- nebula 版本:1.2
- 部署方式(分布式 / 单机 / Docker / DBaaS):分布式,docker swarm
- 硬件信息
- 磁盘( 推荐使用 SSD): SSD
- 问题的具体描述
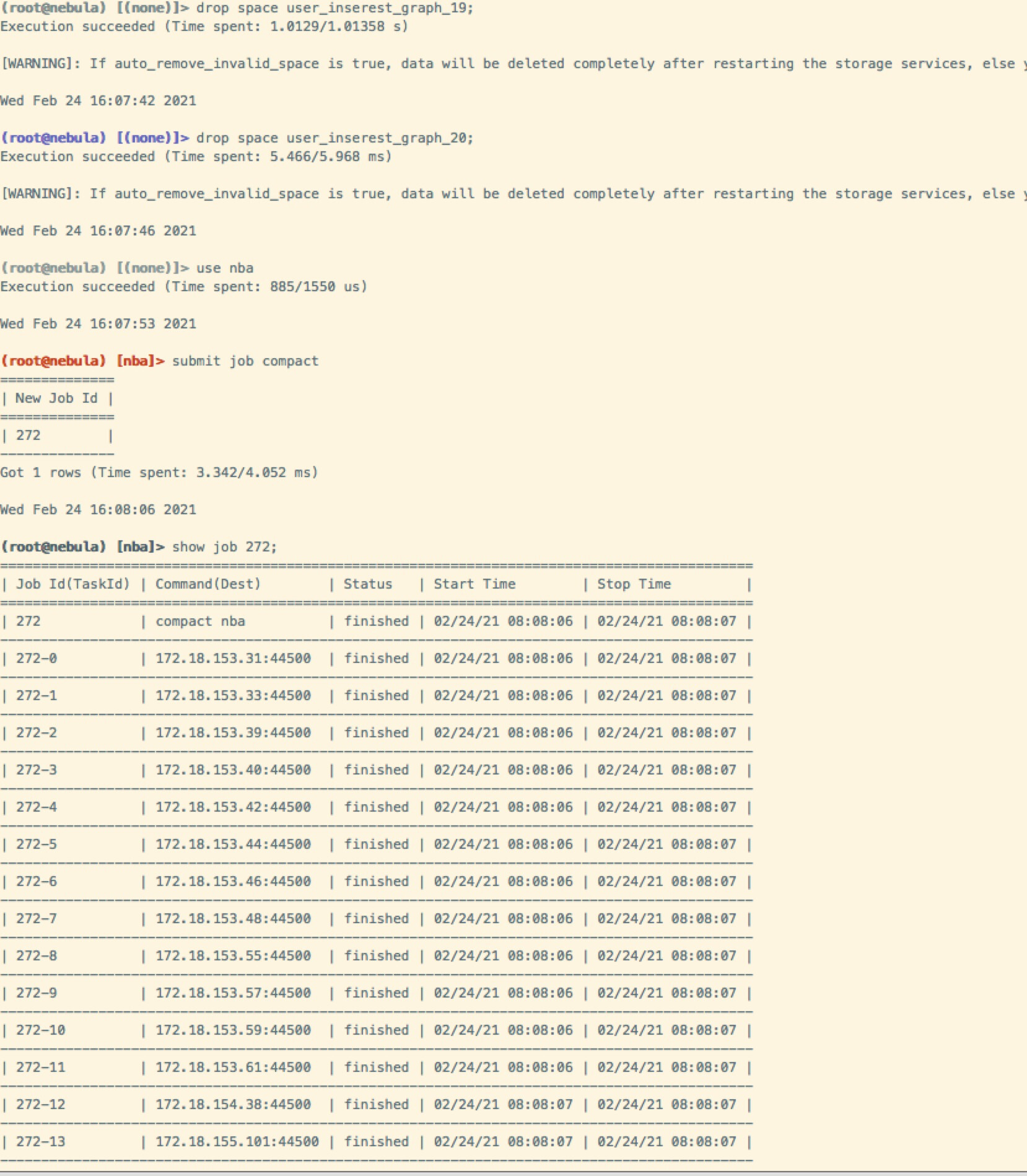
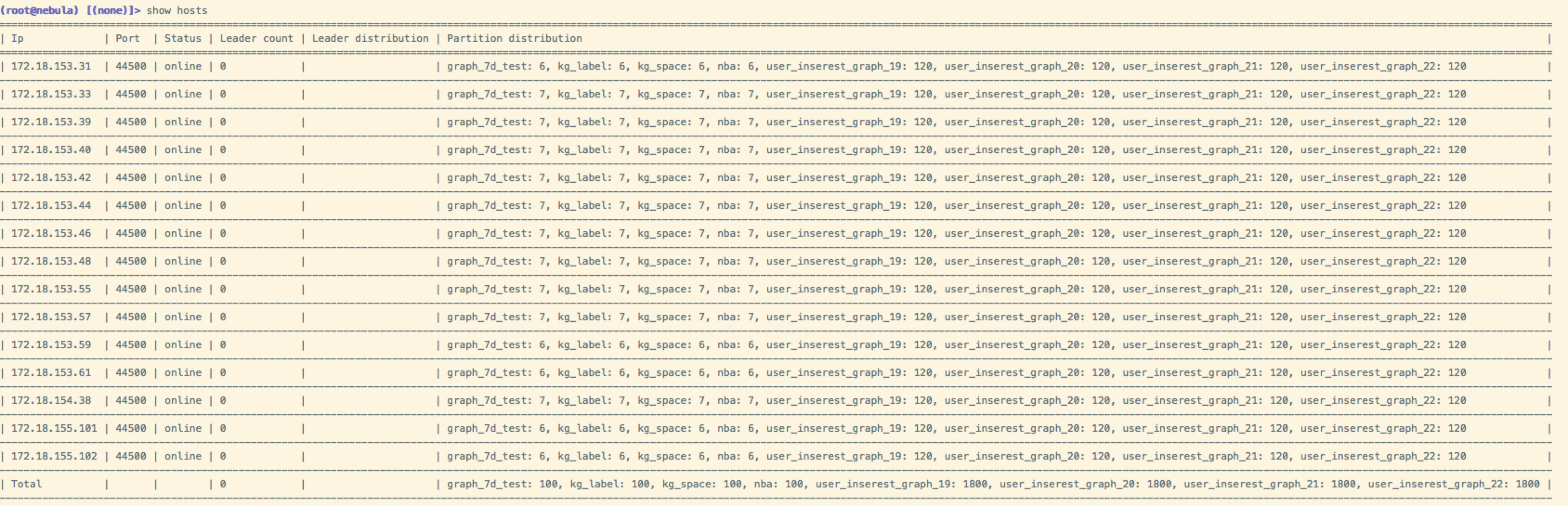
删除 space,然后compact,之后就出现了leader为0的情况:
storage日志
E0224 03:43:03.902843 72 RaftPart.cpp:1075] [Port: 44501, Space: 247, Part: 385] Receive response about askForVote from [172.18.153.57:44501], error code is -5
E0224 03:43:03.903028 72 RaftPart.cpp:1075] [Port: 44501, Space: 247, Part: 385] Receive response about askForVote from [172.18.153.59:44501], error code is -5
E0224 03:43:03.915774 74 RaftPart.cpp:1075] [Port: 44501, Space: 247, Part: 355] Receive response about askForVote from [172.18.153.57:44501], error code is -5
E0224 03:43:03.915894 74 RaftPart.cpp:1075] [Port: 44501, Space: 247, Part: 355] Receive response about askForVote from [172.18.153.59:44501], error code is -5
E0224 03:43:03.929023 72 RaftPart.cpp:1075] [Port: 44501, Space: 247, Part: 370] Receive response about askForVote from [172.18.153.57:44501], error code is -5
E0224 03:43:03.929147 72 RaftPart.cpp:1075] [Port: 44501, Space: 247, Part: 370] Receive response about askForVote from [172.18.153.59:44501], error code is -5
E0224 03:43:03.938876 71 RaftPart.cpp:1075] [Port: 44501, Space: 247, Part: 25] Receive response about askForVote from [172.18.153.57:44501], error code is -5
E0224 03:43:03.939165 71 RaftPart.cpp:1075] [Port: 44501, Space: 247, Part: 25] Receive response about askForVote from [172.18.153.59:44501], error code is -5
E0224 03:43:10.361182 28 RaftPart.cpp:909] [Port: 44501, Space: 247, Part: 40] processAppendLogResponses failed!
E0224 03:43:10.443105 36 RaftPart.cpp:909] [Port: 44501, Space: 247, Part: 115] processAppendLogResponses failed!
E0224 05:33:45.163125 23 RaftPart.cpp:365] [Port: 44501, Space: 247, Part: 387] The partition is not a leader
E0224 05:33:45.163419 23 RaftPart.cpp:635] [Port: 44501, Space: 247, Part: 387] Cannot append logs, clean the buffer
E0224 05:34:00.024829 17 RaftPart.cpp:365] [Port: 44501, Space: 247, Part: 370] The partition is not a leader
E0224 05:34:00.025069 17 RaftPart.cpp:635] [Port: 44501, Space: 247, Part: 370] Cannot append logs, clean the buffer
E0224 05:34:17.438490 33 RaftPart.cpp:365] [Port: 44501, Space: 247, Part: 402] The partition is not a leader
E0224 05:34:17.438741 33 RaftPart.cpp:635] [Port: 44501, Space: 247, Part: 402] Cannot append logs, clean the buffer
E0224 05:34:26.223234 20 RaftPart.cpp:365] [Port: 44501, Space: 247, Part: 251] The partition is not a leader
E0224 05:34:26.223489 20 RaftPart.cpp:635] [Port: 44501, Space: 247, Part: 251] Cannot append logs, clean the buffer