mayer
2021 年1 月 15 日 08:53
1
取二度关注过滤掉一度关注以及重复的人:
(user@nebula) [friend]> (go 2 STEPS from 1001 OVER follow where follow._dst!=1001 YIELD distinct follow._dst MINUS go FROM 1001 OVER follow)
===============
| follow._dst |
===============
| 1009 |
---------------
| 1013 |
---------------
| 1006 |
---------------
Got 3 rows (Time spent: 4.455/5.961 ms)
查二度关注显示一度关注来源
(user@nebula) [friend]> (go 2 STEPS from 1001 OVER follow where follow._dst!=1001 YIELD follow._dst ,follow._src)
=============================
| follow._dst | follow._src |
=============================
| 1009 | 1003 |
-----------------------------
| 1013 | 1003 |
-----------------------------
| 1005 | 1004 |
-----------------------------
| 1006 | 1004 |
-----------------------------
| 1009 | 1004 |
-----------------------------
Got 5 rows (Time spent: 3.745/6.628 ms)
查二度关注显示一度关注来源 ,加上distinct follow._dst不起作用
(user@nebula) [friend]> (go 2 STEPS from 1001 OVER follow where follow._dst!=1001 YIELD distinct follow._dst ,follow._src)
=============================
| follow._dst | follow._src |
=============================
| 1005 | 1004 |
-----------------------------
| 1006 | 1004 |
-----------------------------
| 1009 | 1004 |
-----------------------------
| 1009 | 1003 |
-----------------------------
| 1013 | 1003 |
-----------------------------
Got 5 rows (Time spent: 2.564/4.665 ms)
另外能解释一下你的二度关注么?
这里的distinct不起作用是指报错,还是没有生效?distinct 属性1、属性2, 输出的结果是 属性1+属性2 满足distinct就行,和sql的distinct是一样的
mayer
2021 年1 月 17 日 04:58
4
请问下如果只distinct _dst ,能获取到这个_dst 的 _src么?
需求是找到我关注的关注的人,可能多个人关注了_dst,_dst要做下排重,但需要知道其中谁关注了_dst。
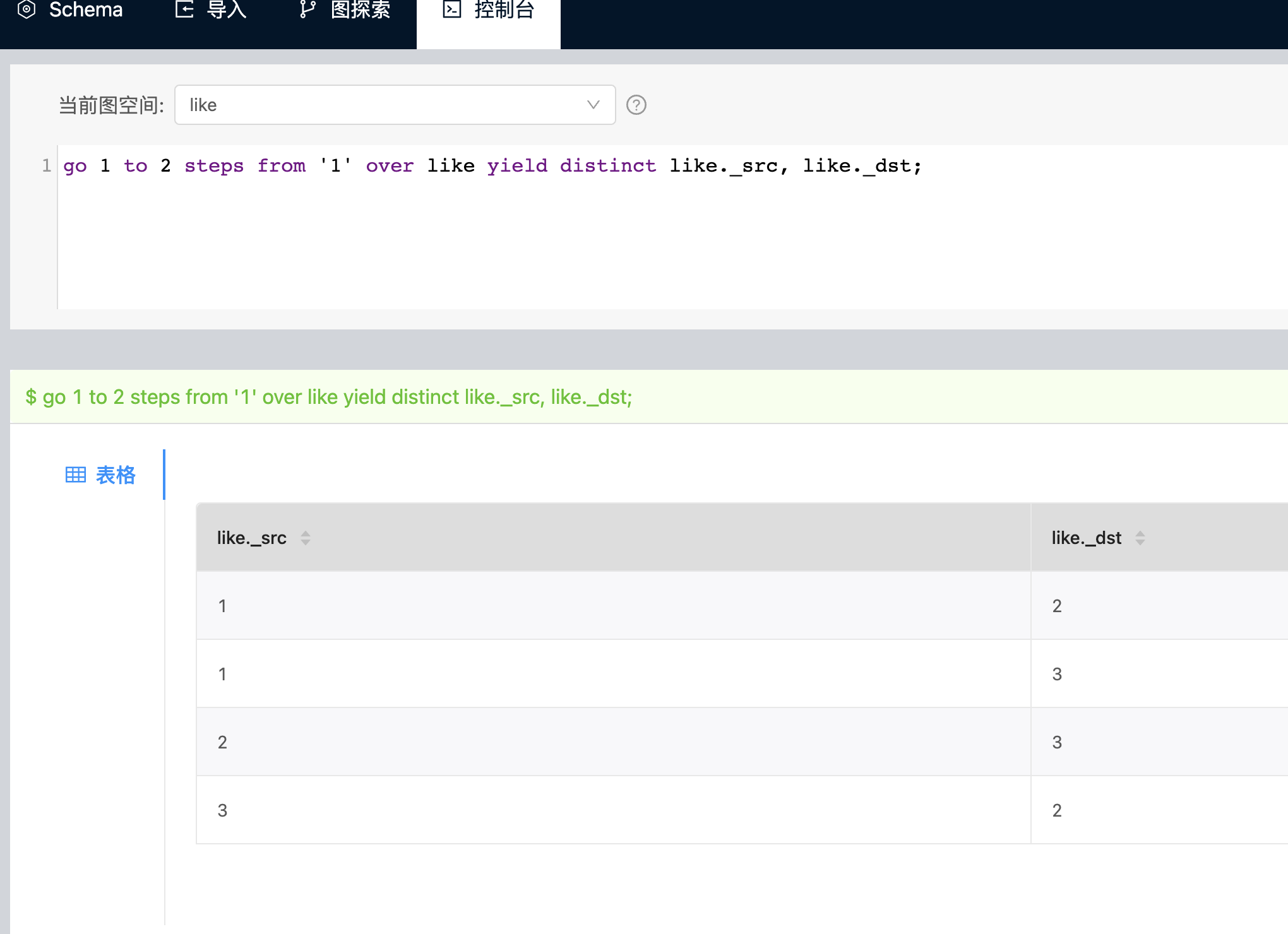
就像我上面列的一样,如果是想知道关注的人关注了哪些人,那么如我截图的例子(喜欢的人喜欢了哪些人),那么类似语句:go 2 to 2 steps from '我的id' over follow yield distinct follow._dst
当然你还想得出这些人究竟被谁关注的话,你还可以进行二次反查 go from '关注的人关注哪些人的ids(逗号分隔) over follow reversly yield follow._dstpipe 的支持,把上面两个nql结合在一起:
go 2 to 2 steps from '我的id’ from follow yield distinct follow._dst as dst | go from $-.dst over follow reversely yield follow.dst
mayer
2021 年1 月 18 日 01:04
6
试过了,不行呢反查之后 $-.dst 就重复了
看看下面执行的结果
(user@nebula) [friend]> go 2 to 2 steps from 33630944 OVER follow yield distinct follow._dst as dst| go from $-.dst over follow reversely yield $-.dst,follow._dst as src | limit 10
=====================================
| $-.dst | src |
=====================================
| 30762852 | 66431755 |
-------------------------------------
| 75466252 | 62100520 |
-------------------------------------
| 122207269885952 | 122208572217344 |
-------------------------------------
| 122207269885952 | 152170237869056 |
-------------------------------------
| 122207269885952 | 135716991492096 |
-------------------------------------
| 122207269885952 | 137339504517120 |
-------------------------------------
| 122207269885952 | 79578297182208 |
-------------------------------------
| 122207269885952 | 141040357270528 |
-------------------------------------
| 122207269885952 | 33630944 |
-------------------------------------
| 214491224701952 | 219768348087296 |
-------------------------------------
Got 10 rows (Time spent: 495.434/642.251 ms)
kyle
2021 年1 月 18 日 03:06
7
元组级去重用 distinct
1 个赞
那你两个查询结合在一起看,第一个查询获取我关注的人关注了谁,第二个获取这些人是被哪些人关注了。
因为就像上面同事说的,distinct是基于元组的去重,你的(dst和src)构成了一个元组,其中一个重复并不能表明整个元组重复。
而group by聚合某个字段去重后,必须进行相应聚合操作
所以我理解,要实现你的需求,如果你还要返回的我关注的人关注了谁,以及这些谁都被谁关注了(要去重),你通过两次查询自己整合一下?
mayer
2021 年1 月 18 日 04:07
9
用 group by 试了下也不行, 用group by $-.uid 会丢掉 follow_uid 的信息,如果用group by $-.uid,$-.follow_uid,又是把 uid + follow_uid 两个作为唯一来计算了,$-,uid 有重复
下面是执行的结果
(user@nebula) [friend]> go 2 STEPS from 33630944 OVER follow YIELD follow._dst as uid, follow._src as follow_uid | group by $-.uid,$-.follow_uid YIELD $-.uid as uid,$-.follow_uid as follow_uid | order by $-.uid | limit 5
=========================
| uid | follow_uid |
=========================
| 10000001 | 76764760 |
-------------------------
| 10000001 | 47633975 |
-------------------------
| 10000001 | 62100520 |
-------------------------
| 10000005 | 47633975 |
-------------------------
| 10011385 | 76764760 |
-------------------------
Got 5 rows (Time spent: 47.921/92.822 ms)
mayer
2021 年1 月 18 日 04:09
10
group by 只能一个字段,才有效,但这样,后面你说的那个聚合操作怎么进行呢?
嗯,我这里指的聚合只是在解释group by操作。我后面说的意思是,你自己通过两次查询来实现自己的需求。
mayer
2021 年1 月 18 日 05:25
12
这个通过管道再查询是不行的对吧?可能是只能以另外方式再查询一次了
这种需求挺常见的,特别是社交类应用中,做关系推荐时,所有的推荐规则都是要排重、过滤掉不需要的并且要知道得到的dst是基于哪个src做的推荐的,不知道新的2.0版本的查询语法能否支持呢?
yee
2021 年1 月 18 日 05:36
13
想了解一下如果有多个不同的 src 共同关注了 dst,这时你期望的结果是随便找出一对 (dst, src),还是把所有的 dst 对应的 src 都找出来,类似 (dst, [src1, src2, src3])
你能再列一下你的需求和预期返回格式么?我把你的建议记录下进行内部反馈
mayer
2021 年1 月 18 日 06:26
15
现在期望的结果是随便的出一对 (dst, src)
可能会有列出几个src的需求,不过不会有取全部src的需求,因为可能src有几十w条。
yee
2021 年1 月 18 日 06:50
17
如果是随便找出一条记录那可以用 group by 就能解决:
go 2 STEPS from 1001 OVER follow where follow._dst!=1001 YIELD follow._dst AS dst, follow._src AS src \
| GROUP BY $-.dst YIELD $-.dst AS dst, MAX($-.src) AS src
1 个赞
mayer
2021 年1 月 18 日 07:54
18
这个可以,group by 后原来YIELD加上max方法就可以选其它元素了,测试过了可以
现在还有个 MINUS过滤的问题,因为除了取二度关注要排重之外,还要过滤我一度关注的人,使用MINUS过滤之后怎么取 src 呢 (本来准备不用minus,先在外面把一度取出来后,改用条件!udf_is_in()来过滤,发现性能会差10倍,所以还是想看下minus )
下面是使用 minus过滤掉一度关注的dst结果,如何获取这些dst的 src呢?
(user@nebula) [friend]> (go 2 STEPS from 33630944 OVER follow where follow._dst!=33630944 yield follow._dst as dst minus go from 33630944 OVER follow ) | limit 5
==============
| dst |
==============
| 85526278 |
--------------
| 23098204 |
--------------
| 1839767264 |
--------------
| 60309343 |
--------------
| 15851767 |
--------------
Got 5 rows (Time spent: 80.447/127.197 ms)
yee
2021 年1 月 19 日 02:25
19
你好,你的问题可以简单的描述为,“我朋友的朋友不是我朋友” 的查询,如果是带有其他属性的话在 nebula 1.0 里不是很好描述,需要像你说的用到 in 或者 client 端做下处理。
后面类似查询,我们考虑在 nebula 2.0 实现对应的 MATCH 支持:
MATCH (a)--(b)--(c)
WHERE NOT (a)--(c)
RETURN a, b, c
3 个赞
mayer
2021 年1 月 19 日 02:34
20
对的,一个是:“我朋友的朋友不是我朋友” ,还有一种需求是"我朋友的朋友不是我关注的人",过滤掉另外一种关系的人。 最后还能获得dst的src。
希望新的2.0版本能支持一下 ,谢谢!