- nebula 版本:2.0
- 部署方式(分布式 / 单机 / Docker / DBaaS):Docker
- 硬件信息
- 磁盘( 推荐使用 SSD): scsi
- CPU、内存信息:8核16G
- 问题的具体描述
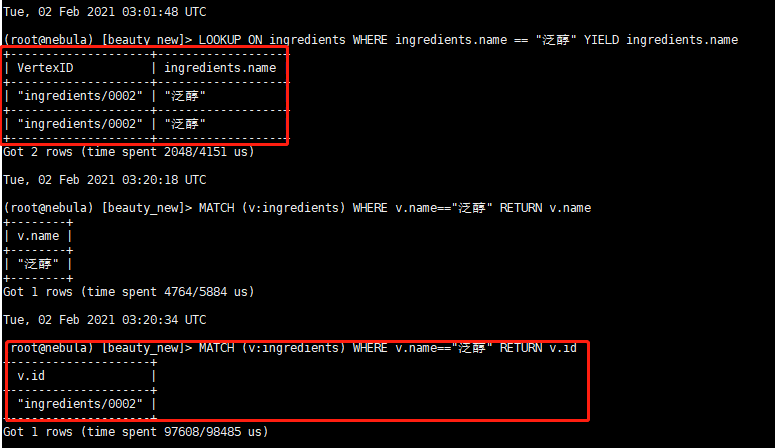
LOOKUP匹配的时候貌似会出现重复值,而且有时候会出现莫名其妙的值,但是MATCH不会有重复值,是否在查询的时候尽量减少LOOKUP的使用,而用MATCH去替代?


你用的是2.0什么版本?
explain 一下呢?
不太懂你指的版本是什么意思,是指哪个分支吗?分支是master分支。我是docker-compose按照https://github.com/vesoft-inc/nebula-docker-compose里面的说明部署的
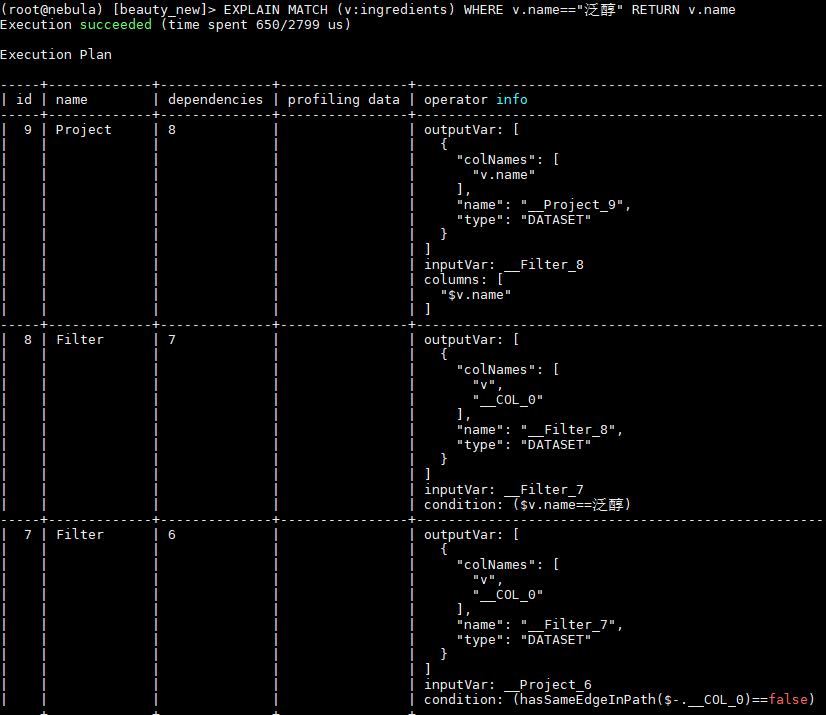

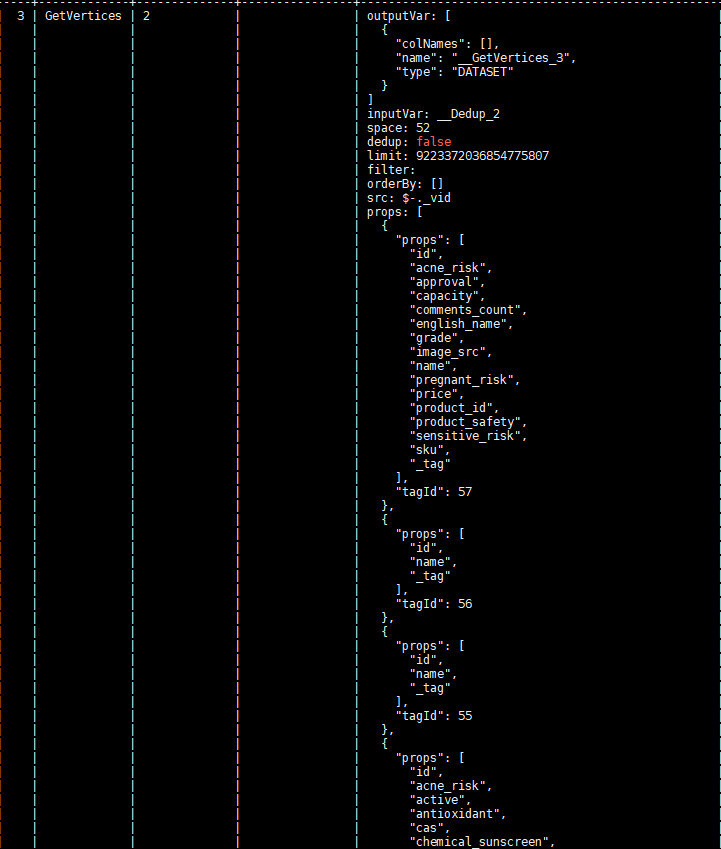
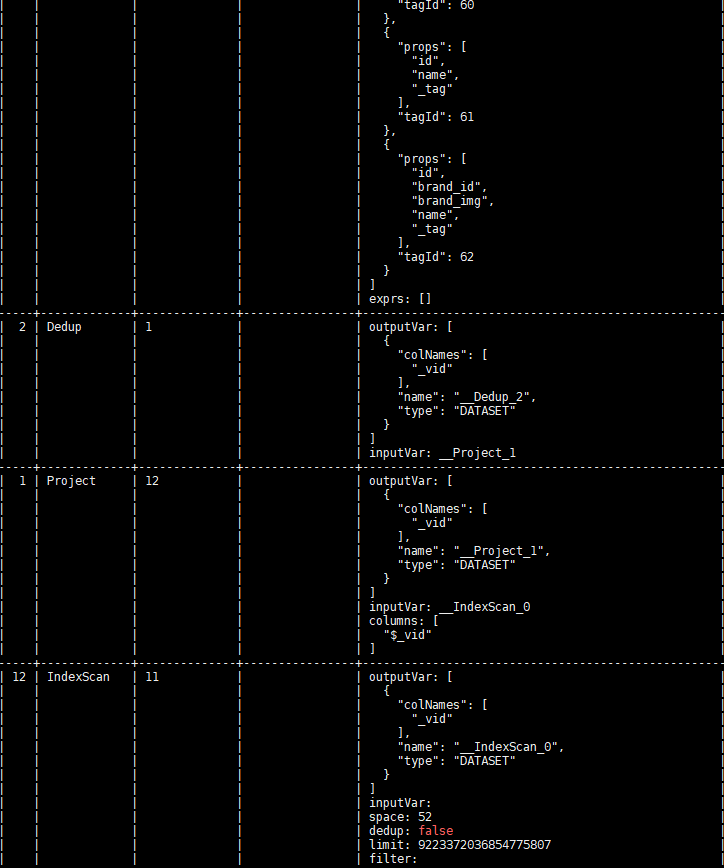
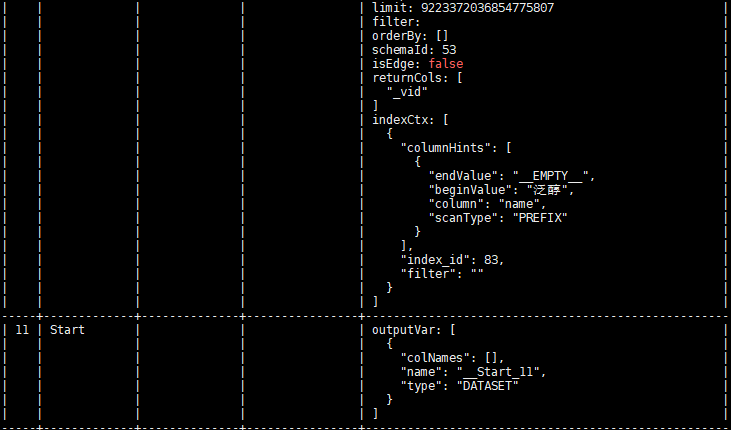
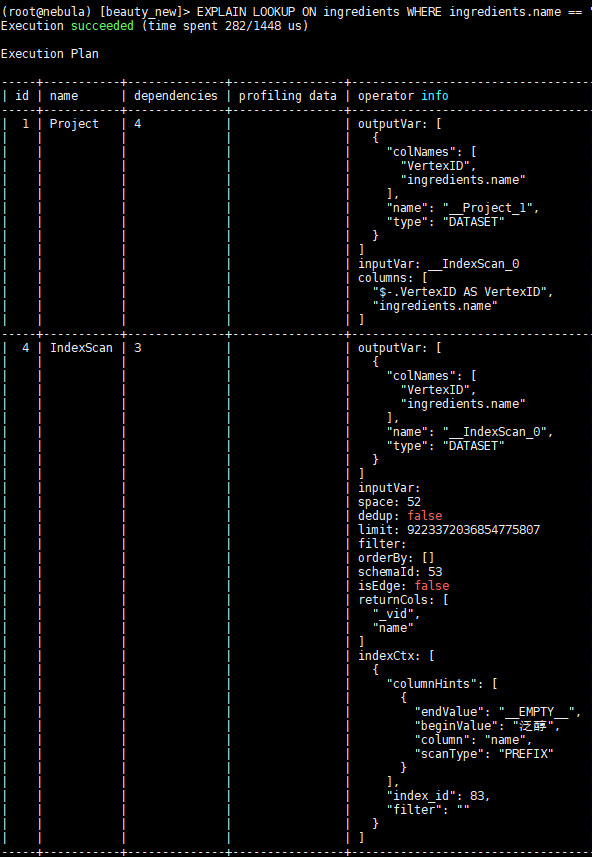
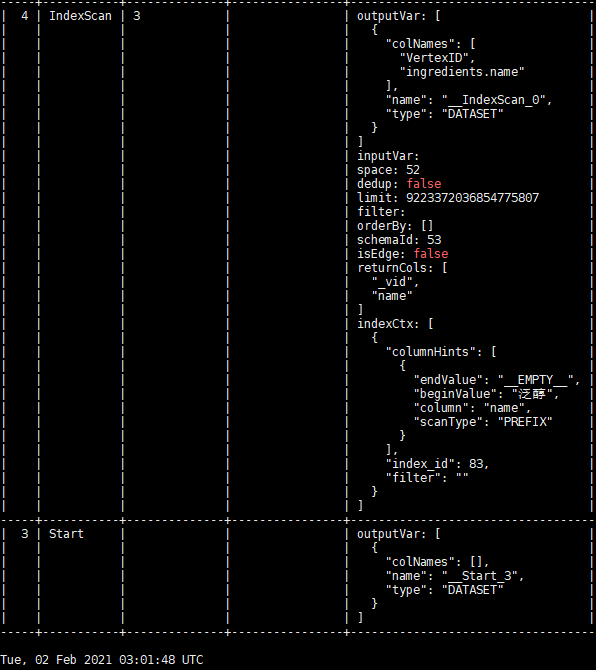
按道理讲是不应该出现这种情况,因为 LOOKUP 和 MATCH 底层都是使用的相同的接口去查询的索引。看执行计划,IndexScan 的查找索引的方式也是一样。
你能否用 nebula-console 再验证一下呢?如果真的还是这种情况,就需要 @bright-starry-sky 帮忙再仔细分析一下了。
你可以用如下两句看看 indexscan 上来的数据是否一致:
> PROFILE LOOKUP ingredients WHERE ingredients.name == "xxx" YIELD ingredients.name
> PROFILE MATCH (v:ingredients) WHERE v.name=="xxx" RETURN v.name


看样子 IndexScan 返回的结果是重复的,这个还需要 @bright-starry-sky 帮忙分析一下为啥同一份数据有两份索引记录?
MATCH 不重复的一个原因是对相同的 Vertex ID 有去重的操作(Dedup 算子), LOOKUP 是不去重的。
LOOKUP 也有dedup 去重的算子,这是什么时候的nightly-build?
这个环境部署的是几个storaged?
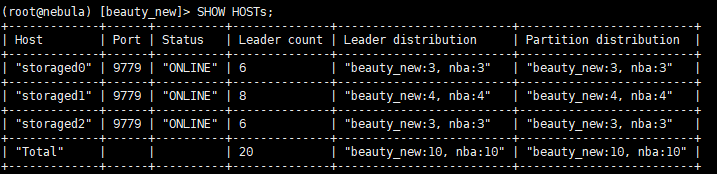
猜测是这个vertex同时存在于两个storaged的leader part中,但不知道是什么原因导致了这个问题。先尝试验证一下吧,先删除这个vertex,然后重新insert一下,再查询试试看。
1, delete vertex
2, lookup —> 期待没有结果
3,insert vertex
4, lookup —> 期待一条结果


这样的话,之前的判断是正确的,这个vertex被写到了不应该的storaged part中,另一个正确的part可以正常删除vertex,但这个错误的无法删除,导致查询出了冗余数据。
但是为什么图查询的时候查不到对应part的id呢? nebula没有一套机制是会在不同的storaged part中检查冲突的吗? 而且也看不到导入的数据,数据出没出问题我们都没法核对。。
而且如果出现了这样的问题,为什么MATCH和LOOKUP 的结果不一样。照上面所说,LOOKUP和MATCH应该是类似的一套检索机制才对,但是出来的结果不一样。如果有了MATCH,为什么要有LOOKUP这个功能,不是有些重复了吗?