(root@nebula) [nba]> explain match (v:player) return v
不会的
如果没有指定 tag 的属性或者顶点的 ID 且该 tag 上又创建了索引,在查找索引时是会退化成全 tag 扫描(一般不建议这么做,尤其数据量大的情况下)。
就你示例所示,如果 player 上有索引,是会返回该 tag 下所有顶点。
请问下这里的退化成全tag扫描,是player里扫描,还是space所有tag扫描呢?
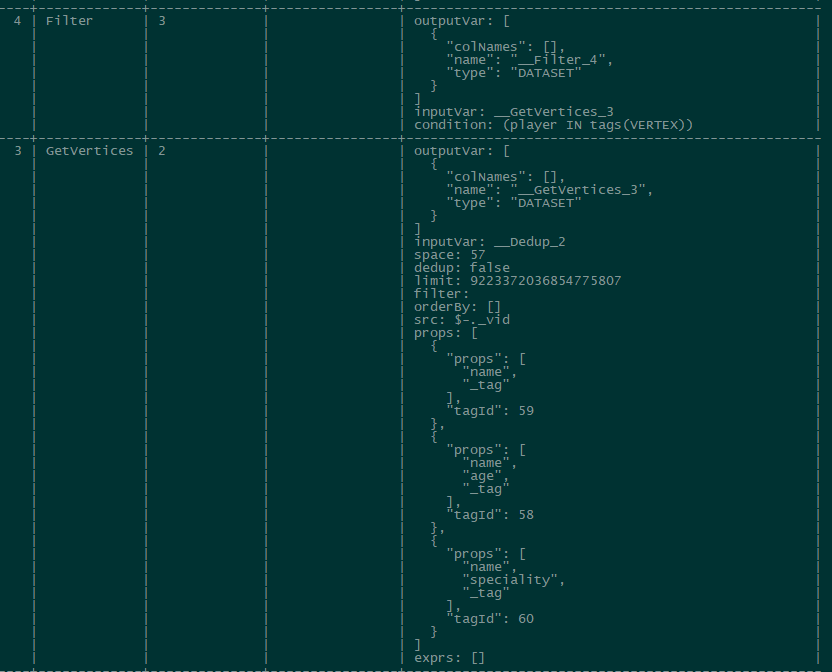
如果只是指定的tag扫描,比如这里的player,那如主贴截图所示,explain显示getVertices会把所有tag的props查出来放进props参数,然后下一步filter的condition是 player in tags。
有这个疑问是有一个测试tag,8k,使用match on tag执行要50s,但因为总的tag有180多个,profile显示耗时都在getVertices,也是显示所有tag的props都被查出来放到props
流程是这样的:开始的时候是会根据 tag 扫出来含有该 tag 的所有顶点,因为这些顶点可能不止含有一个 tag,所以还会去拿其他 tag 上的属性。举例来说就是比如 “Tim Duncan” 有两个 tag(player 和 bachelor)你查询的时候只根据 player 查,首先可以查到 “Tim Duncan” 然后再去找 “Tim Duncan” 的其他 tag 的属性 bachelor
1 个赞
谢谢,那其实 match (v:tag_name) return v最好是用lookup on tag_name代替吧?
另外当这种指定了tag_name的情况还是会去查的其它tag这样设计是为了要和没有指定的情况共用方法吗?
MATCH 在实现中是要去取顶点的所有属性的,可以用 lookup 代替性能应该好些,现在 match 的是实现还不完善,等以后优化做的好了,其实 match 也可以做到 lookup 一样的性能,现在还不行。
1 个赞
在执行match之前只对点的一个属性作了索引,然后 lookup on person | limit 2或者像楼主一样用match巨慢无比,没有耐心等下去。这是什么原因啊?按理说不是应该像neo4j一样随机取2条记录,瞬间就返回了吗?我数据库中只有一种点tag,6亿条。
这个场景的limit下推目前还没有做,正在排期中
1 个赞