- nebula 版本:V1.1.0 版本
- 部署方式:分布式 graphd,metad,storaged都是3台,配置文件官方生产环境配置文件
- 硬件信息: 256G内存
- 出问题的 Space 的创建方式:CREATE SPACE xx(partition_num=90, replica_factor=3)
- 问题的具体描述
执行 LOOKUP ON people WHERE people.age == "二十一"; 由于age是int类型,导致查询报错【Lookup vertices failed】,多执行几个类似这种报错sql,接下来正常的查询也会报相应的错误, 不知道是什么原因
再过一会时间又正常查询会出现warning提醒 如下
首先,第一个错误是不是在ERROR.log中包含错误信息 “Invalid leading character: “二十一”” ?
第二种warning是因为个别的part查询出错,只返回了正确查询的part,贴一下log
我知道第一个会报错,会报这种错误
但接下来正常查询 也会报【Lookup vertices failed】 这个是重点,你那可以试试类似的操作
根据你的描述,我理解复现流程为:
1,当lookup类型错误时,查询报错 “Lookup vertices failed”
2,重试n次上边的错误语句
3,将lookup修改为正确类型时,查询报warning。
是这样吗?还是 多执行几次错误类型的语句,然后再执行正确的语句,报错信息都是 “Lookup vertices failed” ?
查询正常语句开始也是报“Lookup vertices failed” ,再等会就会报warn了
参考一下 @min.wu 提到的问题?或是balance一下试试?
你好,好像不是HDD的原因,我在window系统,硬盘都是固态硬盘, 用docker 起了一个集群,测试仍然有这个问题,但是改成单例就没问题了,是不是集群模式下有这个问题呢,你那有测试集群吗?可以测试一下这个问题可以吗? 谢谢
难道是超时时间设置的太短导致的,重启正常查询就没问题了
根据错误提示,是某些part状态不正常。这个part状态问题不光导致lookup查询失败,其它查询语句也会报错。
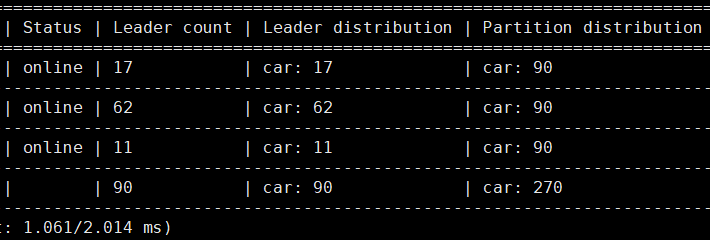
我看show hosts的截图,part分布也不抬均衡,尝试做一下balance
用错误的类型查询和用正确的类型查询没有直接关系,也就是说执行错误的类型查询后,理论上不是导致正常查询出错的原因。

 谢谢
谢谢
