我执行ingest的时候,好像没有日志 只能看到任务状态
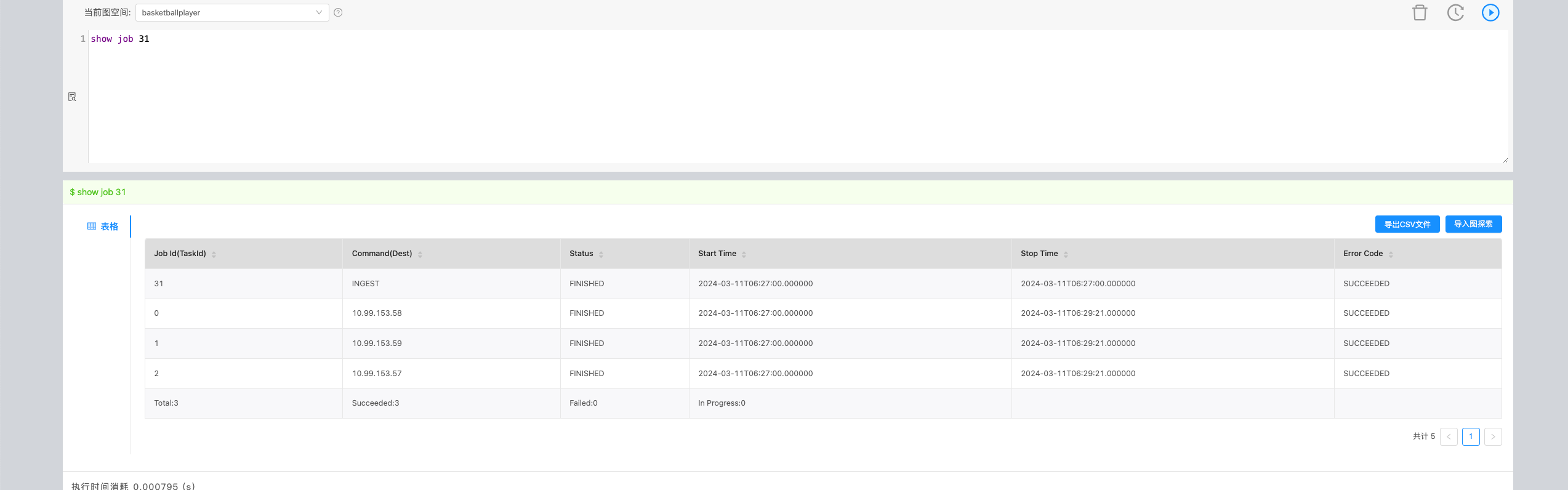
storage 没有日志么?
我根据ingest关键字搜索,没有日志打印出来
{
# Spark 相关配置
spark: {
app: {
name: Nebula Exchange 3.0.0
}
master:local
driver: {
cores: 1
maxResultSize: 1G
}
executor: {
memory:1G
}
cores:{
max: 16
}
}
# NebulaGraph 相关配置
nebula: {
address:{
graph:["10.99.153.xx:9669"]
meta:["10.99.153.xx:9559"]
}
user: root
pswd: xxxx
space: xxxx
# SST 文件相关配置
path:{
# 本地临时存放生成的 SST 文件的目录
local:"/tmp"
# SST 文件在 HDFS 的存储路径
remote:"/sst20240308"
# HDFS 的 NameNode 地址
hdfs.namenode: "hdfs://xxxx:8020"
}
# 客户端连接参数
connection: {
# socket 连接、执行的超时时间,单位:毫秒。
timeout: 30000
}
error: {
# 最大失败数,超过后会退出应用程序。
max: 32
# 失败的导入作业将记录在输出路径中。
output: /tmp/errors
}
# 使用Google Guava RateLimiter 来限制发送到 NebulaGraph 的请求。
rate: {
# RateLimiter 的稳定吞吐量。
limit: 1024
# 从 RateLimiter 获取允许的超时时间,单位:毫秒
timeout: 1000
}
}
# 处理点
tags: [
# 设置 Tag player 相关信息。
{
# 指定 NebulaGraph 中定义的 Tag 名称。
name: player
type: {
source: maxcompute
sink: sst
}
table:xxx
project:xxx
odpsUrl:"xxxxx/api"
tunnelUrl:"xxxx.com"
accessKeyId:xxxx
accessKeySecret:xxxx
partitionSpec:"pt='20240219'"
numPartitions:100
sentence:"select vid, name, age from test_nebula_import"
fields:[name, age]
nebula.fields:[name, age]
vertex:{
field: vid
}
batch: 256
# Spark 分区数量
partition: 32
# 生成 SST 文件时是否要基于 NebulaGraph 中图空间的 partition 进行数据重分区。
repartitionWithNebula: false
}
]
}
我粘贴了我生成sst的conf文件 应该没问题吧
不知道下一步怎么排查了
我不是通过csv生成sst的,而是通过maxcomputer生成sst,然后复制到了download文件夹内。

你瞅瞅这个帖子,看有用没。
感觉不太像这个问题,我们的进程没有挂掉,但是不知道为什么没有日志
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。