- nebula 版本:2.0.1
- 部署方式:K8S
- 是否为线上版本:Y
- 问题的具体描述
我部署了一个集群,在创建了快照文件,快照文件迁移,图空间创建,图空间删除,结点扩容,结点平衡等一系列操作后发现了一个问题,主要表现为:
当集群不断重启测试,leader metad实例被调度至不同的结点,此时leader metad调度至原结点和调度至扩容后的新结点会有不同的元数据信息,同时同一图空间id目录下./data/storaged/${space_id}存放着多个图空间信息,当leader metad调度至原结点时,通过show spaces查询出来的是space A,当leader metad调度至新结点时,查询出来的则是space B,两个图空间完全不一样,但共用了相同目录
您好,有几个问题,需要你描述清楚
1)在k8s上使用什么工具部署的nebula集群
2)集群重启测试是如何操作的
3)扩容是否只调整了storaged组件
1.k8s使用的是helm工具
2.集群重启是反复执行helm update --recreate-pods操作,然后通过创建SNAPSHOT定位到leader metad具体在哪个结点(因为好像没有提供查看leader metad实例所在结点的其他方法,如果有,求教)
3.扩容不只调整了storaged组件,还调整了metad组件和graphd组件,是否是因为这个原因导致的呢?
1.k8s使用的是helm工具
2.集群重启是反复执行helm update --recreate-pods操作,然后通过创建SNAPSHOT定位到leader metad具体在哪个结点(因为好像没有提供查看leader metad实例所在结点的其他方法,如果有,求教)
3.扩容不只调整了storaged组件,还调整了metad组件和graphd组件,是否是因为这个原因导致的呢
metad 没前没有对外部暴露 raft 详细信息,另外不建议调整metad的副本数,保持3副本的高可用部署即可。
每次重启集群前是否把绑定的pvc也删除了呢,看你操作描述没有pvc的解绑操作,那么上一个集群的图空间还遗留在挂载的存储盘上,下次启动的pod会继续挂载,metad读取到旧数据
2 个赞
1.我每次重启前的确没有把绑定的pvc删除,因为我用的是local-storage的pv,并且在集群的每个结点尚绑定了一个数据目录,这个数据目录是固定不变的,所以上一个集群的图空间遗留在挂载的存储盘上这一点我能够理解。
2.但是我最不能理解的是结点扩容后,为什么当leader metad调度到旧结点的时候读取到的是最新的元数据信息,而调度到新结点的时候读取到的则是旧的元数据信息,不同结点间的元数据信息不应该会自动完成同步嘛?
我这边整理了个可以导致我上述情形的测试流程,主要如下:
1.创建并查看old_space图空间,此时可以看到该图空间的id为1

2.修改结点副本数从5变为3,并清空nebula-metad-0, nebula-metad-1, nebula-metad-2的 data/meta目录,重启集群
helm upgrade -n nebula-dev nebula ./nebula --recreate-pods
3.调用show spaces查看当前图空间列表,可以看到图空间已被清空
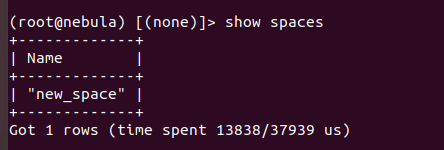
4.重新创建并查看new_space图空间,此时可以看到该图空间的id也为1

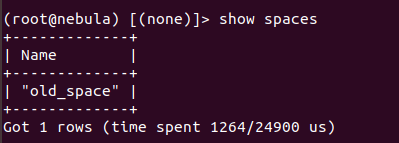
5.重新修改结点副本数从3为5,多次重启集群,通过create snapshot定位leader metad实例被调度至那个结点,此时可以发现,当leader metad实例被调度至nebula-metad-0, nebula-metad-1, nebula-metad-2结点(该3个结点经过元数据目录清理,并重新创建新的图空间)时,其图空间列表为:
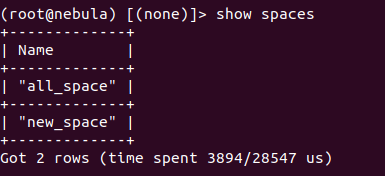
而当leader metad实例被调度至nebula-metad-3, nebula-metad-4(该2个结点没有经过元数据目录清理)时,其图空间列表为:
6.这说明当Nebula元数据底层文件经过手动操作后,不同结点间元数据可能会无法进行正常同步。
7.在上面的基础上,创建图空间all_space

8.并同样多次重启集群,通过create snapshot定位leader metad实例被调度至那个结点,此时可以发现,当leader metad实例被调度至nebula-metad-0, nebula-metad-1, nebula-metad-2结点(该3个结点经过元数据目录清理,并重新创建新的图空间)时,其图空间列表为:
而当leader metad实例被调度至metad-3, nebula-metad-4(该2个结点没有经过元数据目录清理)时,其图空间列表为:
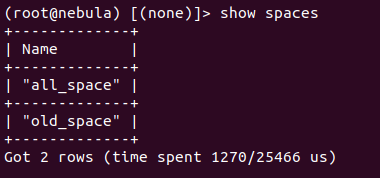
9.可以看到图空间元数据混乱只影响到id相同的图空间old_space和new_space,对于正常的其他图空间all_space,其元数据能够正常同步。
10.然后我们可以选择任意一个图空间,比如new_space,于其中创建一个tag test_tag,并插入一个结点,同时切换至all_space,于其中创建一个tag all,并插入一个结点
use new_space
create tag test_tag()
insert vertex test_tag() values "xhb":()
use all_space
create tag all()
insert vertex all() values "xhb2"()
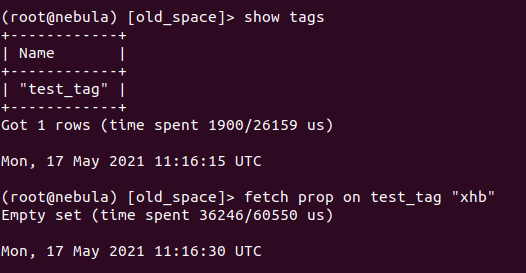
11.然后我们不断重启集群,直到leader metad实例被调度至nebula-metad-3, nebula-metad-4时,可以发现,对于old_space而言,其同样也创建了一个名为test_tag的tag,但却查询不到任何数据。
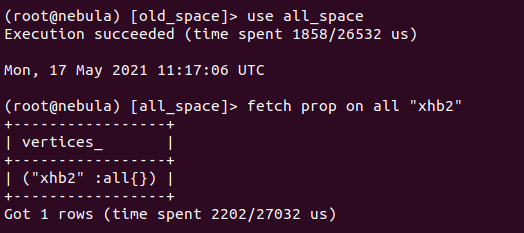
对于all_space而言,其同样也创建了一个名为all的tag,同时能查询到所有数据
12.对此,我提出一个猜测,就是nebula元数据在进行同步的时候以图空间目录为单位,但不会关注旧文件,即不会同步旧文件,只会对新文件进行同步,也正因此能在old_space中查看到在new_space创建的tag。
上面的流程只是我测试过可以再现我上述问题的测试流程,但不代表是唯一能造成类似情况的方法,所以我想知道的是为什么这些数据文件并不能自动完成同步,以及我该如何避免这类情况呢?
metad的leader会向follower同步数据,为了保证你测试的准确性,应该在每次重启集群重启时把上次挂载的pvc清理掉,另外metad目前不支持扩缩,保持3副本高可用部署就够了
你好,我这边更新了一下上面的测试步骤,针对此我提出了一个猜测,就是nebula元数据在进行同步的时候,是以图空间id为单位的,但不会对旧文件进行同步,只会对新文件进行同步。请问我这个猜测是否准确呢?
看了下操作步骤,meta从5副本变成3副本,然后删掉了3个结点数据,这一步之后就都错了。首先,删掉多数副本的数据之后,所有行为都是undefined behavior,所以才会出现后面的各种诡异现象。
1 个赞