$SPARK_HOME/bin/spark-submit --class com.vesoft.nebula.exchange.Exchange --master yarn nebula-exchange-2.0.0.jar -c ./application.conf

application.conf 配置如下 :

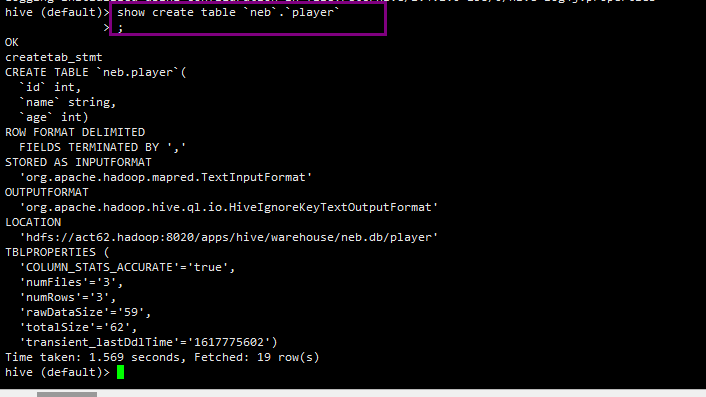
hive 中 player 表详情如下
$SPARK_HOME/bin/spark-submit --class com.vesoft.nebula.exchange.Exchange --master yarn nebula-exchange-2.0.0.jar -c ./application.conf
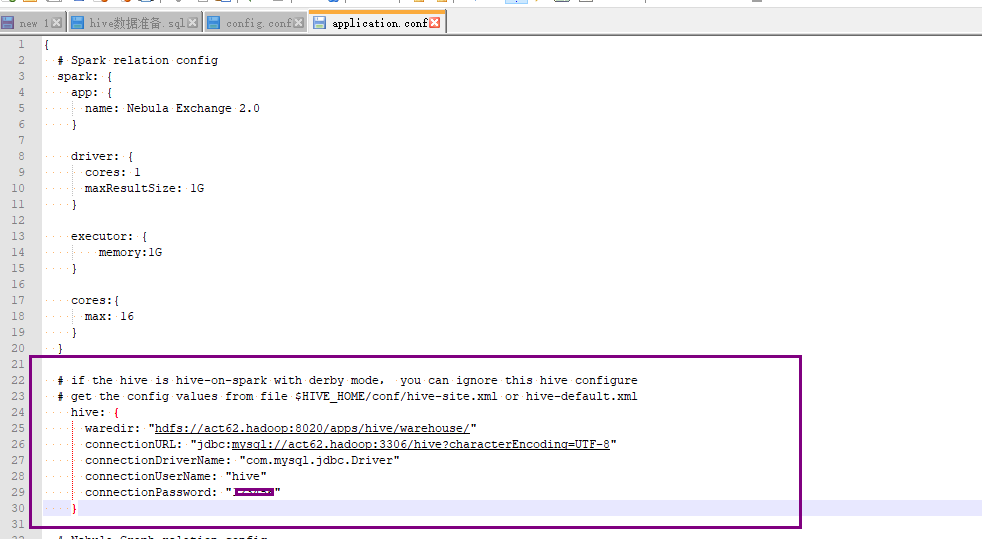
application.conf 配置如下 :
hive 中 player 表详情如下
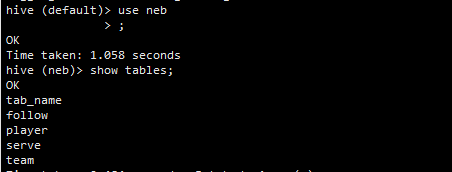
你现在hive中 show tables 看下创建的表所属的数据库吧。如果所属数据库是default,那这种表名形式SparkSQL是会把neb.player 中的neb作为database名的。
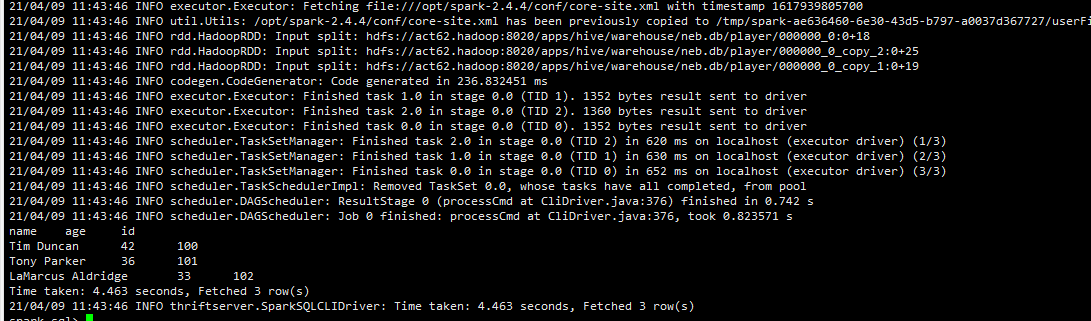
可以在提交任务的Spark环境中用SparkSQL执行下 select name,age,id from neb.player 看是否可以读到hive表。
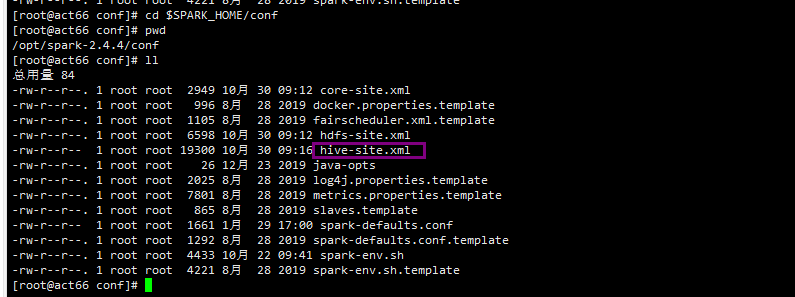
你的hive是配置在了提交任务的Spark集群中了么,如果已将hive-site.xml配置在spark的conf中,可以把exchange配置文件中 的hive连接信息去掉。
spark 中配置了 hive-site.xml
application.conf 中已经注释掉了hive相关的配置。
配置如下:
{
# Spark relation config
spark: {
app: {
name: Nebula Exchange 2.0
}
driver: {
cores: 1
maxResultSize: 1G
}
executor: {
memory:1G
}
cores:{
max: 16
}
}
# if the hive is hive-on-spark with derby mode, you can ignore this hive configure
# get the config values from file $HIVE_HOME/conf/hive-site.xml or hive-default.xml
#hive: {
# waredir: "hdfs://act62.hadoop:8020/apps/hive/warehouse/"
# connectionURL: "jdbc:mysql://act62.hadoop:3306/hive?characterEncoding=UTF-8"
# connectionDriverName: "com.mysql.jdbc.Driver"
# connectionUserName: "hive"
# connectionPassword: "123456"
#}
# Nebula Graph relation config
nebula: {
address:{
graph:["gb01:9669","gb02:9669","gb03:9669"]
meta:["gb01:9559","gb02:9559","gb03:9559"]
}
user: user
pswd: password
space: test1
# parameters for SST import, not required
path:{
local:"/tmp"
remote:"/sst"
hdfs.namenode: "hdfs://act62.hadoop:8020"
}
connection {
timeout: 3000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
# failed import job will be recorded in output path
output: /tmp/errors
}
rate: {
limit: 1024
timeout: 1000
}
}
# Processing tags
# There are tag config examples for different dataSources.
tags: [
# Hive
{
name: player
type: {
source: hive
sink: client
}
exec: "select name,age,id from neb.player"
fields: [name,age,id]
nebula.fields: [name,age,id]
vertex: {
field: id
# policy: "hash"
}
batch: 256
partition: 32
}
]
# Processing edges
# There are edge config examples for different dataSources.
edges: [
# Hive
{
name: follow
type: {
source: hive
sink: client
}
exec: "select degree,b_id,e_id from neb.follow"
fields: [ degree,b_id,e_id]
nebula.fields: [degree,b_id,e_id]
source: b_id
target: e_id
batch: 256
partition: 32
}
]
}
执行$SPARK_HOME/bin/spark-submit --class com.vesoft.nebula.exchange.Exchange --master yarn nebula-exchange-2.0.0.jar -c ./application.conf
报错如下:
21/04/09 14:20:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2c9cafa5{/static/sql,null,AVAILABLE,@Spark}
21/04/09 14:20:28 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.31.134.61:57602) with ID 1
21/04/09 14:20:28 INFO storage.BlockManagerMasterEndpoint: Registering block manager act61:41008 with 366.3 MB RAM, BlockManagerId(1, act61, 41008, None)
21/04/09 14:20:29 INFO state.StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
Exception in thread "main" org.apache.spark.sql.AnalysisException: Table or view not found: `neb`.`player`; line 1 pos 24;
'Project ['name, 'age, 'id]
+- 'UnresolvedRelation `neb`.`player`
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:42)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$checkAnalysis$1.apply(CheckAnalysis.scala:91)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$checkAnalysis$1.apply(CheckAnalysis.scala:86)
at org.apache.spark.sql.catalyst.trees.TreeNode.foreachUp(TreeNode.scala:127)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$foreachUp$1.apply(TreeNode.scala:126)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$foreachUp$1.apply(TreeNode.scala:126)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.catalyst.trees.TreeNode.foreachUp(TreeNode.scala:126)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$class.checkAnalysis(CheckAnalysis.scala:86)
at org.apache.spark.sql.catalyst.analysis.Analyzer.checkAnalysis(Analyzer.scala:95)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:108)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:105)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:201)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:105)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:78)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:642)
at com.vesoft.nebula.exchange.reader.HiveReader.read(ServerBaseReader.scala:68)
at com.vesoft.nebula.exchange.Exchange$.com$vesoft$nebula$exchange$Exchange$$createDataSource(Exchange.scala:240)
嗯是的,问题已经解决