单机部署环境,内存足够大250GB,查6亿条边的数据,某些查询语句很慢,创建了索引的,看explain应该是正常的。但是top看storaged只使用了20GB左右的内存,是不是因为数据没有载入内存啊。我想把内存利用起来,有具体设置推荐吗?
graphd不会预热的。storaged 预热了意义不大。
1 个赞
由于我这边背后只能使用cephfs作存储,目前看到data目录有400多GB的使用,里面有7000多个sst文件,每个文件66MB左右。然后我在这个目录执行命令ls -lh需要4秒。
1.是不是sst文件数过多影响性能呢?
2.有没有办法增大每个sst文件的大小?
3.对于使用cephfs作存储的场景(目前我这边预研只有公司的私有容器云环境,内存可以扩容到200GB以上,但是磁盘只有cephfs),nebula有没有配置参数可调?
谢谢。
- storaged设计时候,是面向SSD硬盘。不是面向内存,也不是面向分布式文件系统
- 改sst文件大小可以找找rocksdb的文档。
- 看你什么类型的查询。给几个例子。
lookup on trx where trx.a==‘x’ yield trx.b as in_edge_b, trx.c as in_edge_c | go from $-.DstVID over trx where trx.a==‘y’ and $-.in_edge_b<trx.b and abs($-.in_edge_c-trx.c)>50 yield $-.DstVID | yield count(*) as vertex_count;
这个执行3小时都超时了
其中a,b,c属性均作了索引
- count(*) 这个大概会有多少个点。
- 别用cephfs了,不支持。
- 就是不知道会有多少,没查出来。总图的边和点都是6亿,非常稀疏。
- 确实环境有限,所以在想怎么尽量减小磁盘性能的影响。
目前的想法就是只要能够在这种环境下跑出结果,几个小时之内能出结果都可以接受,下一步才好继续在公司推进。
另外查了一下rocksdb的配置,修改storage conf以后好像没有生效,而且进程也起不来了。
在rocksdb_db_options里加了个"target_file_size_base":1073741824
- 大概率拼写错误。看storaged日志,应该说有个rocksdb option错误。
- 几个小时级别的查询,放spark更快吧。
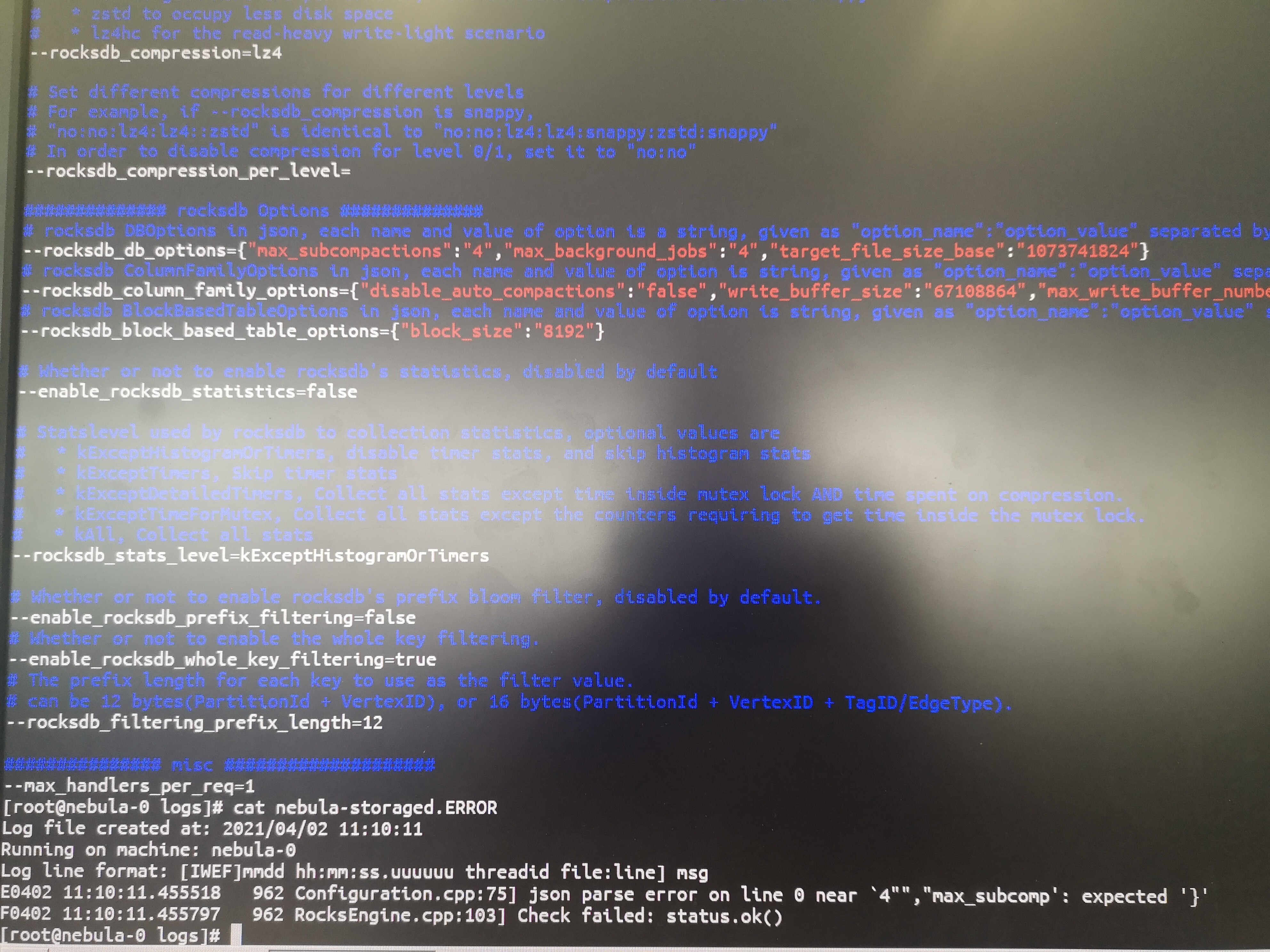
这个数据量其实并不大,建议别用cephfs了,这个文件系统是没有支持的,更没有经过测试,即使现在数据库能起来,后续肯定还会遇到很多问题。
1 个赞