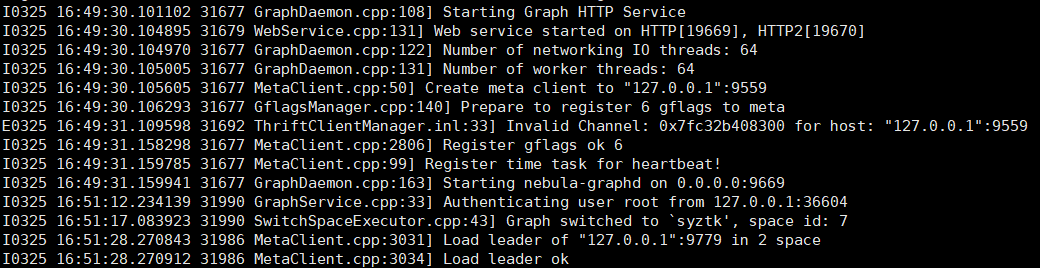
graphd 日志贴下。然后dmesg贴下,是不是内存不够。
进程应该没了
直接输入的命令dmesg吗?太多了都没展示完,RPM只修改过目录,没有修改过配置文件
dmesg |grep nebula 截图,或者看下安装目录下面有没有core 文件。
pandap
10
dmesg |grep nebula命令没有输出信息,
安装目录文件:
你可以执行下
UPDATE CONFIGS graph:v=1;
然后再执行删除,然后把nebula-graphd.INFO的日志贴出来吗?
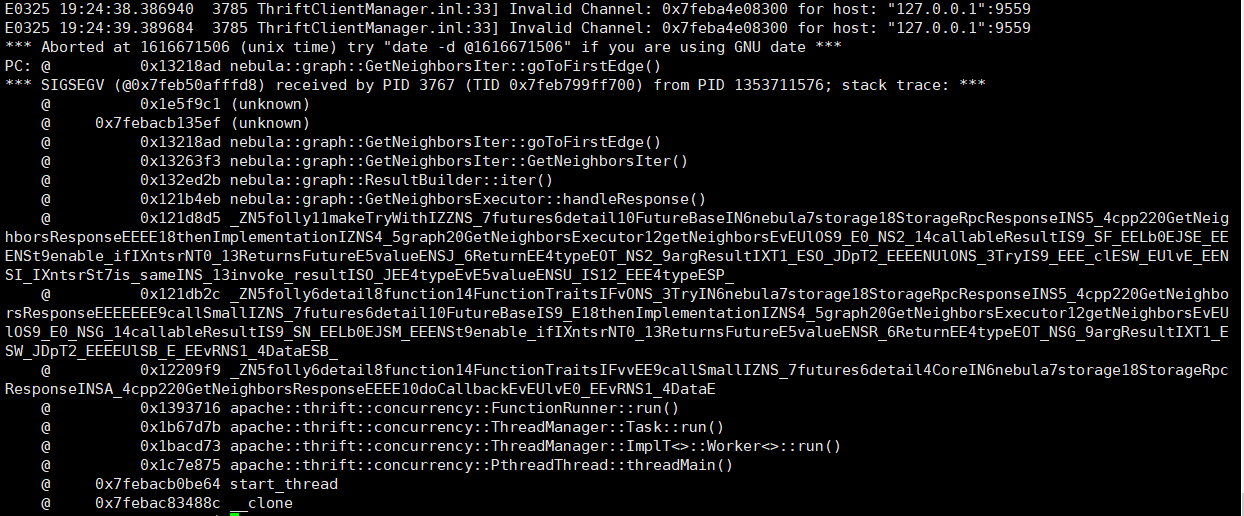
服务crash了,但是没有打印 Resp size:?
你不是有多个graphd吗?你要执行删除之后,服务crash了,才去看日志哦。
pandap
19
crash是重启nebula?我在虚拟机试了下,UPDATE CONFIGS graph:v=1;之后执行删除好像没问题,服务器上执行出错
crash就是产生core文件了,console 连接也会断开。
pandap
21
nebula-graphd.INFO日志:
重新安装了nebula删除成功了,
之前删除失败一次会产生一个core文件。
UPDATE CONFIGS graph:v=1;这句是每次删除都要先执行一次还是可以在哪里配置?
UPDATE CONFIGS graph:v=1;这句是每次删除都要先执行一次还是可以在哪里配置?
这个只是修改日志级别,把一些debug日志打出。
重新安装了nebula删除成功了
你重装之后就不出现了?
你可以看下这之间的区别吗,你之前的是不是直接用rc版本的数据升级到ga版本,做的删除操作,然后现在重装是,是把数据删除了重装?