要的,要跟下一个版本一起发。 你可以先把case TIMESTAMP加上,将本地的java-client打包,引入到spark-connector中。
对哦,可以贡献个pr哦,记得提到v1.0分支呀~
1 个赞
@nicole 大佬,我补全了代码后,nebula数据库中点的信息可以打印出来,打印边的信息时候会出现The value (50.0) of the type (java.lang.Double) cannot be converted to the string type ![]()
![]() 。我这边也debug了一下,发现在值为50.0这里报错了。
。我这边也debug了一下,发现在值为50.0这里报错了。

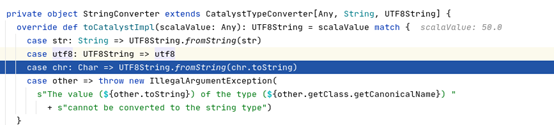

是不是边的schema设置的不对,有没有做dataframe.printSchema(),看下shema是不是把50.0这一列设置成了String类型。
加了dataframe.printSchema()呢,50.0这一列的类型没有进行类型设置,数值的类型还是double类型

你把nebula中这个space的edge的schema发一下吧,我看能否复现你这个情况。
应该还是timestamp的问题,我这边现在不取timestamp类型的列可以打印出数据,现在已经可以实现了 ![]()
![]()