当前部署环境如下
- nebula 版本:v1
- 部署方式(分布式 / 单机 / Docker / DBaaS):3节点分布式 docker swarm
- 32 core, 64 g 内存,1t 硬盘空间(hdd)
- 问题的具体描述
我自己导入了一部分ldbc数据74G左右,Edge: 1101,535,334,Vertex: 282,612,309
100个partition,1副本,导入nebula后我查看了storage的大小是76g左右,减去wal文件2.2g左右,74g左右。
关于在测试中如何避免随机误差,我有以下几个问题:
-
在这个测试中,标中测的延时貌似是一次查询的延时。请问在实际测试中,是否应该随机抽样n个vertex统计查询延时的平均值(ave)和方差(std dev)。如果是这样,请问有没有推荐的n值。
-
在测试中,要如何避免查询结果被cache?同样在这篇report中,1 billion edges的时候2-hop和common friend的时间比1-hop快特别多。请问是否是因为1-hop和2-hop用的是同样的vertex,部分结果在cache中,所以2-hop反而比1-hop快。
-
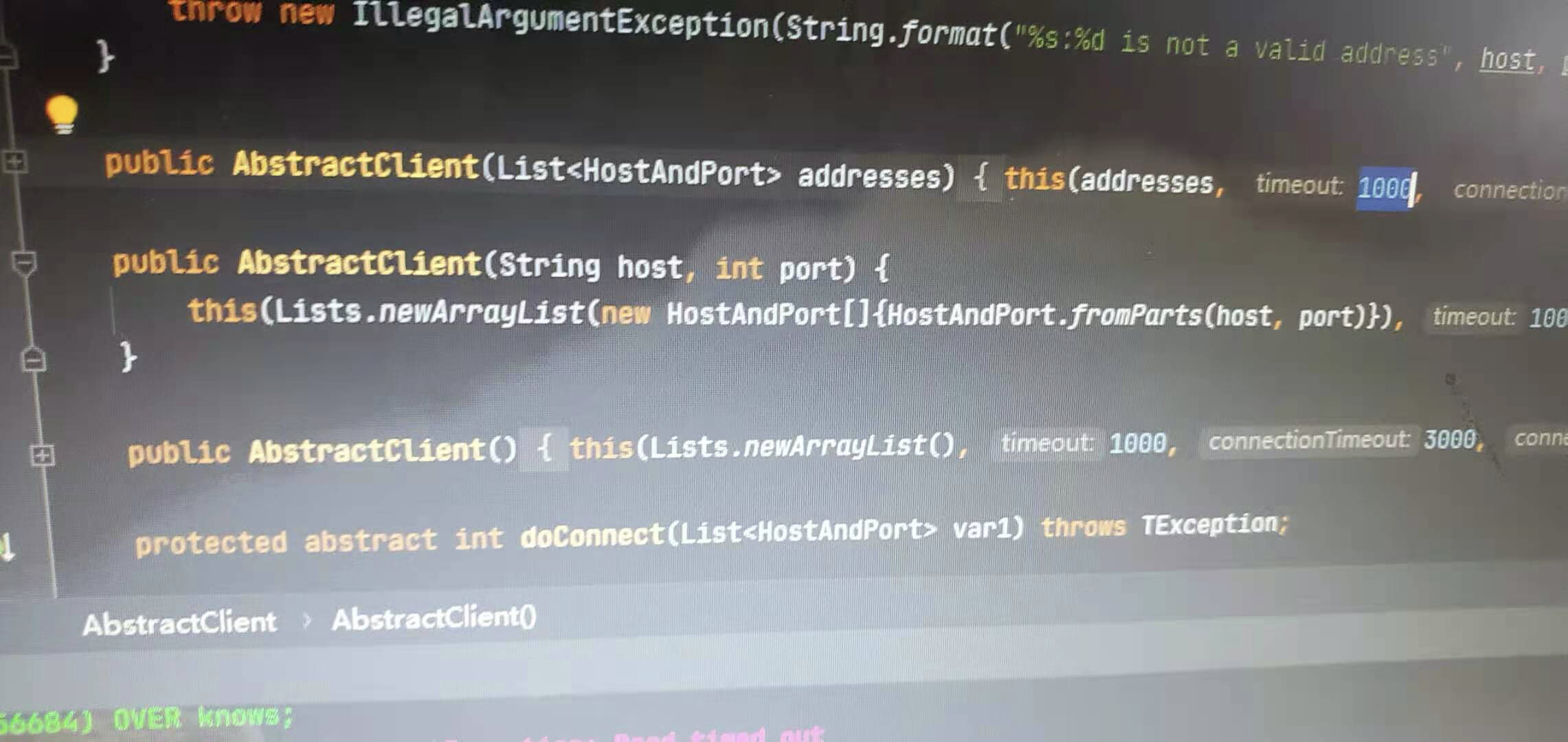
在测试3-hop时,会出现超时的问题。请问是否应该修改下图的timeout值,如果是的话,有没有推荐的值。
不会直接cache一个query的结果。但是访问到的kv会被存储层 cache。没有warmup的话,可能第一次各种加载就会特别慢吧。
你可以更改block cache大小。(通常lsm tree的index也会放在cache里面)。当然怎么用好cache本来就是存储系统很重要的一个功能。
另外,你现在的场景,数据量相比内存来说差不多,这样测试就变成了内存类的数据库会更有优势。