nebula 版本:1.0.1
-
部署方式(分布式 / 单机 / Docker / DBaaS):分布式
-
出问题的 Space 的创建方式: CREATE SPACE nba (partition_num = 10, replica_factor = 1, charset = , collate = )
-
问题的具体描述
按照spark-connector文档,编译nebula-spark之后,将得到的jar包上传服务器,之后用spark-shell执行ConnectReaderExample,但是提示Method not found
代码如下:
spark-shell --jars "/xxx/nebula-spark-1.0.1.jar"
import com.facebook.thrift.protocol.TCompactProtocol
import com.vesoft.nebula.tools.connector.NebulaDataFrameReader
import org.apache.spark.SparkConf
import org.apache.spark.graphx.Graph
import org.apache.spark.sql.{Dataset, Row, SparkSession}
import org.slf4j.LoggerFactory
def readNebulaVertex(spark: SparkSession): Unit = {
//LOG.info("start loading nebula vertex to DataFrame ========")
val vertexDataset: Dataset[Row] =
spark.read
.nebula("xxx.xxx.xxx", "nba", "10")
.loadVerticesToDF("player", "*")
val count = vertexDataset.count()
vertexDataset.printSchema()
vertexDataset.show()
//LOG.error("**********vertex count:"+count, null);
}
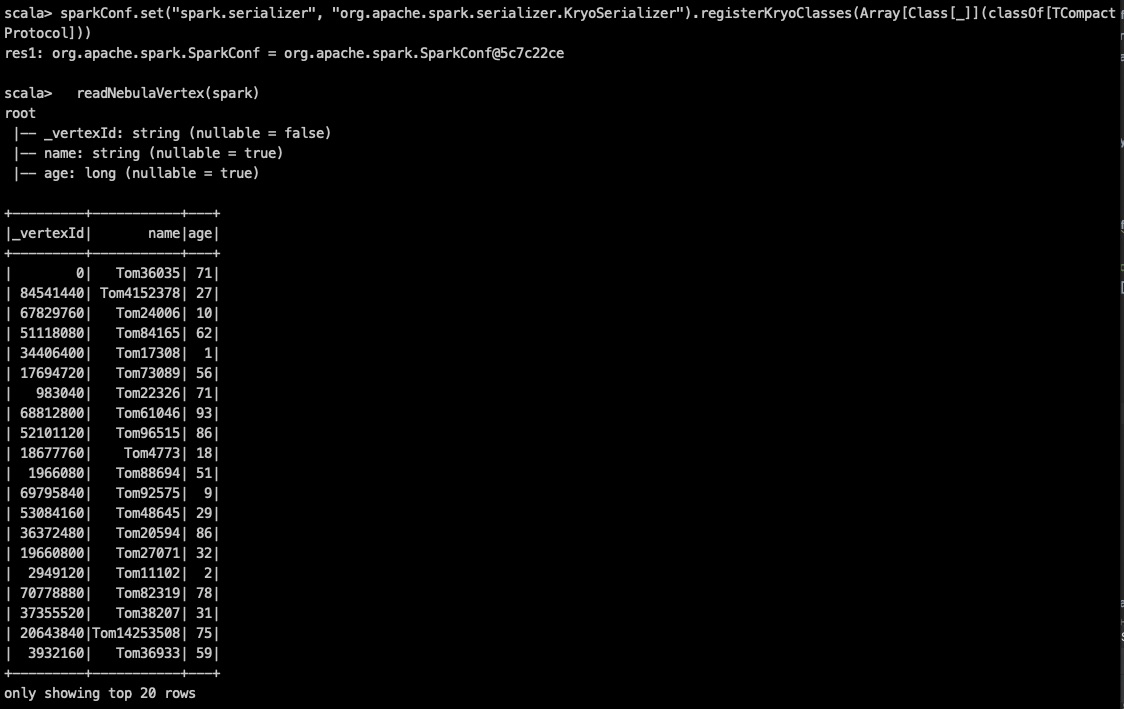
val sparkConf = new SparkConf
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").registerKryoClasses(Array[Class[_]](classOf[TCompactProtocol]))
val spark = SparkSession.builder().master("local").config(sparkConf).getOrCreate()
readNebulaVertex(spark)
nicole
2
看日志是metaClient的listSpaces打印的日志,nebula服务端没有找到对应的接口。
我通过spark-submit 执行ConnectReaderExample, 在1.0服务上是可以读出来,稍等我试下通过spark-shell读。
通过spark-submit读取的数据示例:
schema:()
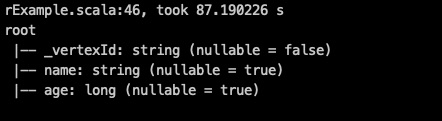
dataFrame:
1 个赞
nicole
3
我按照你的步骤在spark-shell中操作了一遍,是可以读出来的。
你在nebula console中show spaces 看下meta服务是否正常。
1.show spaces是正常的,不知道是不是我编译的时候出了问题?但是好像编译时也没有报错呀
2. 有个问题一直想问:就是用这种方法扫图数据库的时候,好像是没有填写密码的步骤,只需要指定地址和图空间,tag信息?那鉴权这块怎么过的?
nicole
6
你好,我用1.0.1的环境按照你的流程操作了一遍,没有复现出这个问题。
你重新启动下服务,再走一遍流程看下吧。
但是遇到了一个新问题:就是我读取指定图空间时,有时候读不出来;
- 某图空间partition num =10,我设置spark.read
.nebula(“xxx.xx.xx.xxx:xxx”, “xx”, “10”),可以读出来
- 某图空间partition num=3,我设置spark.read
.nebula(“xxx.xx.xx.xxx:xxx”, “xx”, “10”)可以读出来,但是
spark.read
.nebula(“xxx.xx.xx.xxx:xxx”, “xx”, “3”)读不出来
- 某图空间partition num =1000,设置1000读不出来
nicole
10
读不出来是报错还是只读出来部分数据还是一条数据都没有啊
都有 ,partitionNum=1000的是一条数据都读不出来,3的是读不全
nicole
14
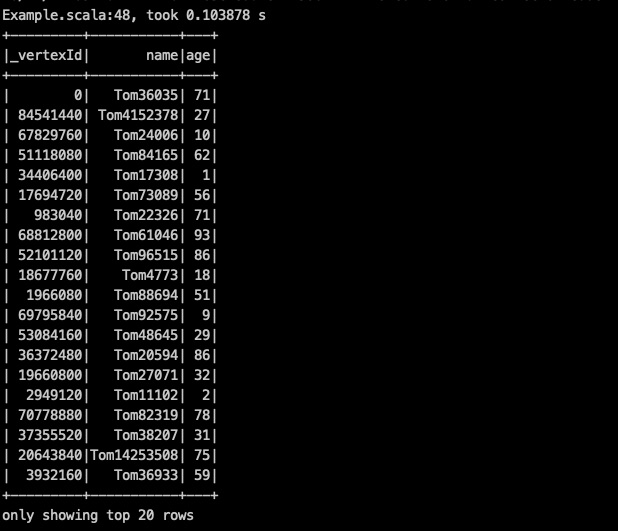
你的数据量多大,日志有没有错误信息,可以把结果展示贴一下么。 spark sql show的默认条数为20条。
我试过 图空间设置partition为3,代码中设置3和10都能读出来,1000的设置也可读出来,我的测试数据比较小。
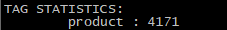

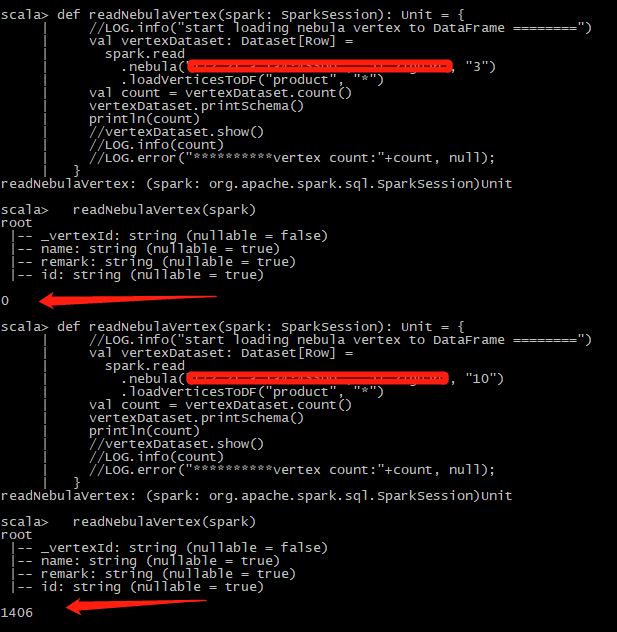
图一就是partitionNum=3的空间的结果,我把返回条数打印了一下,1000num的就和图一的上面那种类似,返回条数为0
图二是dump tool的结果
图三是space描述
nicole
17
我读取 一个partition_num为100的图,代码设置partition为1000和1,读出的数据量是对的。
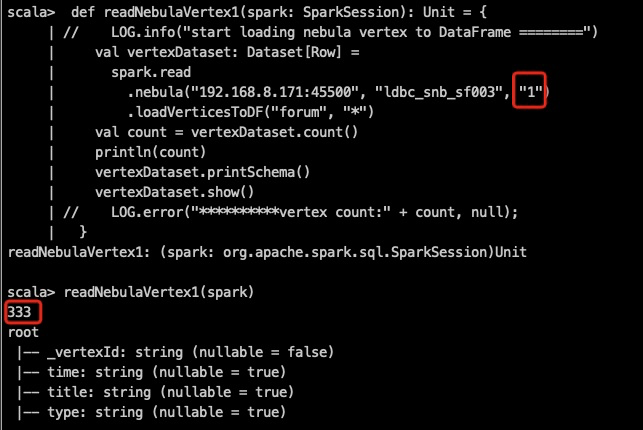
db_dump结果:
节点1
节点2
节点3
我的测试环境和你不同的是,图的副本数为1.
你在nebula console中执行下 show configs 看下enable_multi_versions 这个配置吧,是否支持多版本。多版本的话,db_dump是会统计多条的,spark 读取数据的是不同统计多条的。
我查看了enable_multi_versions,是设置为False,不是多版本的
我用spark扫描的问题主要在于每次扫描的数据都是不准的,有时候是0,有时候是14xx,有时候是正确结果。。
用的还是之前那个图空间如图,每次查都会不一样
nicole
20
你的创建schema的ddl可以发一下么,还有分布式部署中有几个 meta服务、几个graph服务、几个storage,是多节点分布式还是单节点多个端口的分布式,我尽量保持和你的环境一致。

 ,谢谢
,谢谢