我第一次给您截的图就是nebula-storaged.INFO的 ![]()
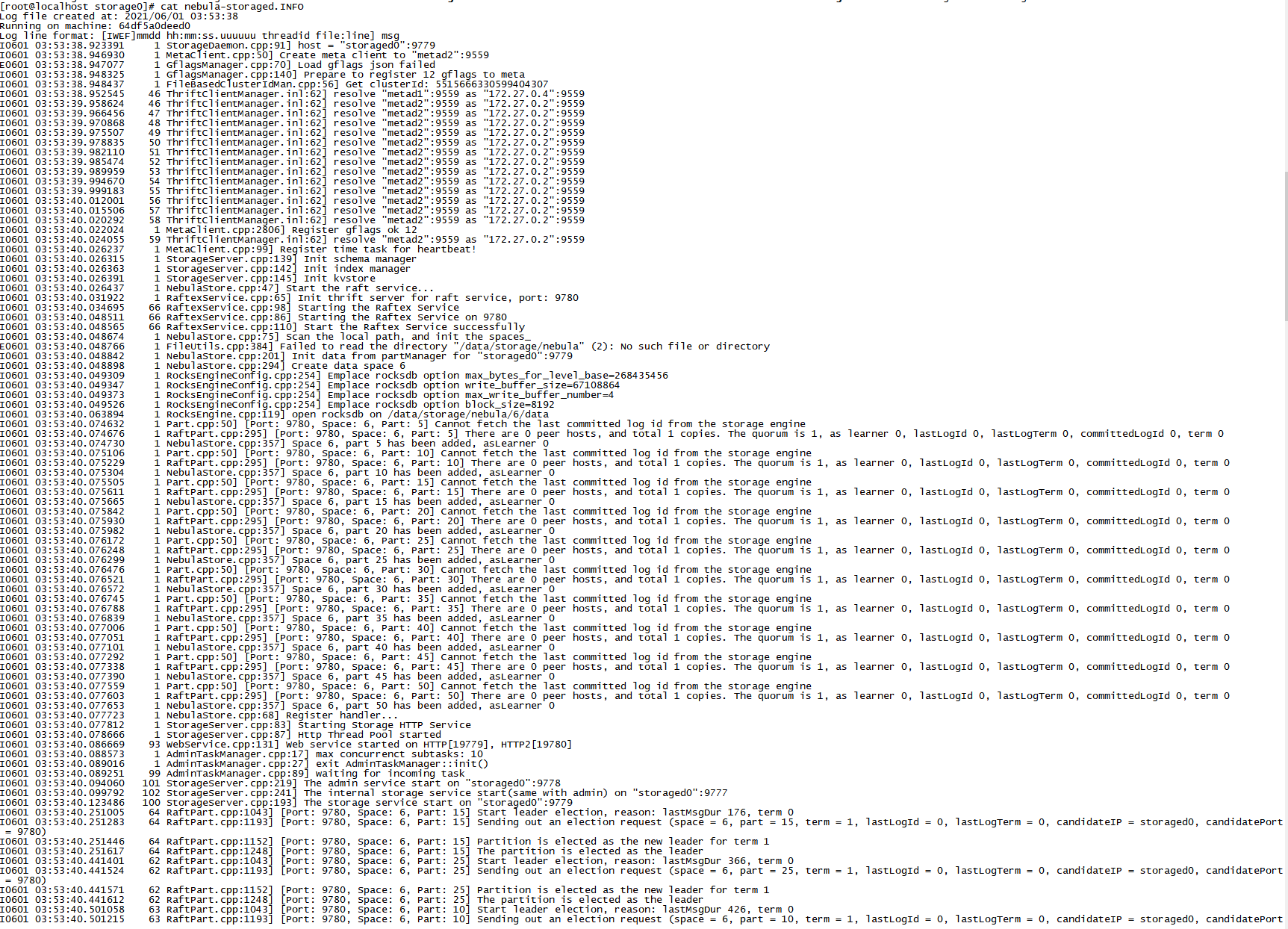

啊? 这后面就没有啦?
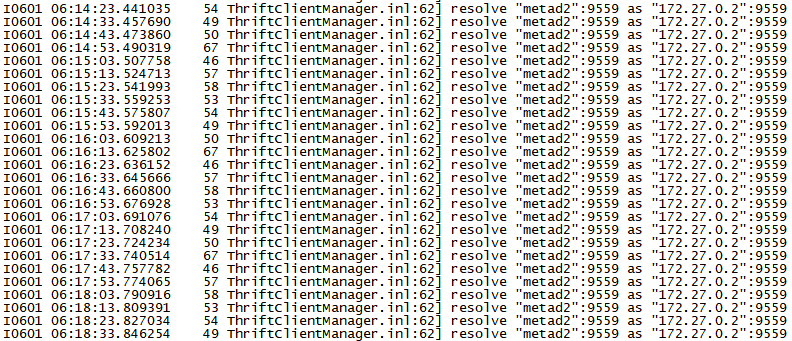
这台 storaged 感觉没干啥呢? 也没报什么错. 看您说现在有5 个 storaged, 别的 storaged log 有啥特别的吗?
都差不多 没啥特别的 
就从这个图看, 能得到个结论是 storaged 到 metad 的网络不稳, 但是没断
(因为这个东东, 是个保活的模块, 会不停地发心跳, 如果网络没断就不会重新去 resolve)
在有问题的那个storage机器检查下和meta的链接,netstat -antp或者ss -nt 之类的
并发数设小一点,是可以成功导入的,导入速度大概在1.2w/s,一旦并发数设大一点,导入速度大于2w/s,就会报这个错,能不能调整一下什么参数,优化一下性能啊
嗯… 其实我们一般推荐是在 SSD 上跑 rocksdb, HDD 就是验证下功能, 速度差很多的.

rocksdb compaction 这东西耗 CPU, 然后您是 HDD, 写盘又慢…
我关了compaction感觉也没啥用
后端存储支持Hbase嘛
这个 graphd CPU 也好高, 是在查询吗?
在导数据
看这个 CPU 跟内存的比率是比较尴尬 . 先赖 HDD…
目前在导6kw的节点和16亿条边,在使用HDD的情况下,有没有比较好的方案呢
我也遇到了同样的问题,集群中一台服务器的storage到metad的网络有问题,connection failed导致插入数据部分失败。我这边是ssd,且其他的storaged都没问题。请问由什么好办法吗?
