大家好, 希望求助,
1 我先按照官网的指导,先执行这两步
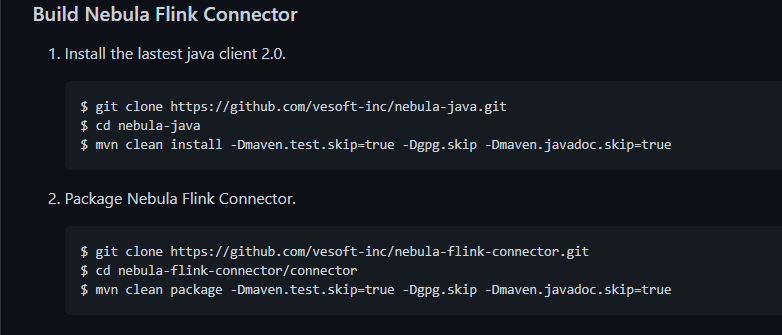
2. 然后我吧 nebula-flink-connector 的带依赖的jar包添加进工程
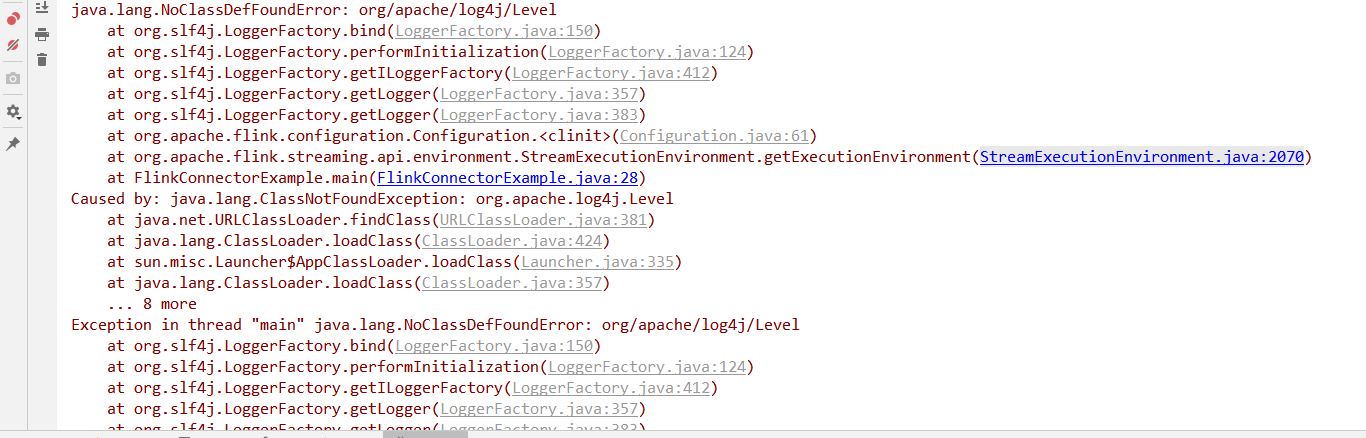
3. 执行FlinkConnectorExample.java例子, 报依赖找不到(这一步是在公司内网环境实施, 连不通外网)
大家好, 希望求助,
1 我先按照官网的指导,先执行这两步
你看下工程的pom中slf4j依赖版本,是不是和log4j的包存在冲突。
可以把slf4j-log4j12-xxx.jar包通过<exclude></exclude>排除掉
没有语言级别的支持,内部有一些事务的应用
那也就没有完整的会话, 回滚了?
是的,没有语言级别的回滚
哦哦, 好的, 了解, 请问下支持自定义函数吗?? 存储过程等等??? 我在官网上暂时没有找到
不支持
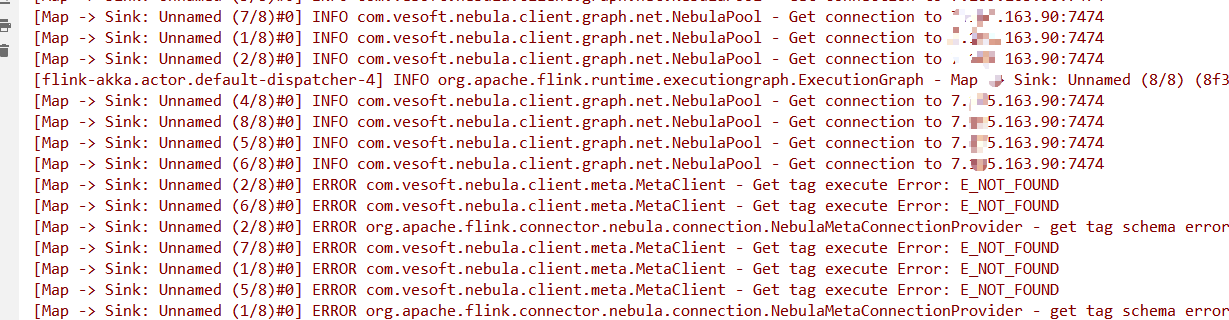
你看下连接的服务, 要读取的space/tag是否存在
这个已经解决, 谢谢哈, 请教你一下下面这个问题
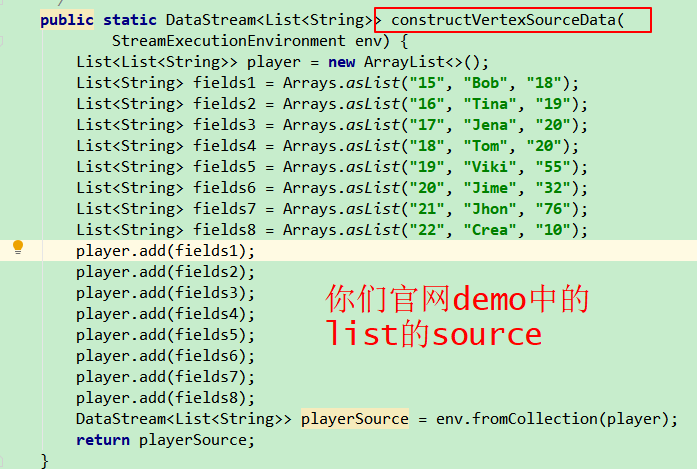
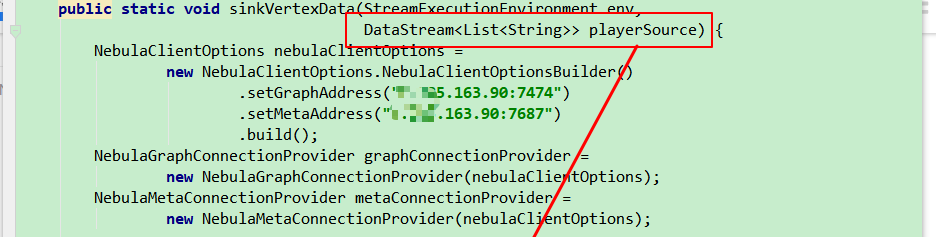
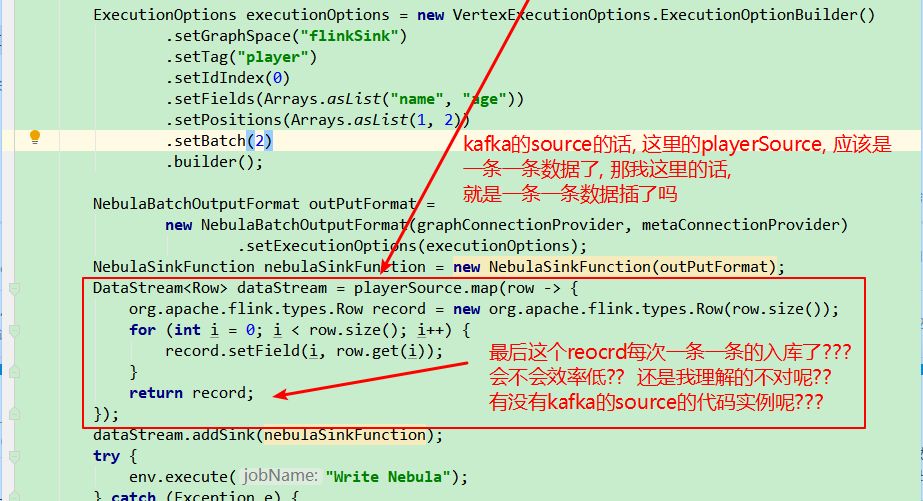
请教下有关Flink的导入Nebula, 我看你们的demo是用的source是一个list然后sink写到Nebula中, 但是实际场景中肯定不是list的source, 我请教下我这里是kafaka的source的话, 这块应该是如何写的呢?
我也是可以自己吧kakfa中的数据处理成一条消息对应假如50行记录, 就是咨询下你, 在用Flink对接Nebula的话, 一条消息是一行记录和多行记录, 它的这写入速度有区别吗??? 最后这个到底是一条一条的写入Nebula还是批量写???
setBatch()可以控制批量大小。flink的kafka-source, 这个没问题, 我这边没问题, 我的疑问就是不知道一条消息放多少行记录合适,既然你刚刚有说明这setBetch这个参数可以设置入库的数据量, 那我理解每条消息放一行记录也没我问题,
我们是打算吧关系数据路的数据读出来放在kafka中去, 然后再往nebula写,
一条消息是一行数据,这里的batch是指积累多少条消息才向Nebula发送一次请求,多条数据的写入非事务。
如果你的数据不足batch数,也可以写入的,当你的dataStream全部处理完成后会调用close,close之前会将未满batch的数据写入。
完全明白, 感谢 
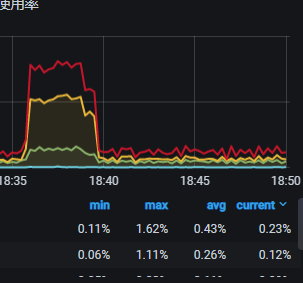
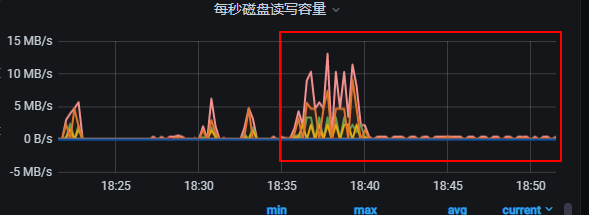
写入过程中磁盘io有关注么,看是不是写入瓶颈在磁盘写
你好,
这个绝对不会是机器的问题, 我们用的是生产的机器, 性能很高的SSD , IOPS测试能达到10W+
你看着监控太低了
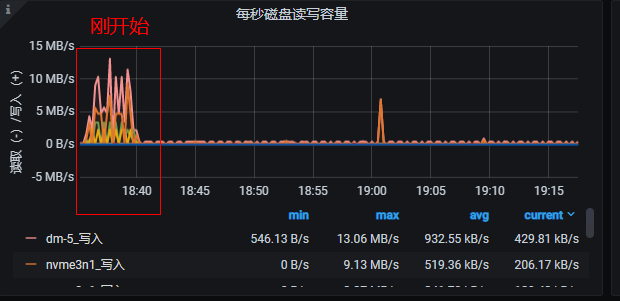
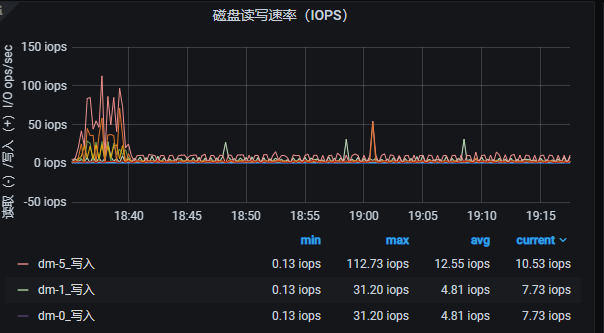

你好, 我刚刚有重新开始导入,
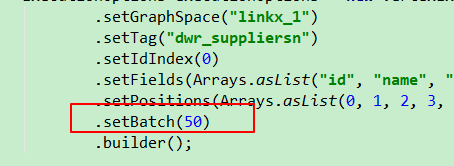
你看这个速度正常吗??? 我setbatch=50, CPU=8core (env.setParallelism(8) 这个并发就是写入的并发数吗???)