图库搭建起来稳定后,即使没有任何操作它占用的内存却依然不停在上涨,请问是什么情况呢?总是内存爆炸重启可太麻烦了
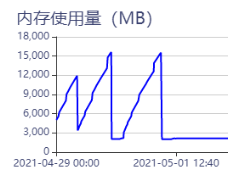
已经把enable_partitioned_index_filter设置为true了,但内存还是按照上图哪种方式在涨,我的nebula-graph版本是1.2.0的,内存信息:8C16G
图库搭建起来稳定后,即使没有任何操作它占用的内存却依然不停在上涨,请问是什么情况呢?总是内存爆炸重启可太麻烦了
已经把enable_partitioned_index_filter设置为true了,但内存还是按照上图哪种方式在涨,我的nebula-graph版本是1.2.0的,内存信息:8C16G
请问有数据吗?数据量是多大?在起库时,可能会有一些后台操作,比如compact、balance等,估计过一段时间后,后台操作完成后内存会趋于平稳。
有的有的,目前数据量不大,就十多万个节点,四十多万个边,起库了以后内存占用量就一直在涨,没停过欸
block_cache改成很小吧。。。。
配置文件local_conf=true别忘了。
嗯嗯,改成16了,local_config也设置了,再等一天看看啦
RocksDB实例数量 *
嗯嗯,对照着算了我预留内存应该是在3G左右,但是内存一直涨到15G就没停下来过:
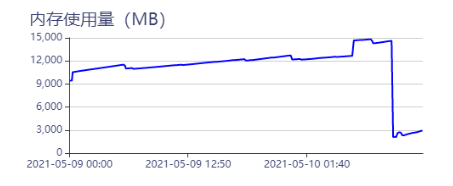
今早又挂了,我的计算方式如下,麻烦帮忙看看有什么问题吗?
点和边的总数<=400000
RocksDB实例数量=32
write_buffer_size=16M
max_write_buffer_number=4
块缓存大小=rocksdb_block_cache=16
(400000*15+32*(16*(1024^2)*4+16*1024^2))*1.2/(1024^3)=3.0067055225372314 GB
没看明白 400000*15 是算的什么意思?
公式里面的
点和边的总数*15
我的点和边的总数最多400000
1.现在还在预研阶段,就输入试试的,实例推荐多少个呢?
2.–local_config=true已经设置了,它内存增长斜率确实降低了
3.没有compact job
4.nebula-storaged进程在持续上涨
1.现在还在预研阶段,就输入试试的,实例推荐多少个呢? 1个数据盘1个
2.–local_config=true已经设置了,它内存增长斜率确实降低了
3.没有compact job 有没有query?
4.nebula-storaged进程在持续上涨 升级到1.2.1吧(但是1.2.0也没有内存泄漏啊)
5. --enable_partitioned_index_filter=true 这个参数是不是没有设置?
那我现在删除几个实例会不会对数据造成影响?
有过query
–enable_partitioned_index_filter=true已经设置了
会,数据当然会丢失
但是为什么我照着文档算的我的内存是够的它还是会继续增长呢?就是因为在不停地构建实例吗?
[quote=“Timaos123, post:22, topic:3832”]
但是为什么我照着文档算的我的内存是够的它还是会继续增长呢?就
但是。rocksdb自己会额外占用一些内存做启动时候的compact之类的,还有glog会额外占用日志,包括进程本身常驻的,这几个部分我在写这个公式的时候,算到了20%的buffer里面。你机器就没多少内存(公式是基于96GB生产配置写的),那额外这些常驻就会明显大于20%。
一个rocksdb大概需要占用多少内存呀?
