- nebula 版本:1.2.1
- 部署方式(分布式 / 单机 / Docker / DBaaS):分布式
- 是否为线上版本:Y
- 硬件信息
- 磁盘( 推荐使用 SSD): SSD
- CPU、内存信息 : 32C,256G
- 问题的具体描述
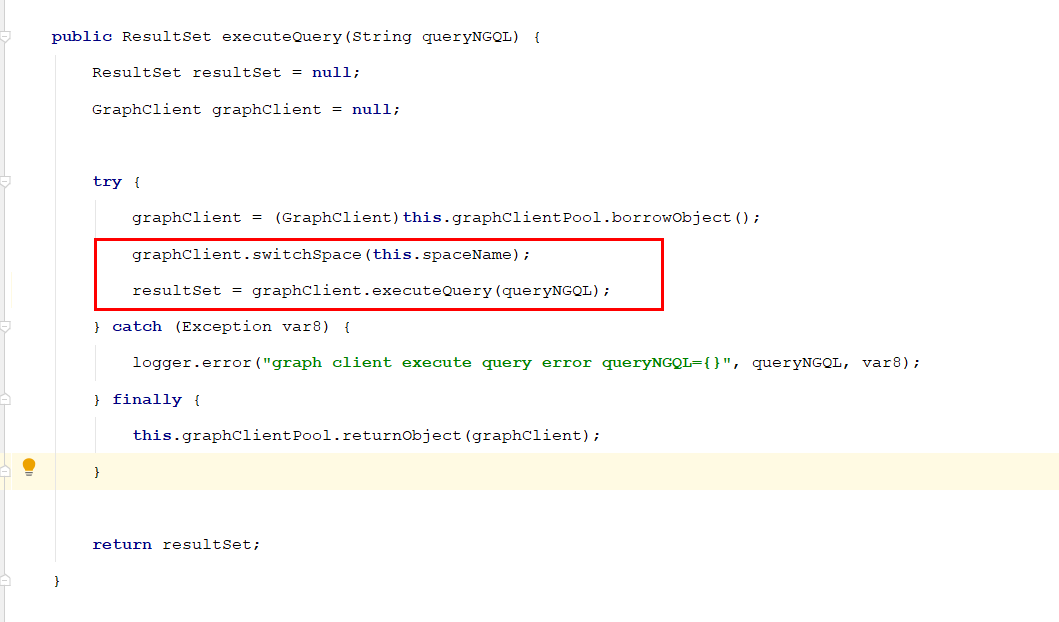
使用nebula-java-1.2.0版本连接 nebula-1.2.1图数据库。
在每次执行NGQL之前,都会进行switch space,然后再执行NGQL。
现在发现请求量大时,use space 这样的命令,就会给返回 space not found。【请求量小时,没有问题】
这个用户,对于切换空间来说,是DBA角色,正常来说 不应该会出现上述的情况。
辛苦帮忙看看下,是不是有什么配置拒绝过于频繁的进行切换space呢?
java执行NGQL的代码截图:
错误的日志截图:
谢谢你的回复。
不是的,space是应用上线之前提前就建好的,不是动态创建的。
【奇怪的是,之前使用1.2.0的版本没发现这个问题。升级成1.2.1版本之后,才出现这个问题】
谢谢你的回复,辛苦。
目前集群有三个 metad进程,一个leader,两个follower。
我去尝试下你的建议,看看show spaces 的结果。
测试之后的结果再回复你。
团队一个同事,查阅了源码,发现了这个问题的原因,是nebula-1.2.1的一个bug,并且已修复。
下面是具体的原因,请参考:
a. 应用程序通过nebula-java 连接到graphd进程。在执行use space时,graphd进程中的 meta-client线程 会与 meta-server 的leader或者follower进行通信。
b. 如果meta-client 与 meta-server的leader进行通信时,meta-server就会返回当前的space,use space执行成功。
c. 如果meta-client 与 meta-server的follower进行通信时,meta-server就会返回一个LeaderChanged的response【该reponse中带一个metaserver的leader地址】,意思是让meta-client去 连接meta-server 的leader,获取元数据信息。
d. 但meta-server 并没有返回该response,导致meta-client无法请求到正常meta-server的leader,最终引起 use space命令报错。
e. 有一种粗暴的解决方案,就是在use space之前,执行一次 show space,meta-server 会成功的返回 LeaderChanged的response。再继续执行 use space,就可以成功了。
1 个赞
d. 但meta-server 并没有返回该response,导致meta-client无法请求到正常meta-server的leader,最终引起 use space命令报错。
假如是这样,这是 bug,是我们已知的问题,这需要将所以错误码处理的地方统一修改,在2.0的已经是修复的,1.0的暂时不修复了,感谢你的反馈。