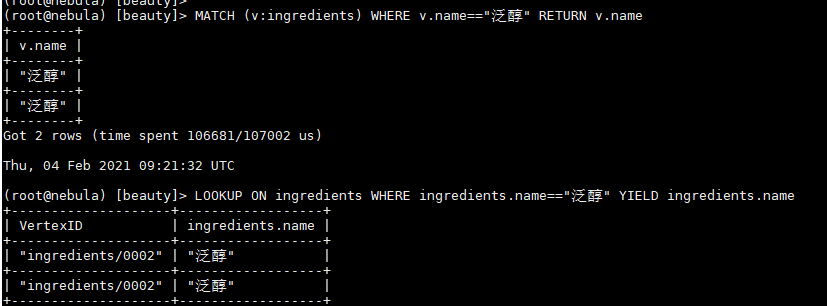
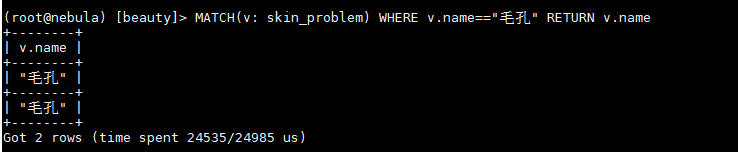
match的Dedup机制在graph层,LOOKUP的dedup机制在storage层。
但为什么图查询的时候又查不到这个id呢? 在MATCH 或者LOOKUP的时候可以查到对应的id
index是rebuild的吗?如果方便最好把storage的数据发给我们分析下,现在不好判断
是rebuild的,导入数据的时候没有创建index,是后面查询的时候单独设置的index;数据的话,很抱歉,这是内部的数据, 我发不了。我们没法看到导入之后的数据,所以数据导入正确或错误都没法得知。我个人觉得应该要有一套机制去处理不同storaged或者不同graph中的重复值以及其他的一些通用的冲突去兜底。 对于我遇到的这个问题,现有方案只能是重新导入数据重新构建索引是吗?
rebuild的过程中 还有写数据吗?
rebuild都是在数据导入之后再进行的,没有写入过数据。
好的。另外一个问题,导入的数据vid可能出现有若干不可见字符吗,比如“abc”和“abc ”,看起来都是abc,但不是同一个id。
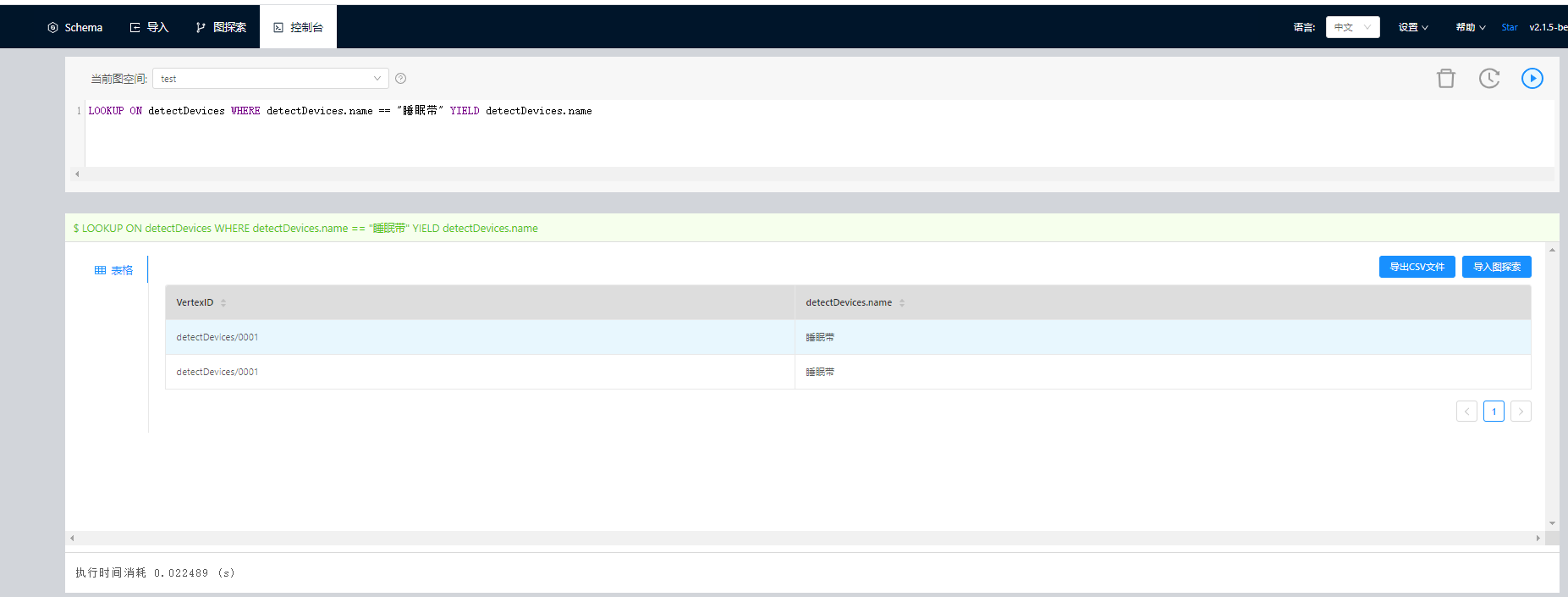
不存在这个问题,id都是以英文+“/“+数字的形式构成的,没有不可见的字符存在。 看上面贴出的图里也可以看到id是没有空格的,但是也还是会有重复。我不太清楚图探索的时候用的数据源是graph层的还是storaged层的,然而不管是哪一层,既然查询能查到对应的id,但是图查询的时候却查不到对应的节点,有点奇怪。
这个问题还得再定位下,目前说不好。几种可能:
- 同一个vid对应了多条index
- 同一个vid插入到了多个part(不大可能)
目前两种情况都没遇到过,待查。
好的,那我再重新导入数据一次,再重新构建一次索引看看能不能复现这个问题吧。到时候我会把结果更新在这个里面。
2 个赞
确认下 2.0 使用的commitid
确认 commit id 的方式,在安装的 nebula-graphd 等 binary 上执行如下的语句就可以:
$ ./bin/nebula-graphd --version
nebula-graphd version Git: 088a48d, Build Time: Jan 27 2021 15:18:43
This source code is licensed under Apache 2.0 License, attached with Common Clause Condition 1.0.

好的 多谢
你好,可以提供一些假数据和操作步骤吗?按帖子中的步骤,用web界面导入csv数据并没有复现这个问题。
我没有上传csv文件的权限。就上传个图片吧。
步骤:
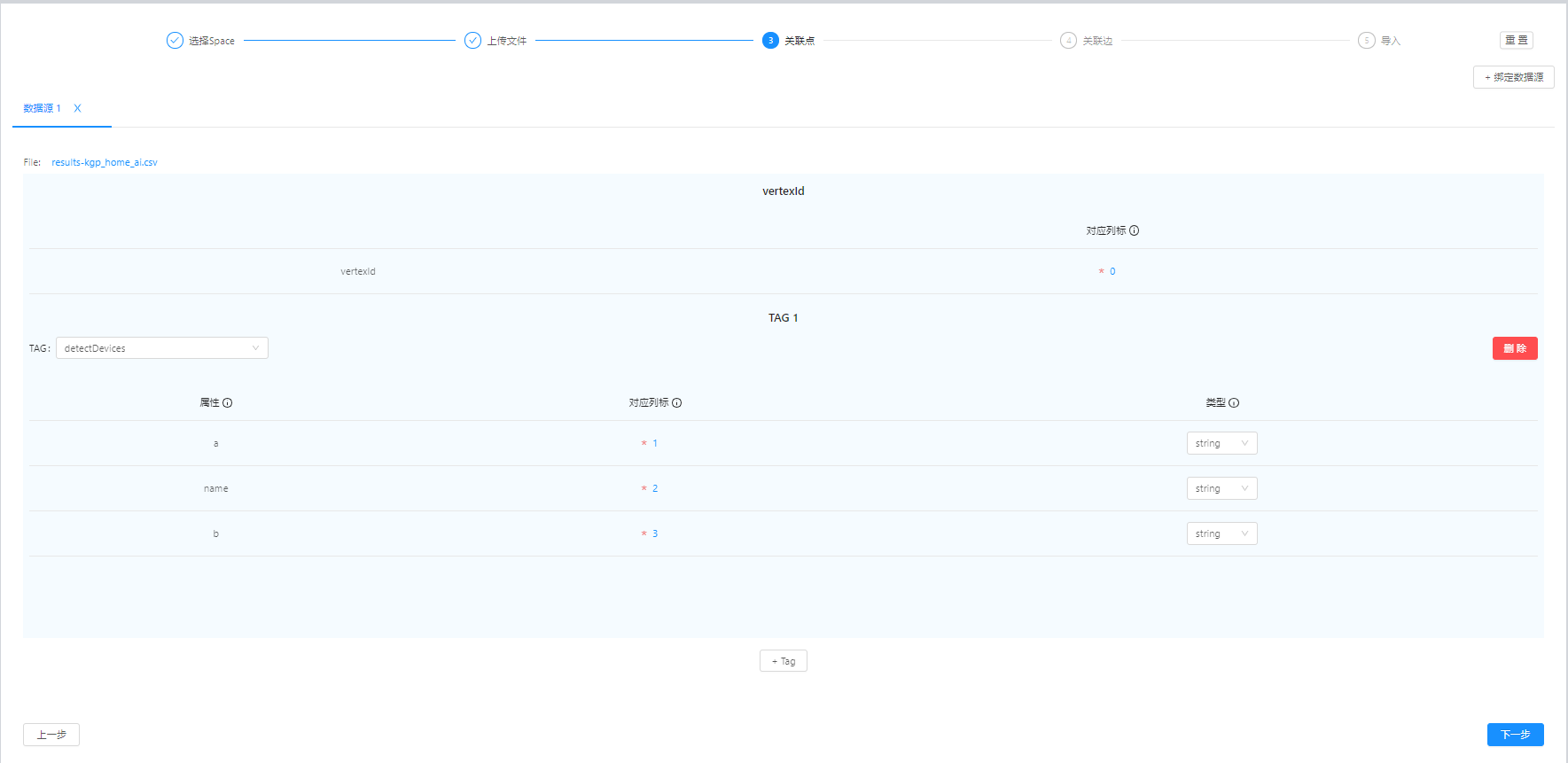
a.如第一个图所示,对应的列名分别为[“vid”, “a”, “name”, “b”](schema配置时,应该保持同样的名字)
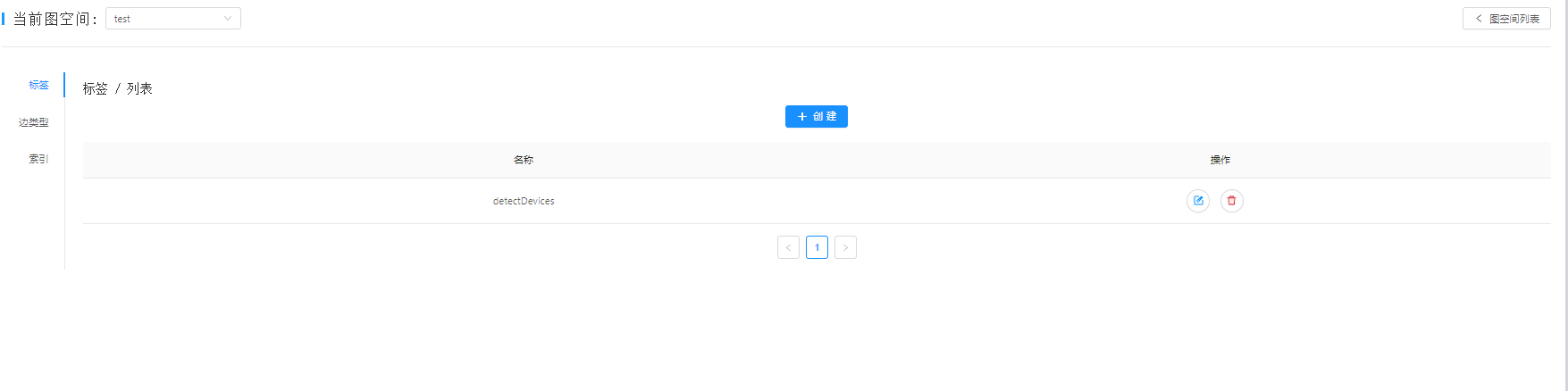
b.在web界面新建一个图空间为test,如图二
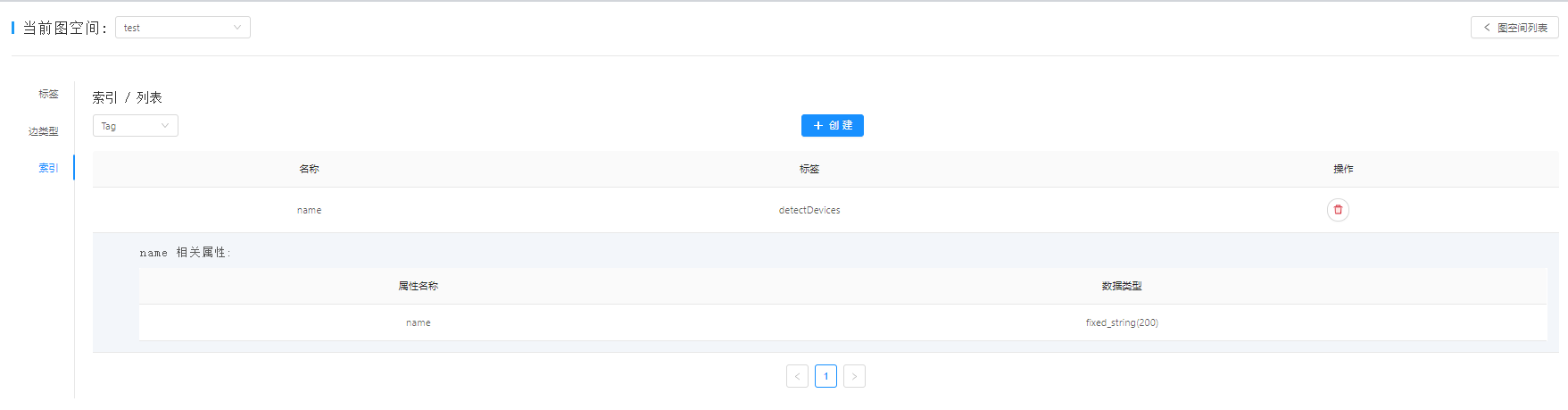
c.创建schema。只有一个TAG,没有边。如图三
d.导入数据。其中第0列是vid,如图四
e.数据导入成功后,创建索引,然后REBUILD索引。如图五
f.然后查询,如图六。

您好,不能上传csv可否 vim 打开数据文件,贴个2 3行的example呀?我们一直没有复现,