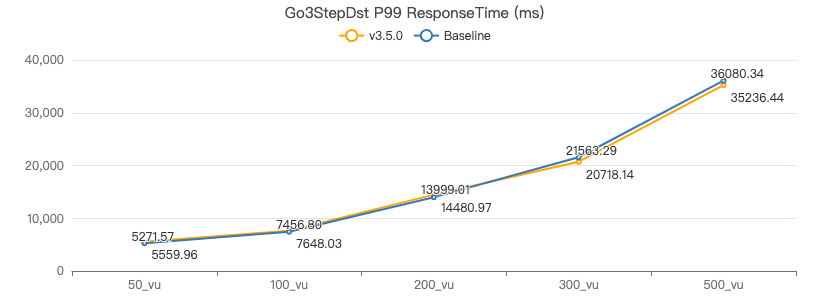
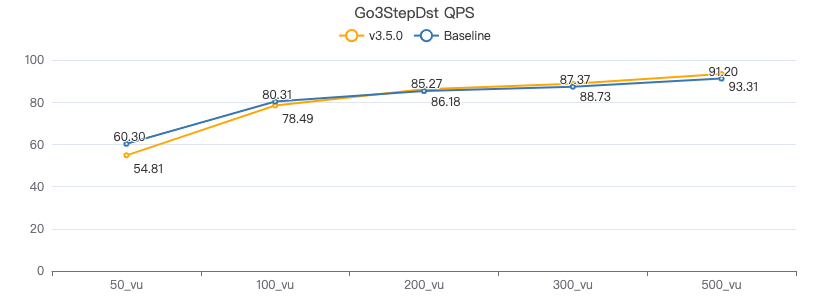
查询带边属性+目的点属性
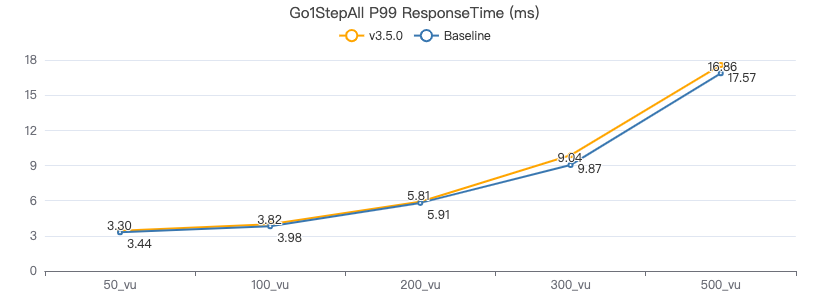
GO {} STEP FROM {} OVER KNOWS yield DISTINCT KNOWS.creationDate as t, $$.Person.firstName, $$.Person.lastName, $$.Person.birthday as birth | order by $-.t, $-.birth | limit 10
一跳·吞吐率
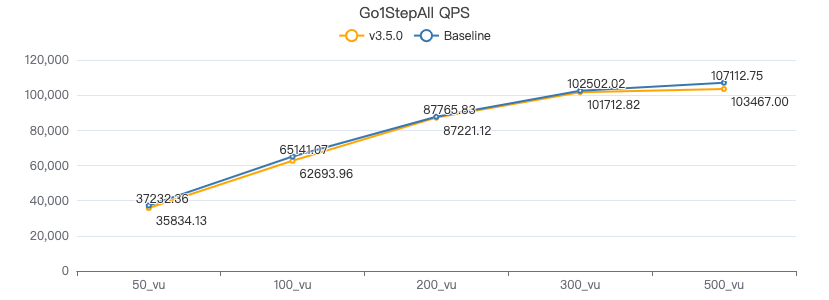
一跳·服务端耗时(ms)
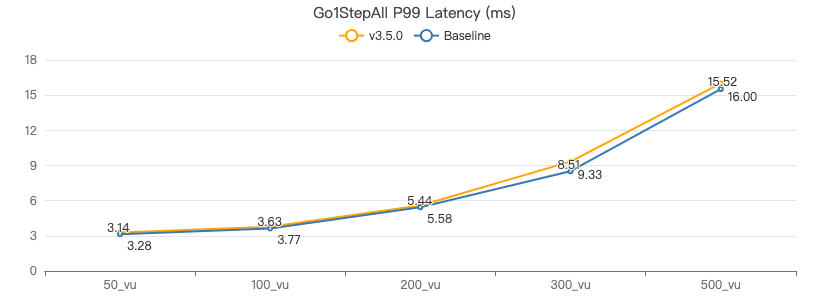
一跳·客户端耗时(ms)
二跳·吞吐率
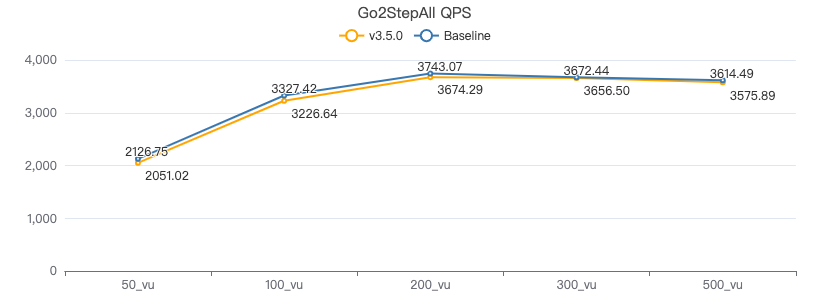
二跳·服务端耗时(ms)
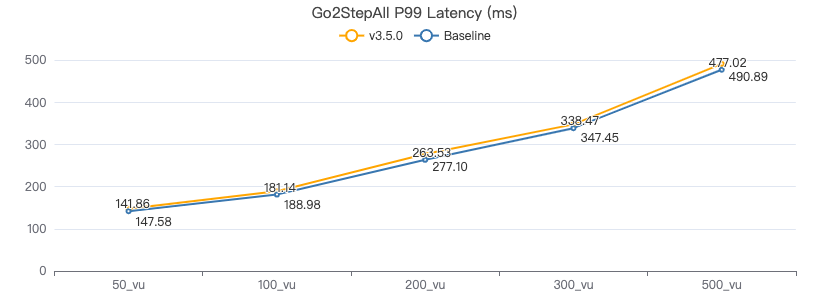
二跳·客户端耗时(ms)
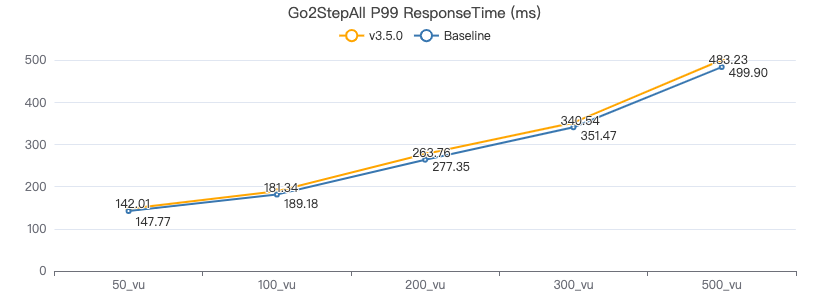
三跳·吞吐率
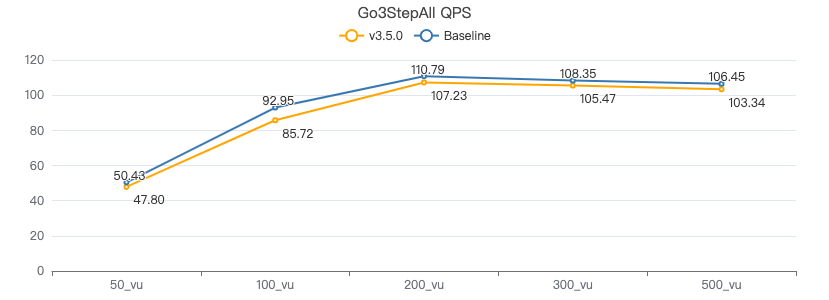
三跳·服务端耗时(ms)
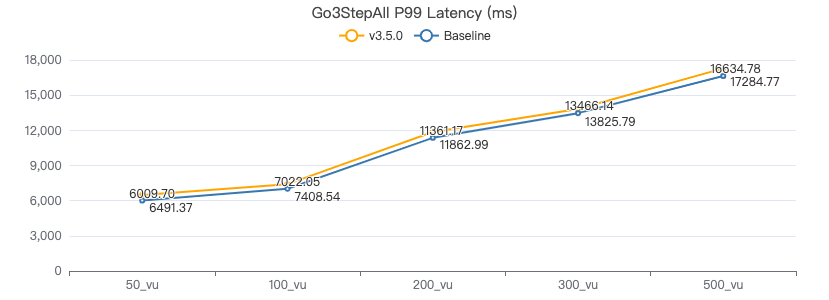
三跳·客户端耗时(ms)

LOOKUP
LOOKUP ON Person WHERE Person.firstName == '{}' YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed
LOOKUP·吞吐率
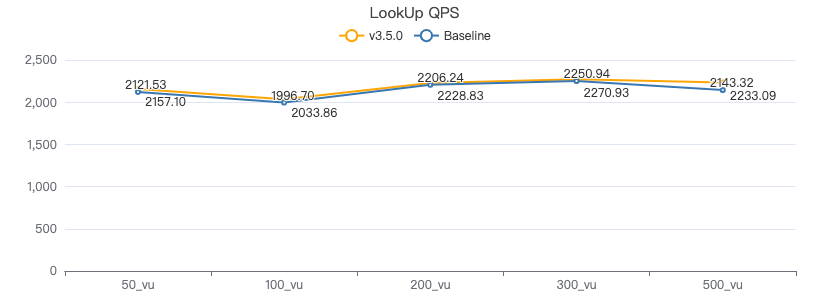
LOOKUP·服务端耗时(ms)

LOOKUP·客户端耗时(ms)
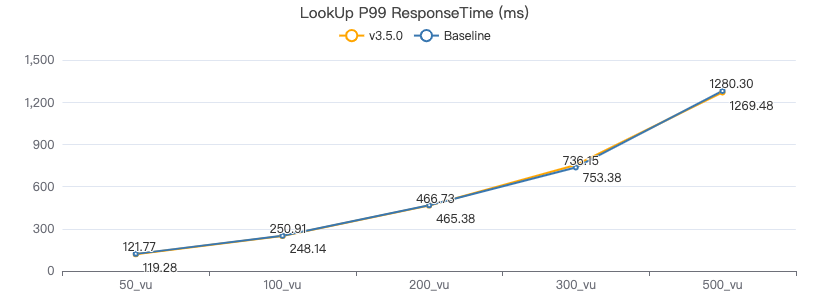
FETCH 点
FETCH PROP ON Person {} YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed
FETCH 点·吞吐率
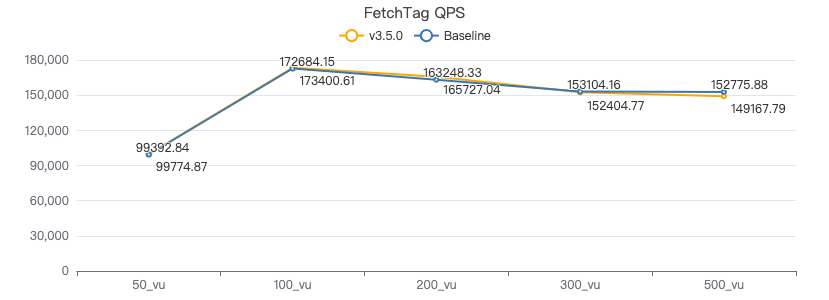
FETCH 点·服务端耗时(ms)
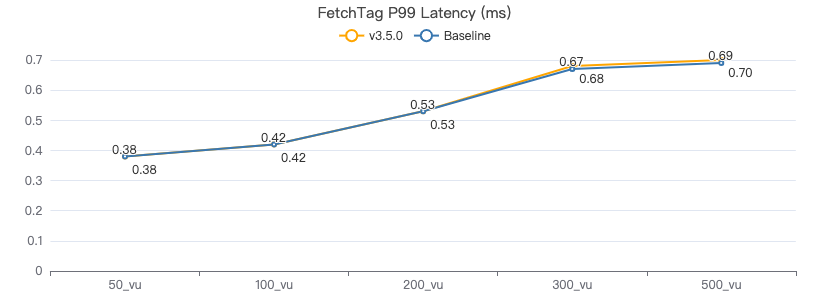
FETCH 点·客户端耗时(ms)

FETCH 边
FETCH PROP ON KNOWS {} -> {} YIELD KNOWS.creationDate
FETCH 边·吞吐率
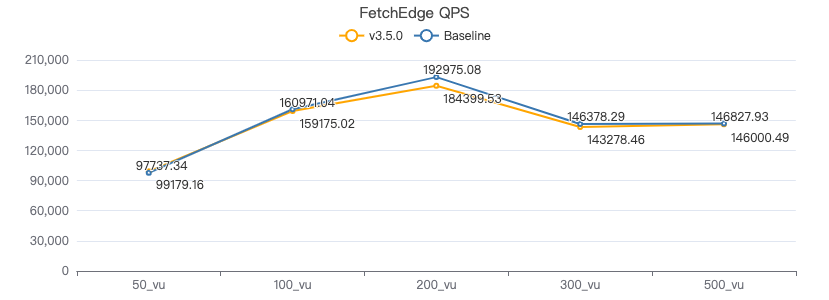
FETCH 边·服务端耗时(ms)
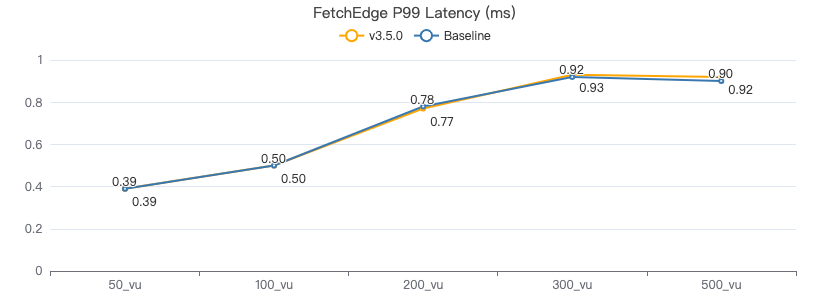
FETCH 边·客户端耗时(ms)
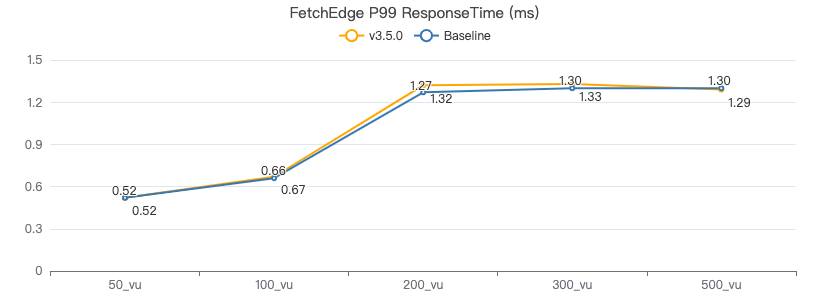
MATCH 索引
MATCH (v:Person) WHERE v.Person.firstName == '{}' RETURN v
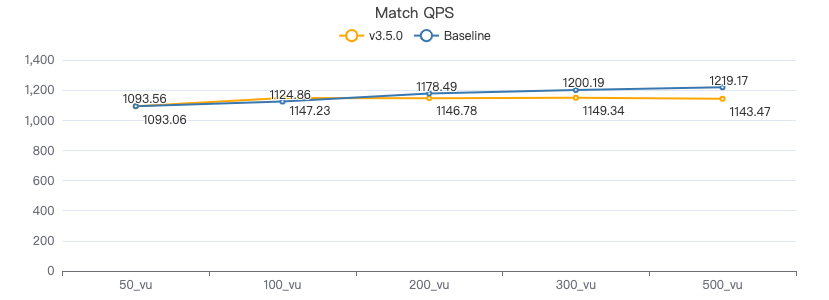
MATCH·吞吐率
MATCH·服务端耗时(ms)
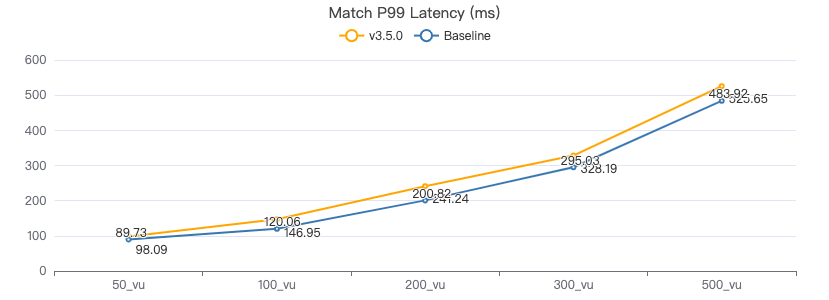
MATCH·客户端耗时(ms)
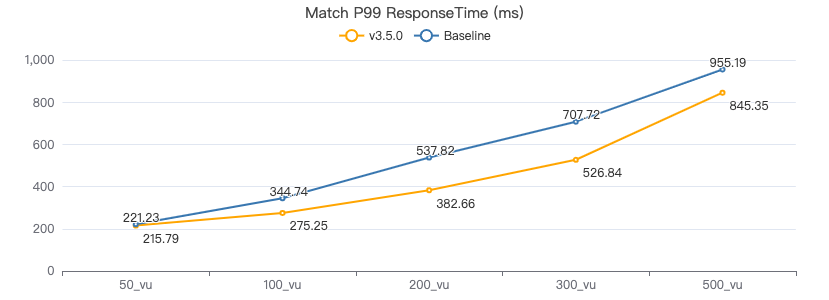
MATCH 一跳
MATCH (v1:Person)-[e:KNOWS]->(v2:Person) WHERE id(v1) == {} RETURN v2
MATCH 一跳·吞吐率
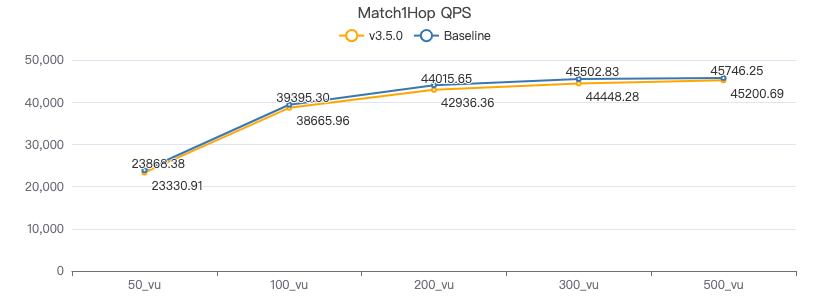
MATCH 一跳·服务端耗时(ms)
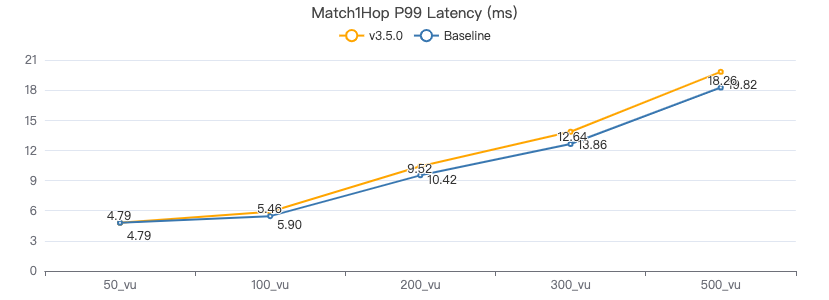
MATCH 一跳·客户端耗时(ms)

MATCH 两跳
MATCH (v1:Person)-[e:KNOWS*2]->(v2:Person) WHERE id(v1) == {} RETURN v2
MATCH 两跳·吞吐率
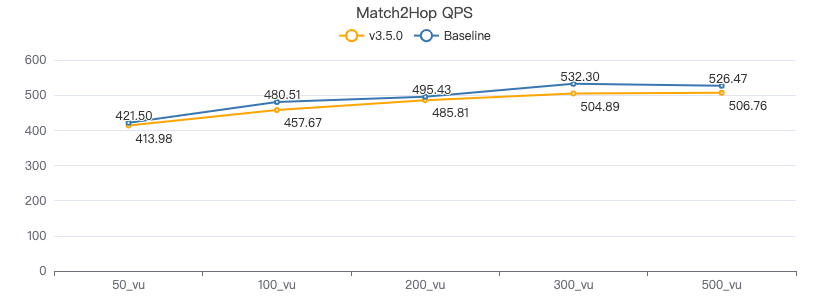
MATCH 两跳·服务端耗时(ms)
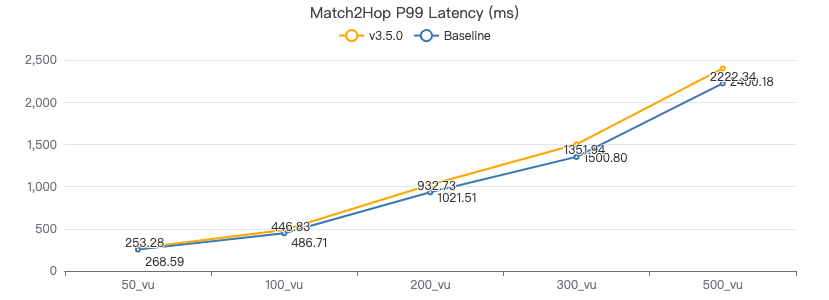
MATCH 两跳·客户端耗时(ms)
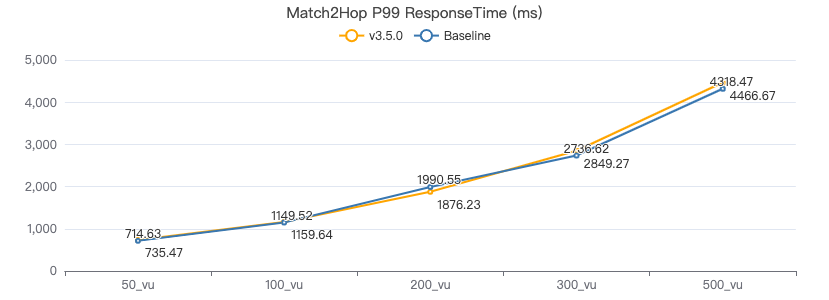
MatchTest1
match (v:Person) where id(v) == {} return count(v.Person.firstName)
吞吐率
服务端耗时(ms)
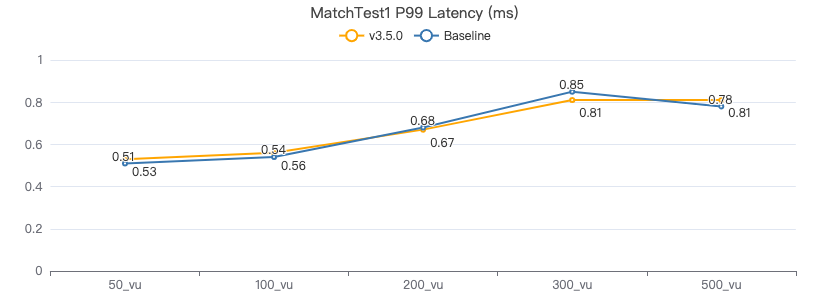
客户端耗时(ms)
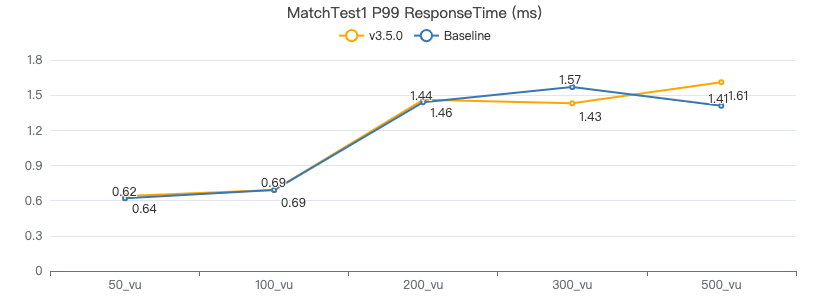
MatchTest2
match (v:Person)-[e:KNOWS]-(v2) where id(v) == {} and v2.Person.locationIP != 'yyy' return length(v.Person.browserUsed) + length(v2.Person.gender)
吞吐率
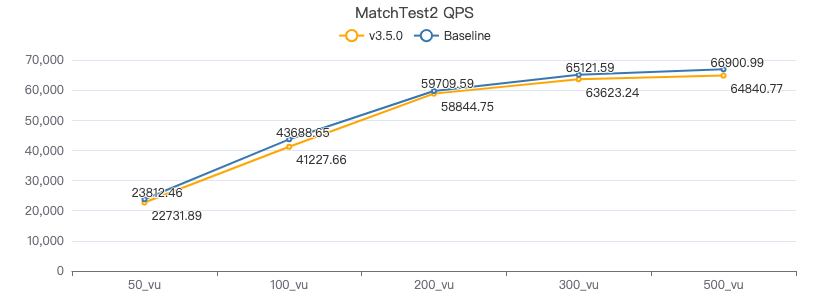
服务端耗时(ms)
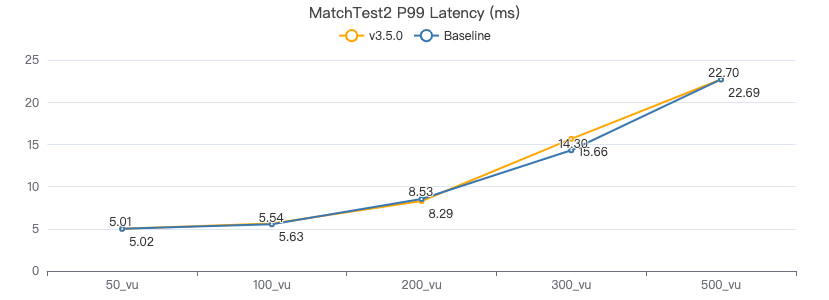
客户端耗时(ms)
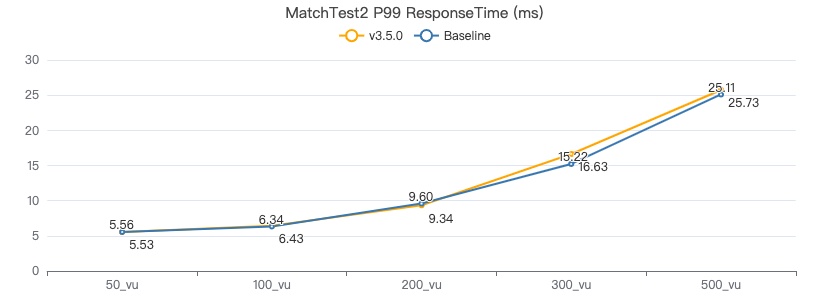
MatchTest3
match (v:Person)-[e:KNOWS]-(v2) where id(v) == {} and v2.Person.locationIP != 'yyy' with v, v2 as v3 return length(v.Person.browserUsed) + (v3.Person.gender)
吞吐率
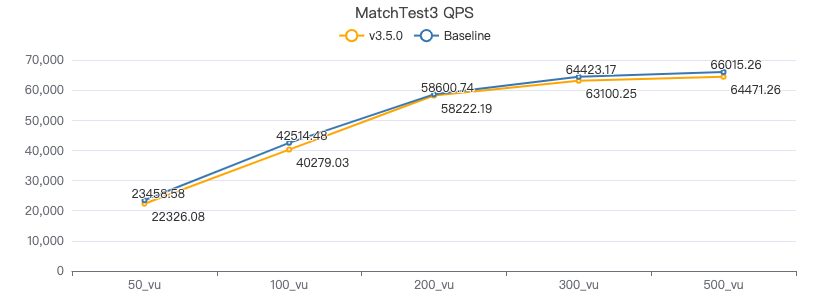
服务端耗时(ms)
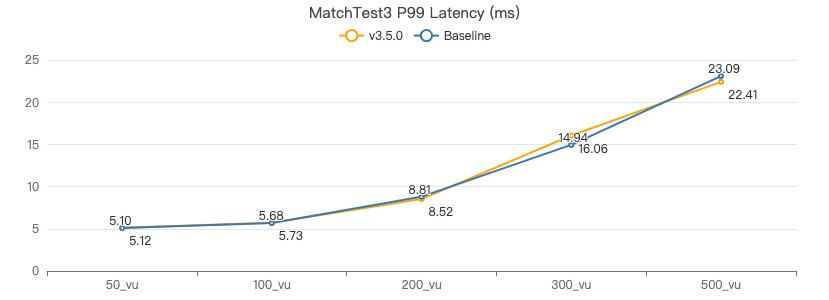
客户端耗时(ms)
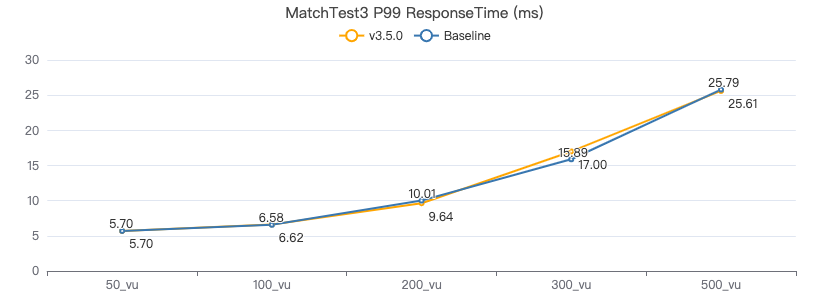
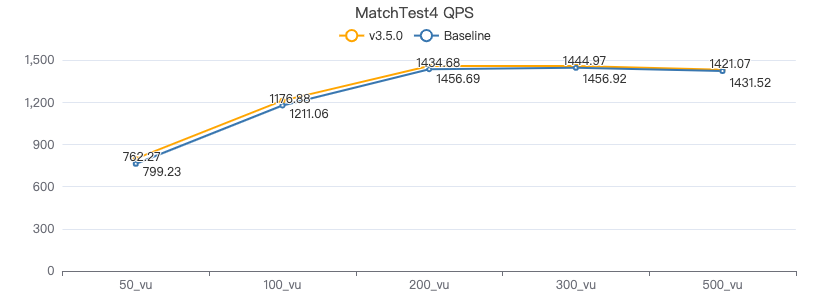
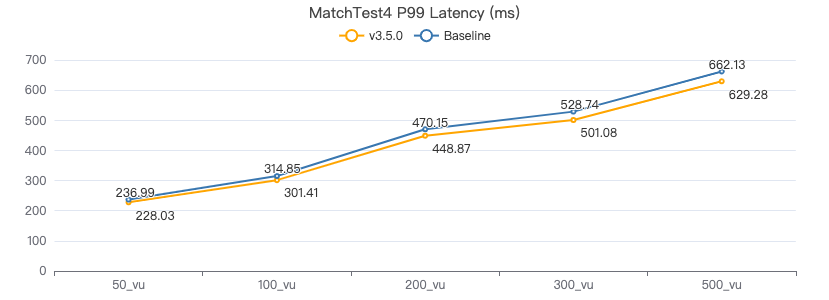
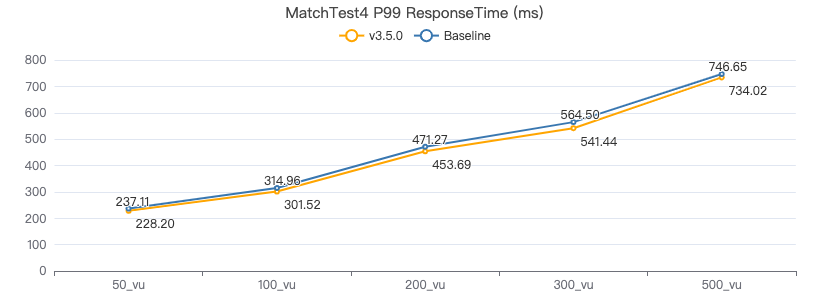
MatchTest4
MATCH (m)-[:KNOWS]-(n) WHERE id(m)=={} OPTIONAL MATCH (n)<-[:KNOWS]-(l) RETURN length(m.Person.lastName) AS n1, length(n.Person.lastName) AS n2, l.Person.creationDate AS n3 ORDER BY n1, n2, n3 LIMIT 10
吞吐率
服务端耗时(ms)
客户端耗时(ms)
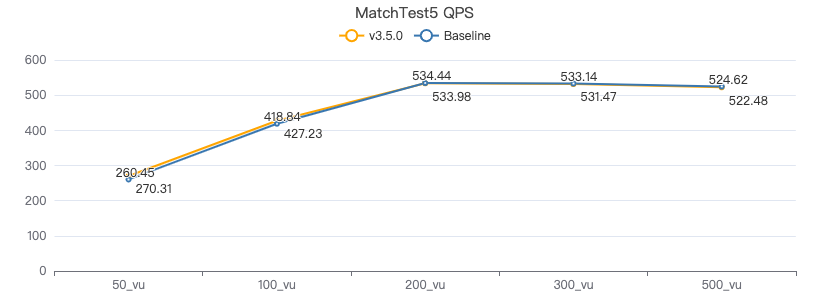
MatchTest5
MATCH (m)-[:KNOWS]-(n) WHERE id(m)=={} MATCH (n)-[:KNOWS]-(l) WITH m AS x, n AS y, l RETURN x.Person.firstName AS n1, y.Person.firstName AS n2, CASE WHEN l.Person.firstName is not null THEN l.Person.firstName WHEN l.Person.gender is not null THEN l.Person.birthday ELSE 'null' END AS n3 ORDER BY n1, n2, n3 LIMIT 10
吞吐率
服务端耗时(ms)
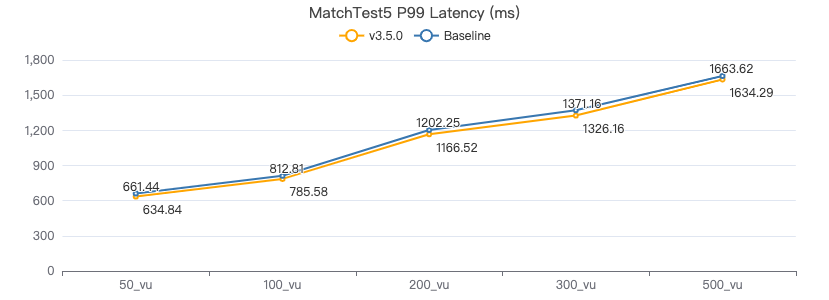
客户端耗时(ms)
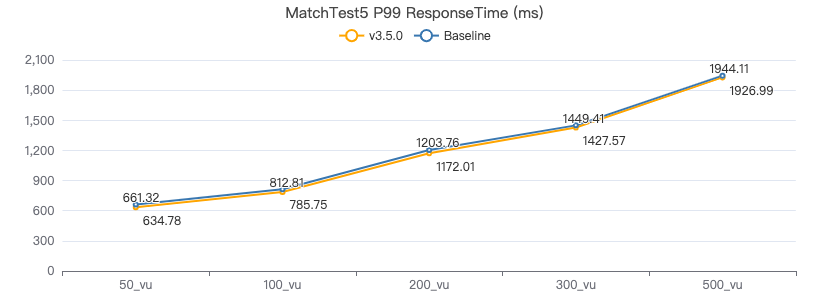
查询带边属性 count
GO {} STEP FROM {} OVER KNOWS yield KNOWS.creationDate | return count(*) ;
一跳·吞吐率
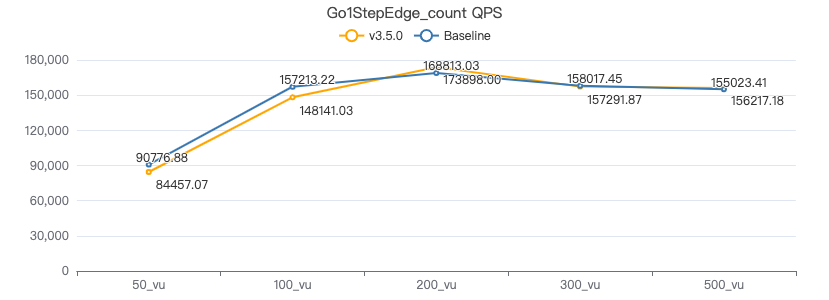
一跳·服务端耗时(ms)
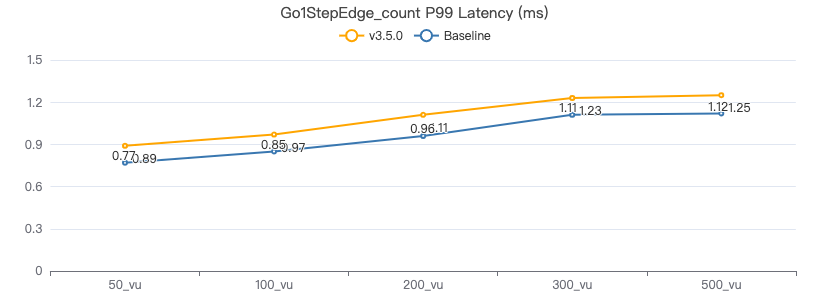
一跳·客户端耗时(ms)
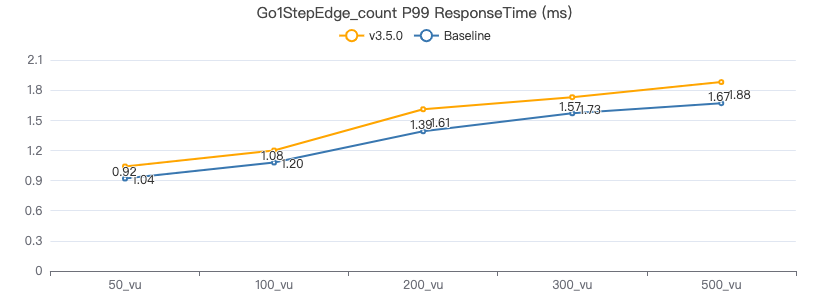
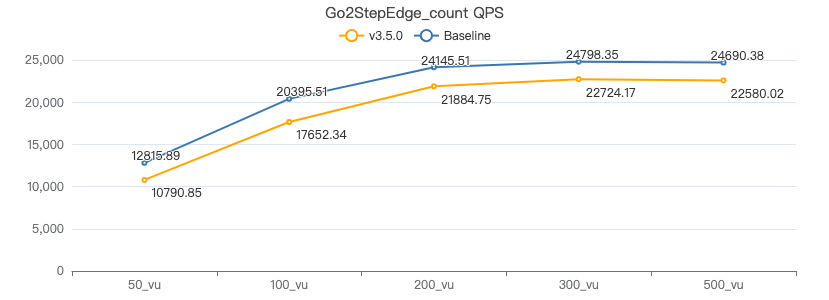
二跳·吞吐率
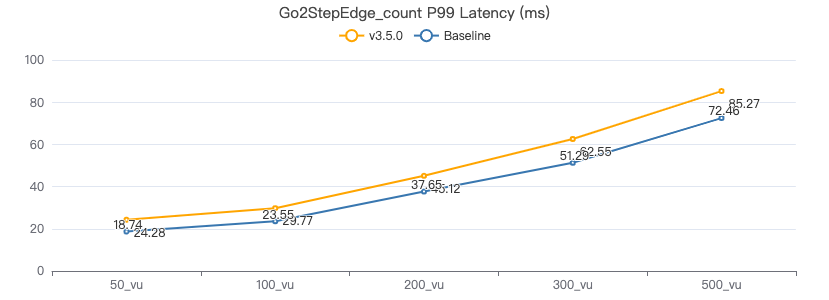
二跳·服务端耗时(ms)
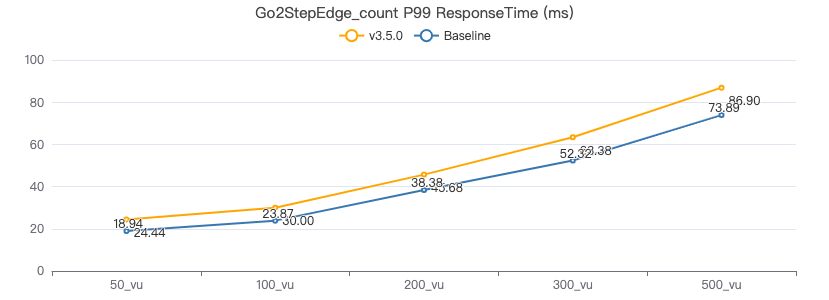
二跳·客户端耗时(ms)
三跳·吞吐率
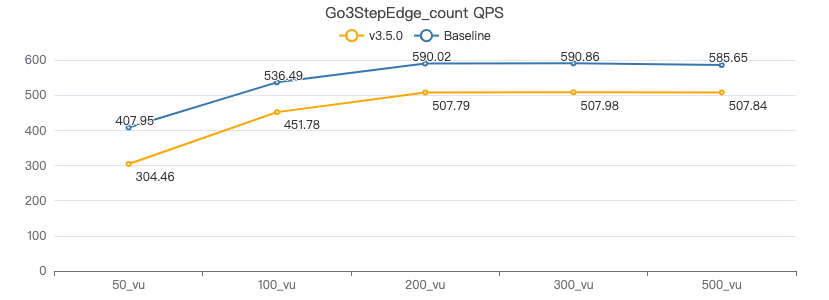
三跳·服务端耗时(ms)
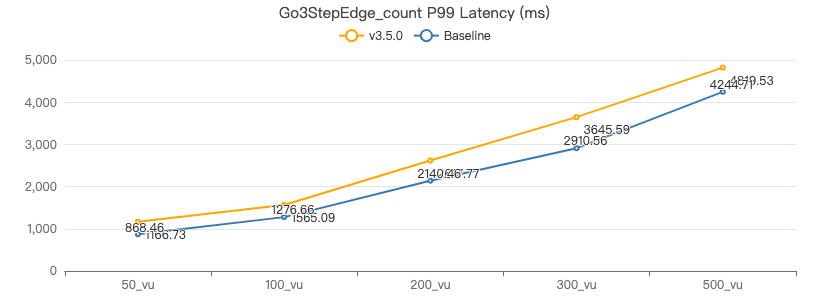
三跳·客户端耗时(ms)
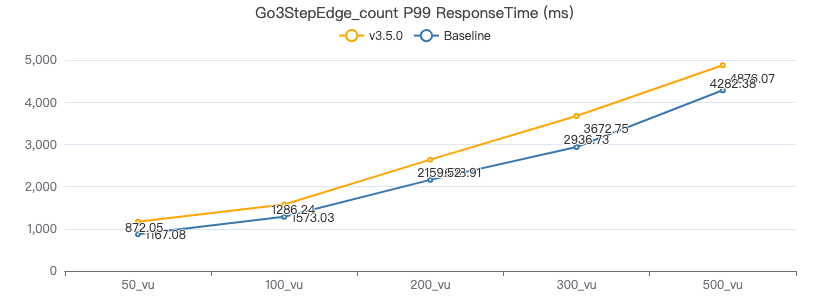
查询带目的点属性 count
GO 1 STEP FROM {} OVER KNOWS yield $$.Person.firstName | return count(*)
一跳·吞吐率
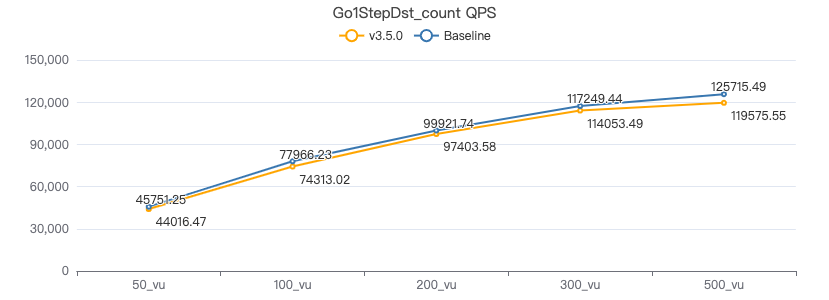
一跳·服务端耗时(ms)
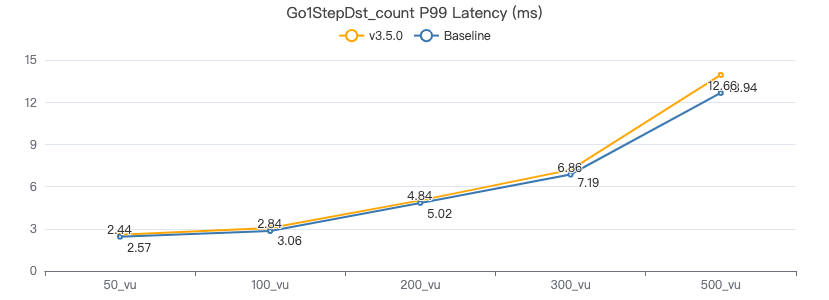
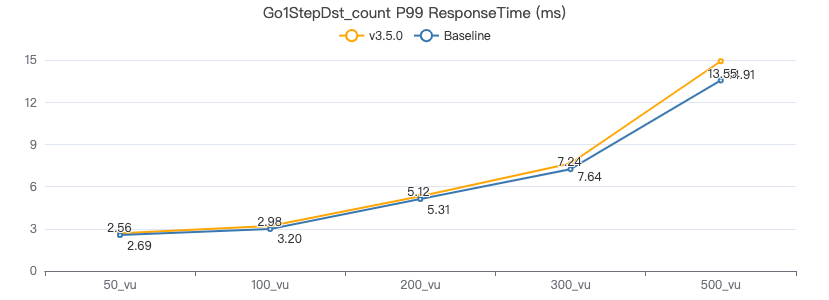
一跳·客户端耗时(ms)
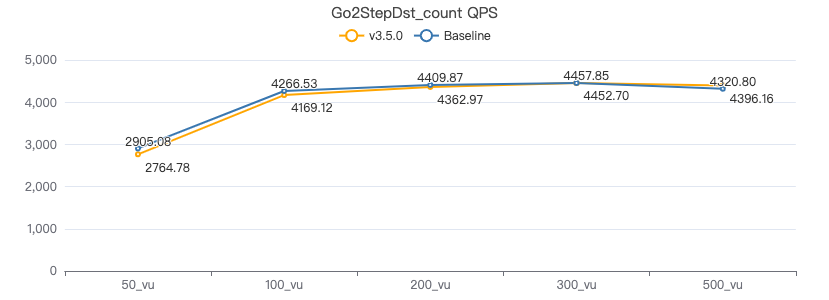
二跳·吞吐率
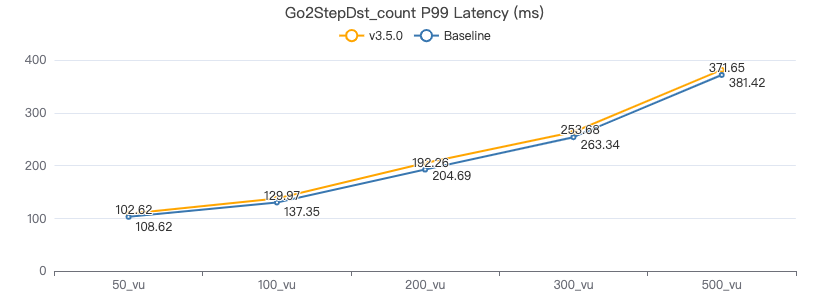
二跳·服务端耗时(ms)
二跳·客户端耗时(ms)
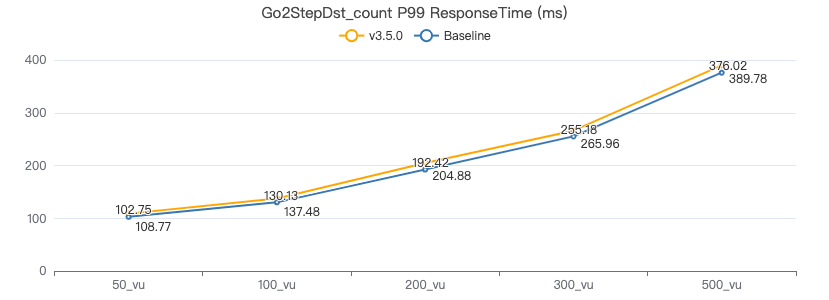
三跳·吞吐率
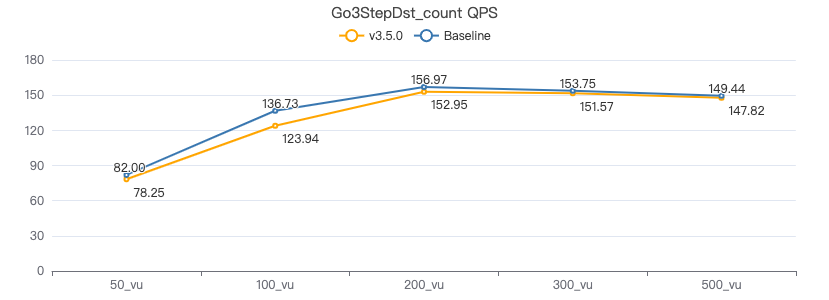
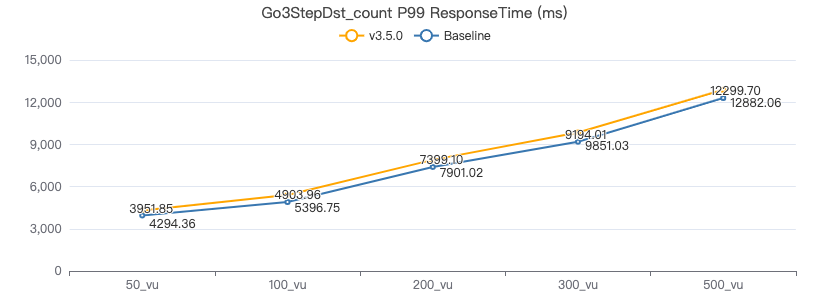
三跳·服务端耗时(ms)

三跳·客户端耗时(ms)
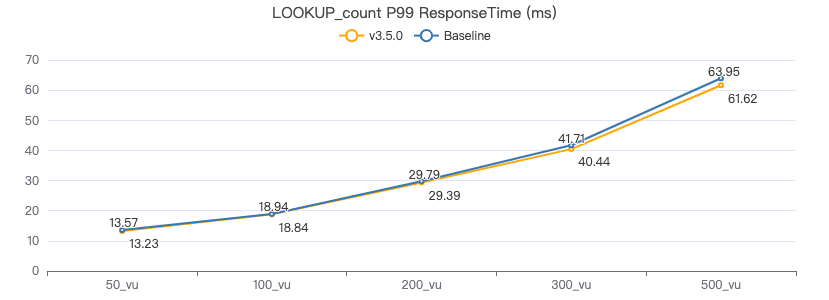
LOOKUP count
LOOKUP ON Person WHERE Person.firstName == '{}' YIELD Person.firstName | count(*)
吞吐率
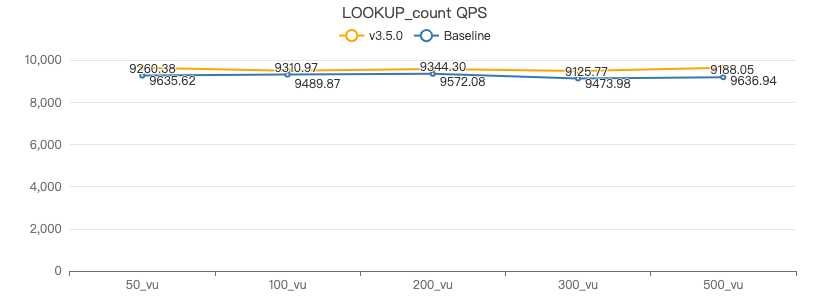
服务端耗时(ms)
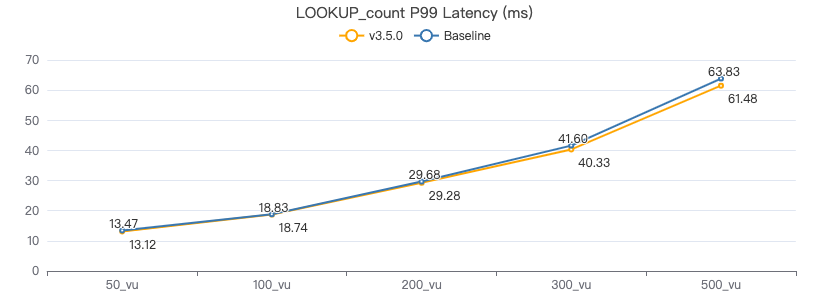
客户端耗时(ms)
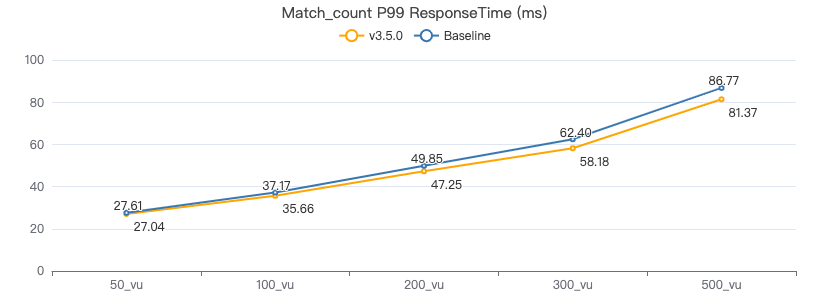
MATCH count
MATCH (v:Person) WHERE v.Person.firstName == '{}' RETURN count(*)
吞吐率

服务端耗时(ms)
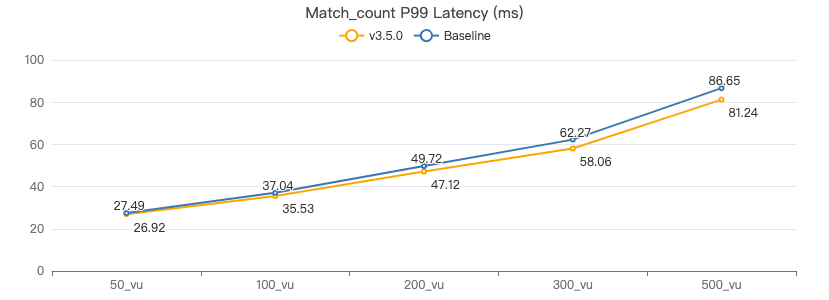
客户端耗时(ms)
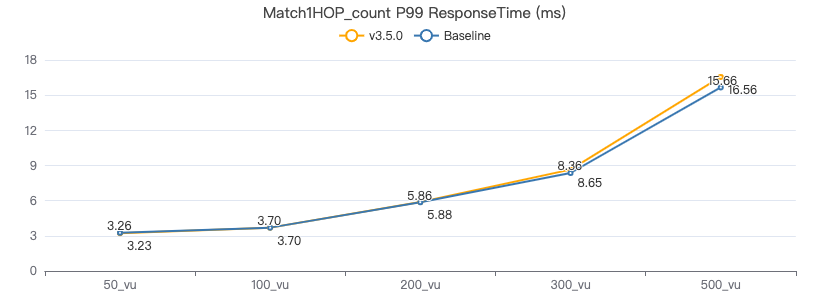
MATCH 一跳 count
MATCH (v1:Person)-[e:KNOWS]->(v2:Person) WHERE id(v1) == {} RETURN count(*)
吞吐率
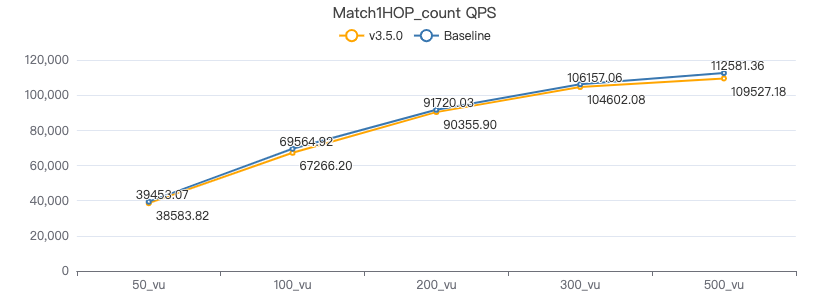
服务端耗时(ms)
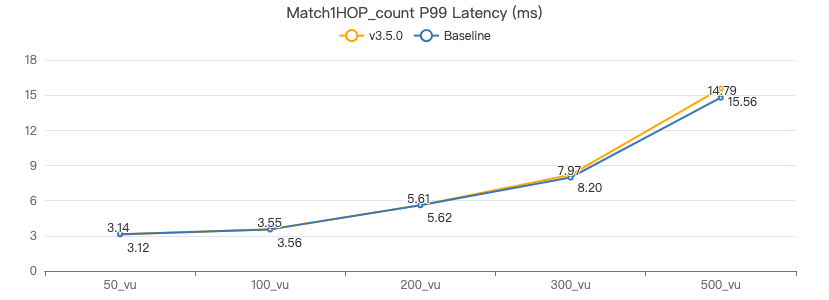
客户端耗时(ms)
MATCH 两跳 count
MATCH (v1:Person)-[e:KNOWS*2]->(v2:Person) WHERE id(v1) == {} RETURN count(*)
吞吐率
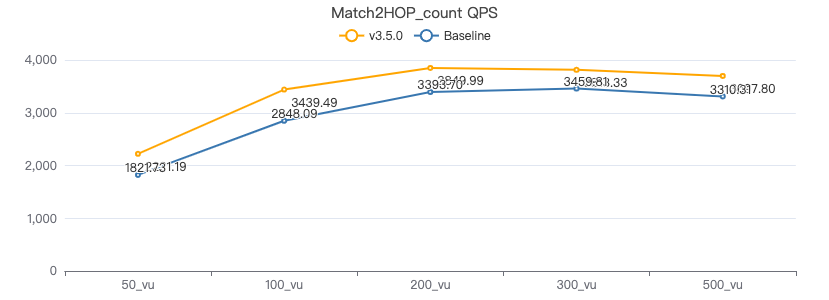
服务端耗时(ms)
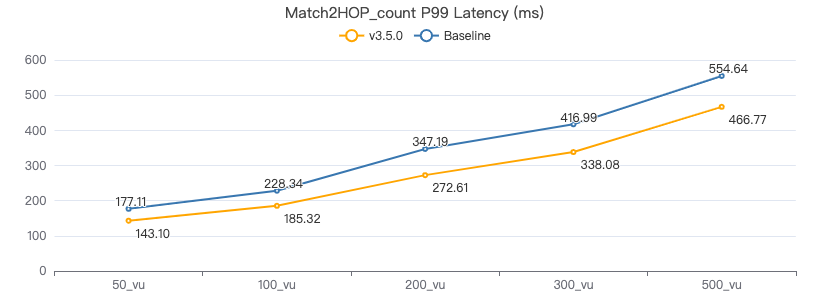
客户端耗时(ms)
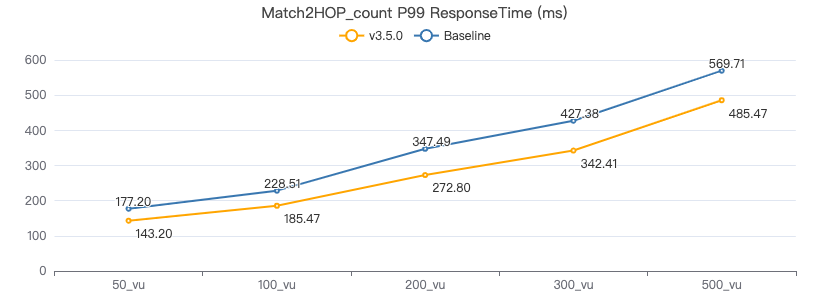
插入点
INSERT VERTEX Comment (creationDate, locationIP, browserUsed, content, length) VALUES {}:('{}', '{}', '{}', '{}', {})
吞吐率

服务端耗时(ms)
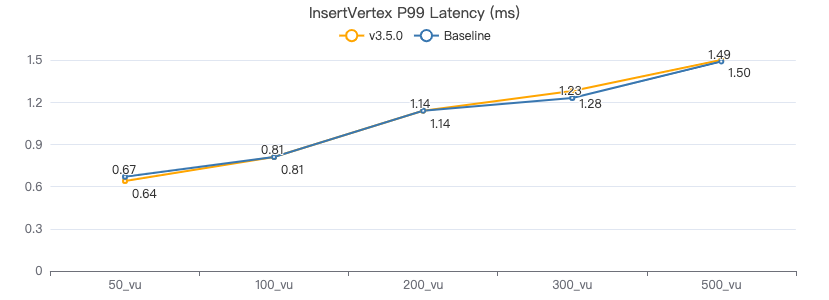
客户端耗时(ms)
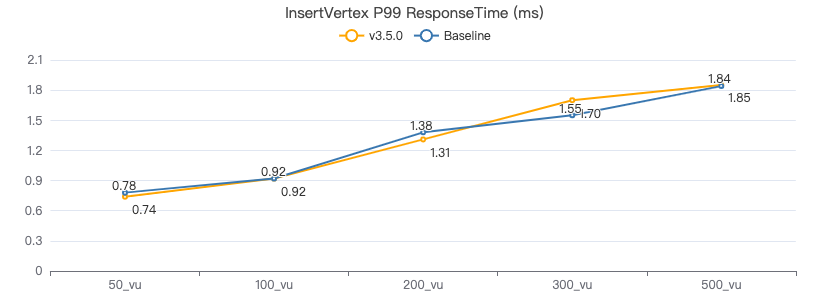
插入边
INSERT EDGE LIKES (creationDate) VALUES {}→{}:('{}')
吞吐率
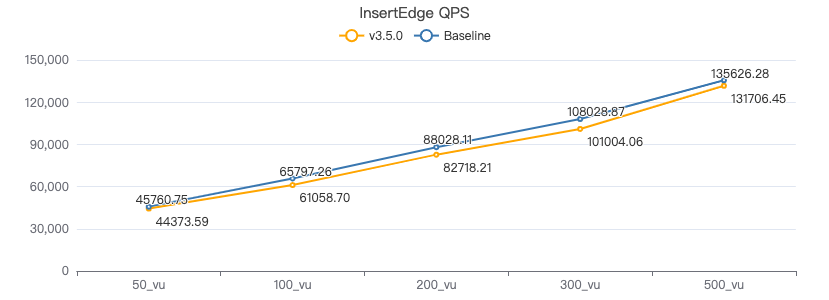
服务端耗时(ms)
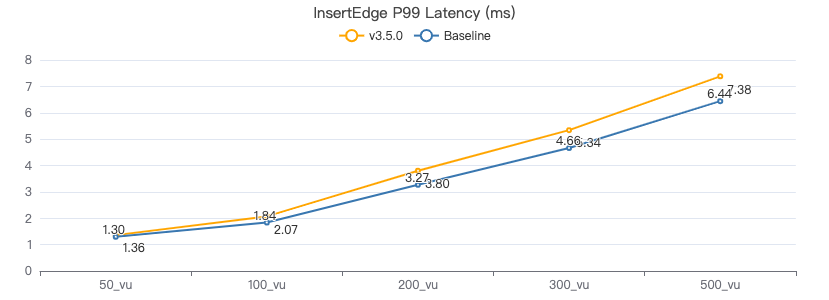
客户端耗时(ms)
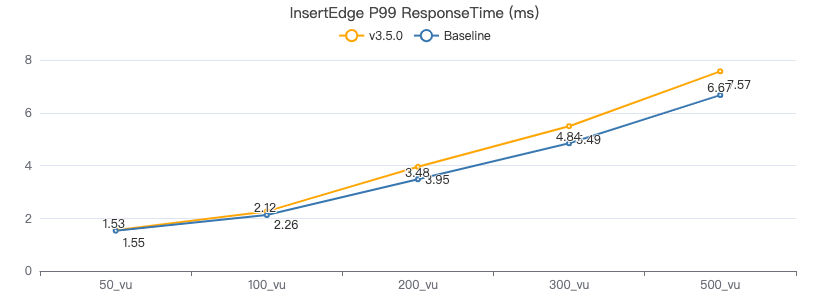
插入带索引的点
INSERT VERTEX Person (firstName,lastName,gender,birthday,creationDate,locationIP,browserUsed) VALUES {0}:(\"{1}\", \"{2}\",\"{3}\",\"{4}\",datetime(\"{5}\"), \"{6}\",\"{7}\")
吞吐率
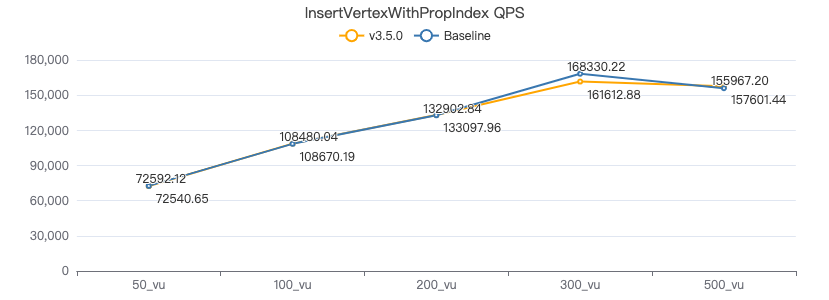
服务端耗时(ms)
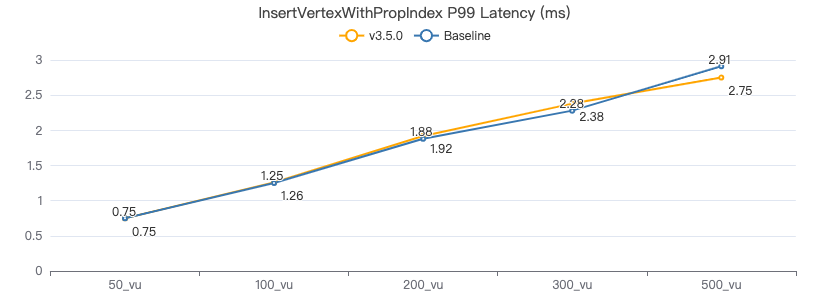
客户端耗时(ms)
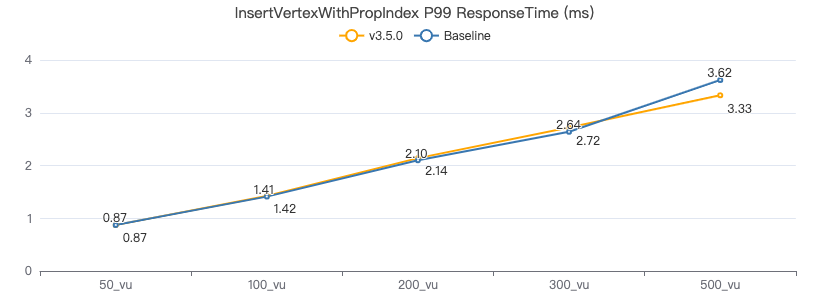
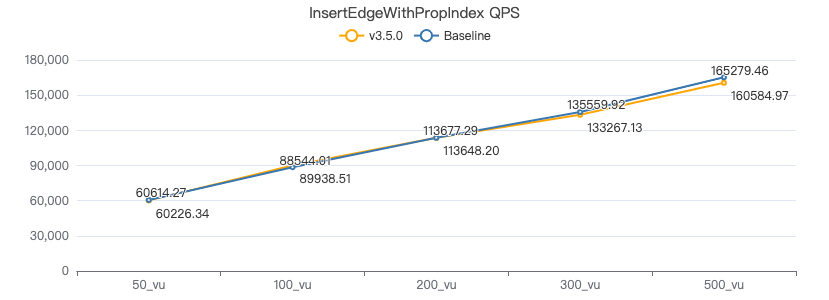
插入带索引的边
INSERT EDGE WORK_AT (workFrom) VALUES {0}→{1}:({2})
吞吐率
服务端耗时(ms)
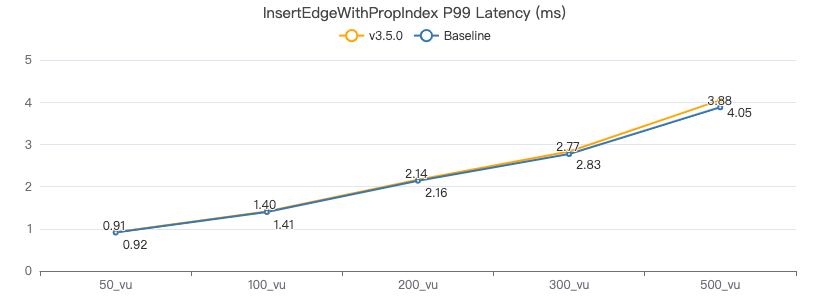
客户端耗时(ms)
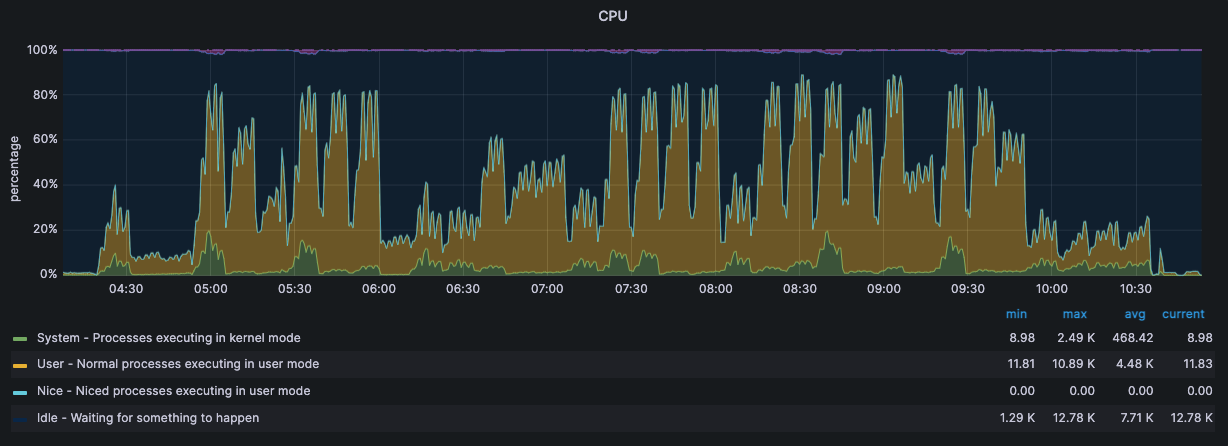
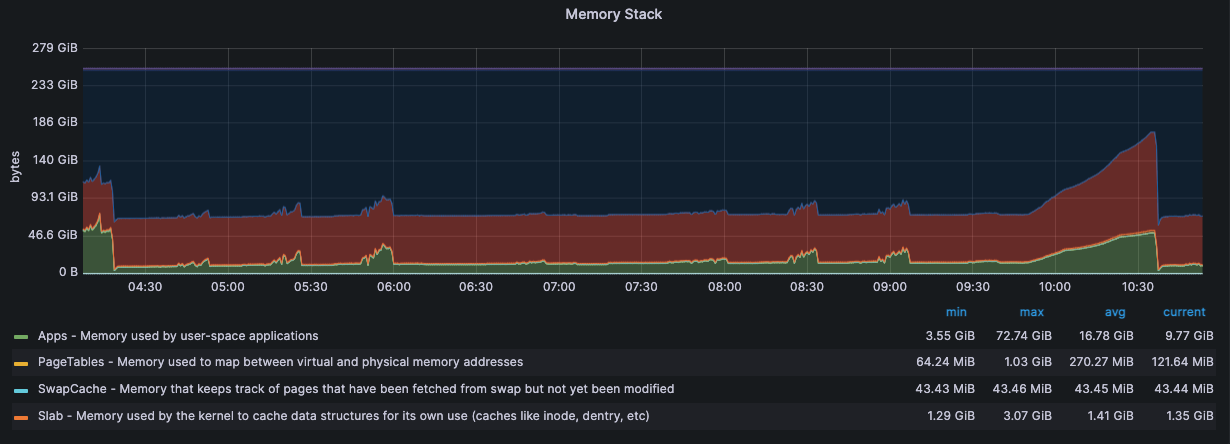
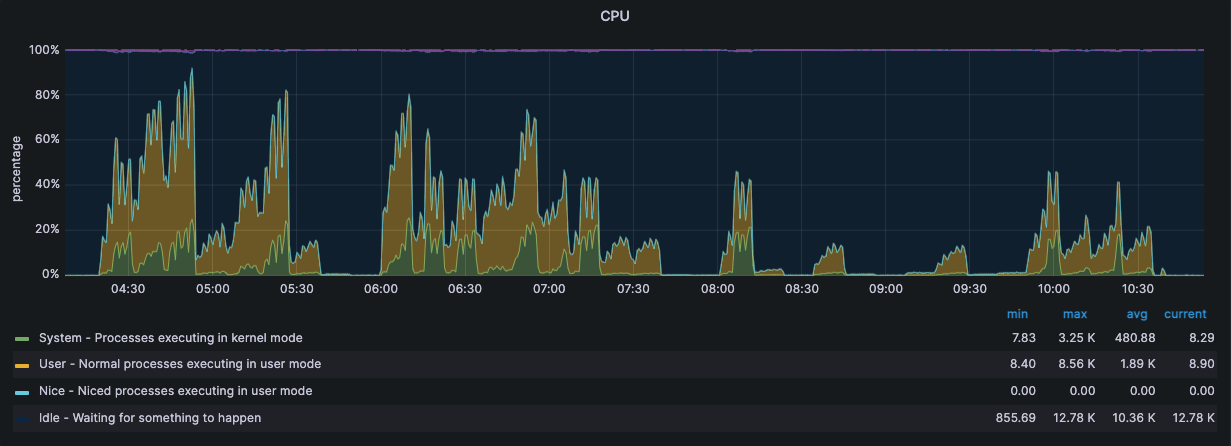
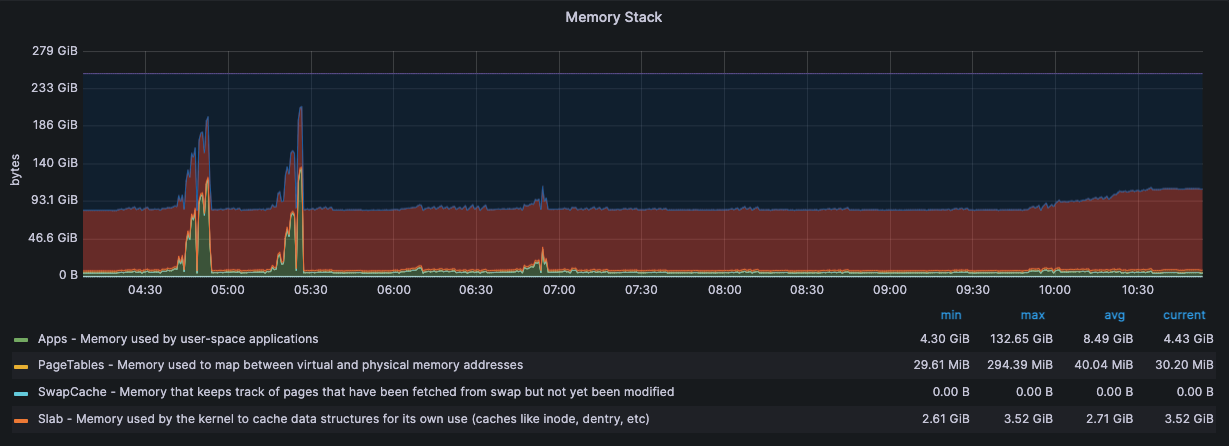
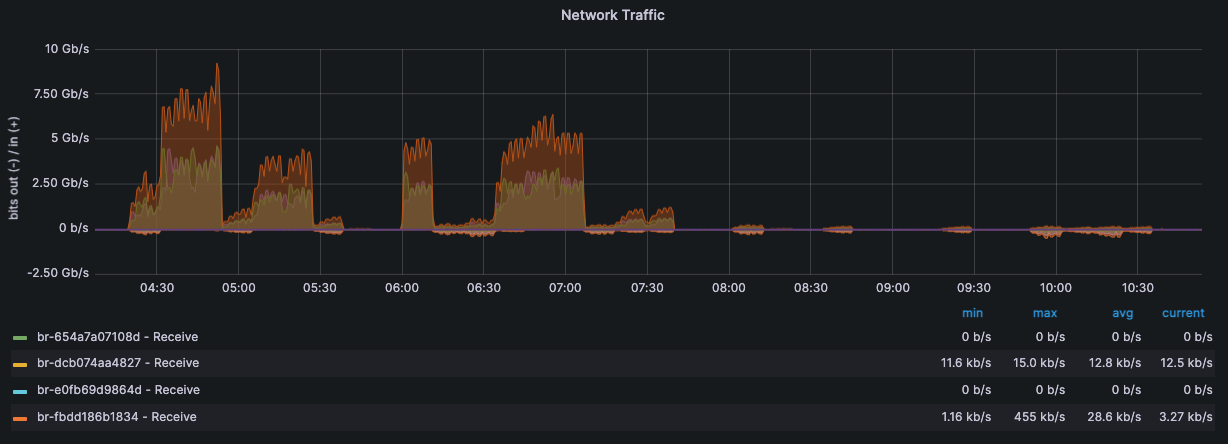
监控·服务器状态
192.168.15.8


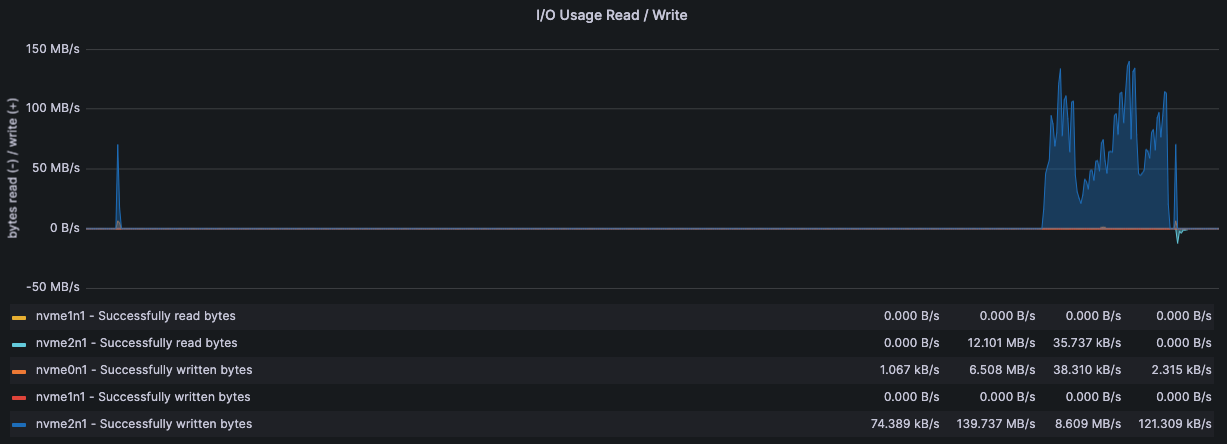
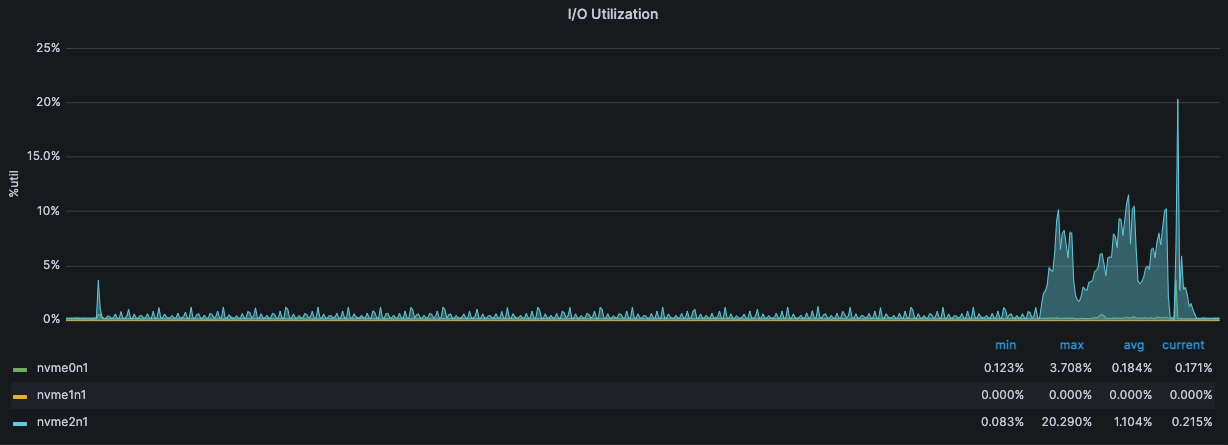
192.168.15.9


192.168.15.10

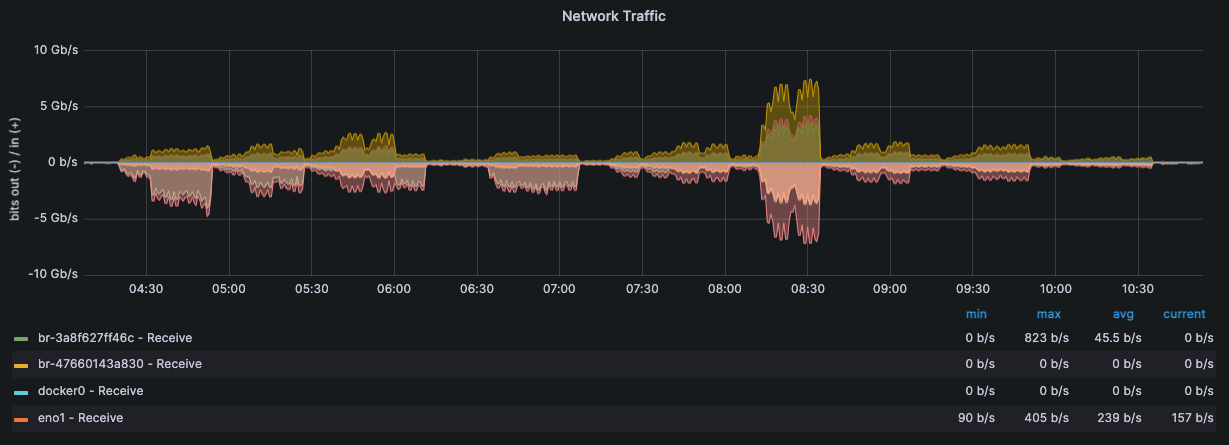
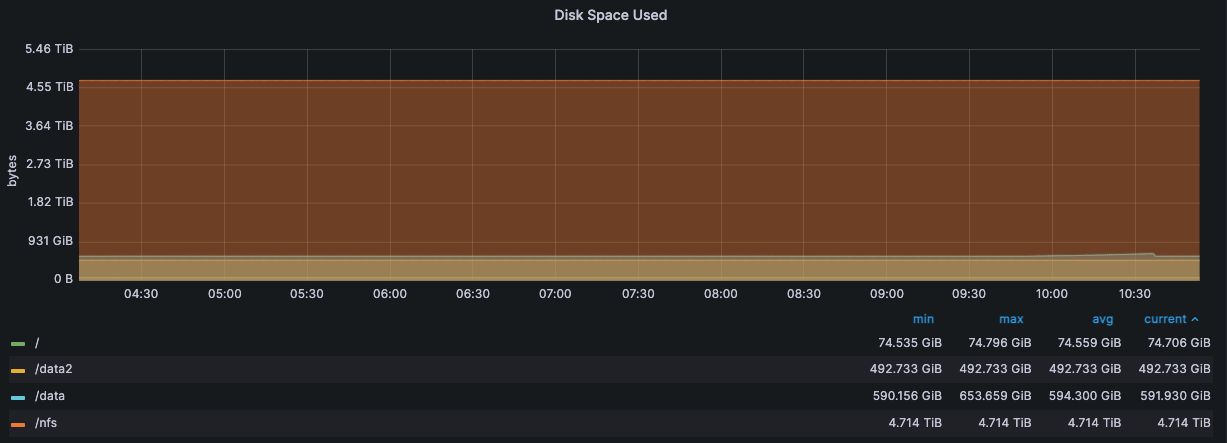
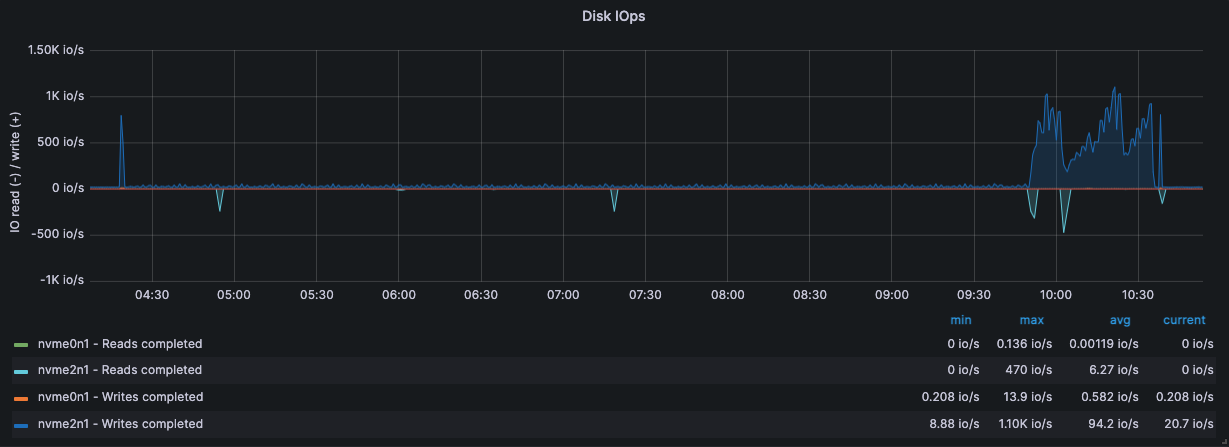
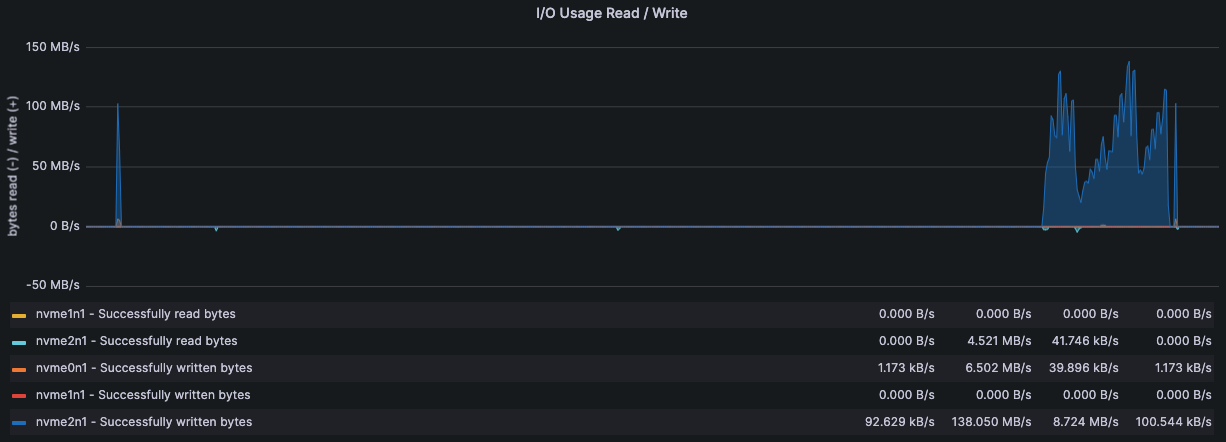
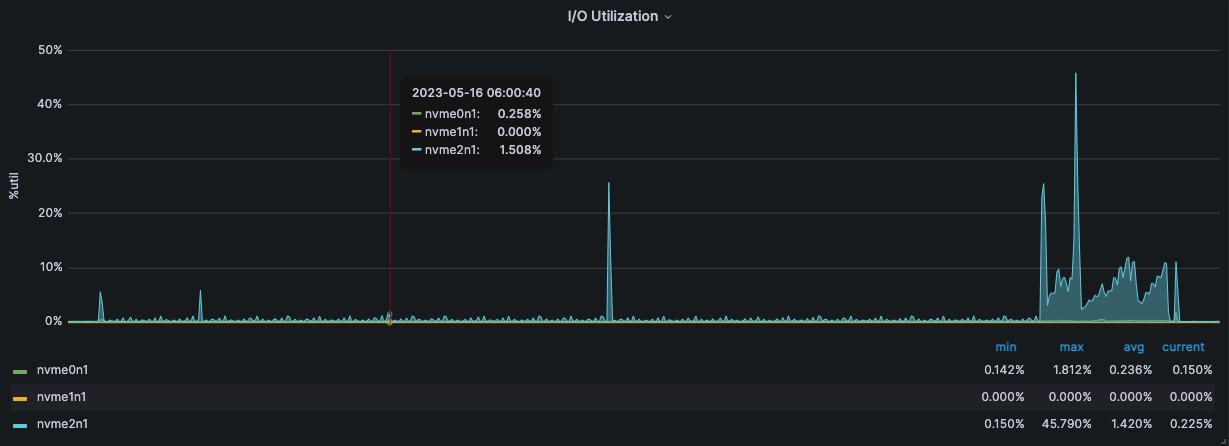
压测机 192.168.15.14
谢谢你读完本文 (///▽///)
欢迎你前往 GitHub 体验 NebulaGraph v3.5.0:https://github.com/vesoft-inc/nebula/releases/tag/v3.5.0