是的,parallelism是写入并发度。 你的batch太小了,可以调大到1000-2000来提高写入速度。
你好, Nebula有没有直接导入关系型数据库(oracle, mysql等等) 方法, 不经过kafka???
Exchange工具本身就支持mysql 数据源直接导入NebulaGraph啊
https://docs.nebula-graph.com.cn/2.0.1/nebula-exchange/use-exchange/ex-ug-import-from-mysql/
哦哦, 其实我们的数据源在GaussDB中(华为的分布式关系型数据库), 不过支持直接从neo4j中导入, 我们可以试试速度


NebulaGraph 2.0是支持NULL值的。针对字符串数据,如果对应的值是null(空),导入到NebulaGraph中则是NULL; 如果对应的值是“null”(非空,是字符串“null”),导入到NebulaGraph中的则是“null”值。
当你的字符串值是“null”时,你期望的结果是什么,是null还是“null”?

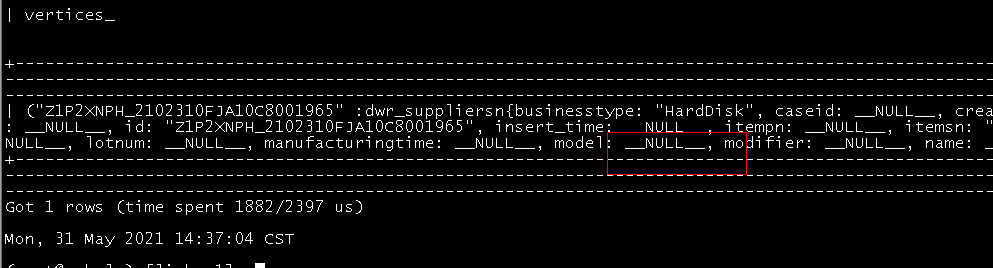
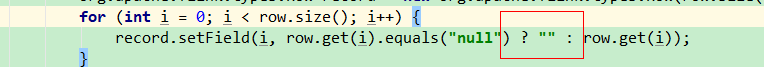
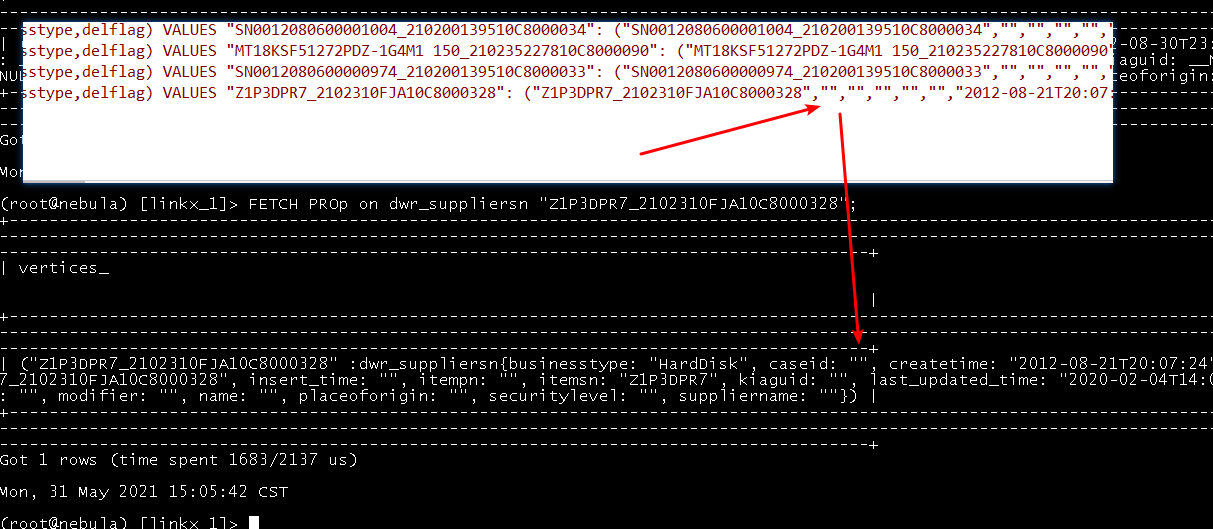
应该是个bug,以前没有null类型,没考虑好这块,在NebulaUtils里面的extraValue要加一个对null的特别处理应该就好了。如果value == null,直接返回null。
你直接写null就好啊,数据直接是 null,而不是"null"或者“”。 2.0是支持“null”、“”和null的,这三者是不同的。
你的这个代码这样写:
record.setField(i, row.get(i).equals("null")? null: row.get(i))这样在代码中写是不行的, 我已经试过了
String.valueOf会把null转成“null”,感谢提出,我这边fix一下。
@yangmeng https://github.com/vesoft-inc/nebula-flink-connector/pull/11, 可以用这个pr导入null值。
我先导入字符串"null" 来测试了, 感谢回答

语法错误, 你的数据有\7500啊
你好, 有发现了一个不知道算不算是BUG, 你看我数据, VID和第一个属性是取的同一个数据, 但是属性他会自动转移特殊字符, 但是VID没有转义导致报错, 这种情况的话,我还不能在代码中手动转义, 要不然VID好了, 属性又不对了, 实在不行又要多加一列专门为VID处理一下
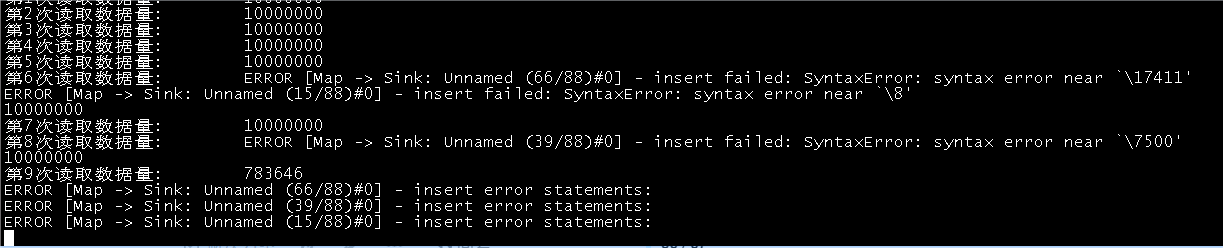

是的,处理转义的时候只对属性进行了处理,没有处理String类型的vid。 欢迎来提一个fix的pr呀~
这个是啥意思呢? ![]()
可以加一下对string类型vid的处理逻辑,然后给我们提pr,成为我们的contributor呀~
https://docs.nebula-graph.com.cn/2.0.1/15.contribution/how-to-contribute/
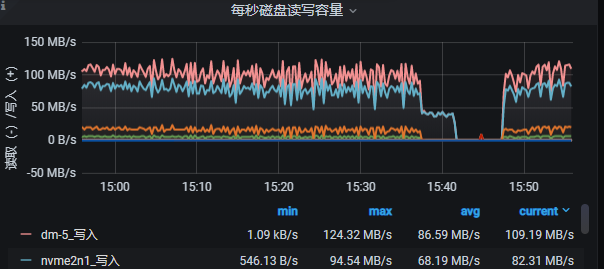
你好, 你们有测试过Flink写入的性能瓶颈吗??
我这里setBatch(1000), 和(500) 监控写入已经没啥变化了, 并发都是88