nebula 版本:2.0.1
用的nebula-spark-connector 2.0的版本:nebula-spark-utils/README_CN.md at v2.0.0 · vesoft-inc/nebula-spark-utils · GitHub
部署方式(分布式 / 单机 / Docker / DBaaS):单机
是否为线上版本:N
问题的具体描述:使用spark-connector将hive数据导入到nebula2.0.1中,报错。
建立边的语句:
CREATE EDGE APPLYER2CONTACTOR(ID_NO_APPLYER string,ID_NO_CONTACTOR string,CREATED_DATETIME timestamp,LAST_MODIFIED_DATETIME timestamp);
外部参数:
edge_sql="select id_no_applyer_tag_id,
id_no_contactor_tag_id,
ID_NO_APPLYER,
ID_NO_CONTACTOR,
CREATED_DATETIME,
LAST_MODIFIED_DATETIME
from(
select applyer.id_no as id_no_applyer_tag_id,
contack.id_no as id_no_contactor_tag_id,
applyer.id_no ID_NO_APPLYER,
contack.id_no ID_NO_CONTACTOR,
unix_timestamp(nvl(contack.created_datetime,to_timestamp('9999-12-31 23:59:99','yyyy-MM-dd HH:mm:ss'))) as CREATED_DATETIME,
unix_timestamp(nvl(contack.last_modified_datetime,to_timestamp('9999-12-31 23:59:99','yyyy-MM-dd HH:mm:ss'))) as LAST_MODIFIED_DATETIME,
row_number() over(partition by applyer.id_no,contack.id_no order by contack.last_modified_datetime desc) as rn
from APPLY_INFO as applyer
inner join CONTACT as contack
on applyer.app_no=contack.app_no
where applyer.ds='${data_date}'
and contack.ds='${data_date}'
and applyer.id_no is not null
and contack.id_no is not null
)t where rn=1"
edge="APPLYER2CONTACTOR"
source_vertex="id_no_applyer_tag_id"
target_vertex="id_no_contactor_tag_id"
spark-connector的代码:
/* Copyright (c) 2020 vesoft inc. All rights reserved.
*
* This source code is licensed under Apache 2.0 License,
* attached with Common Clause Condition 1.0, found in the LICENSES directory.
*/
package com.vesoft.nebula.examples.connector
import com.facebook.thrift.protocol.TCompactProtocol
import com.vesoft.nebula.connector.{NebulaConnectionConfig, WriteNebulaEdgeConfig, WriteNebulaVertexConfig}
import com.vesoft.nebula.connector.connector.NebulaDataFrameWriter
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import org.apache.spark.storage.StorageLevel
import org.slf4j.LoggerFactory
object NebulaSparkEdgeWriter {
private val LOG = LoggerFactory.getLogger(this.getClass)
def main(args: Array[String]): Unit = {
println("----------neubla的配置信息如下所示:----------")
val space: String = args(0).trim
val appName: String = args(1).trim
val dataBase : String= args(2).trim
val dataDate : String= args(3).trim
val userName: String = args(4).trim
val passwd:String = args(5).trim
val metaAddress: String = args(6).trim
val graphAddress: String = args(7).trim
val edgeSql: String = args(8).trim
val edgeName: String = args(9).trim
val srcIdField: String = args(10).trim
val dstIdField: String = args(11).trim
val batch:Int = args(12).trim.toInt
println("edgeSql:"+edgeSql)
println("edgeName:"+edgeName)
println("srcIdField:"+srcIdField)
println("dstIdField:"+dstIdField)
println("batch:"+batch)
println("-------------------------------------------")
val spark = SparkSession.builder().master("yarn").appName(appName).enableHiveSupport().getOrCreate()
spark.sql("use " +dataBase)
val dataSet1: Dataset[Row] = spark.sql(edgeSql)
val dataFrame1: DataFrame = dataSet1.toDF()
writeEdge(dataFrame1,metaAddress,graphAddress,userName,passwd,space,edgeName,srcIdField,dstIdField,batch)
spark.close()
sys.exit()
}
def writeEdge(dataFrame: DataFrame,metaAddress: String,graphAddress: String,userName:String,passwd:String,space: String,edgeName: String,srcIdField: String,dstIdField: String,batch:Int): Unit = {
dataFrame.show(10,false)
dataFrame.persist(StorageLevel.MEMORY_AND_DISK_SER)
val config =
NebulaConnectionConfig
.builder()
.withMetaAddress(metaAddress)
.withGraphAddress(graphAddress)
.build
val nebulaWriteEdgeConfig: WriteNebulaEdgeConfig = WriteNebulaEdgeConfig
.builder()
.withUser(userName)
.withPasswd(passwd)
.withSpace(space)
.withEdge(edgeName)
.withSrcIdField(srcIdField)
.withDstIdField(dstIdField)
.withSrcAsProperty(false)
.withDstAsProperty(false)
.withBatch(batch)
.build()
dataFrame.write.nebula(config, nebulaWriteEdgeConfig).writeEdges()
}
}
程序中打印出来的日志:

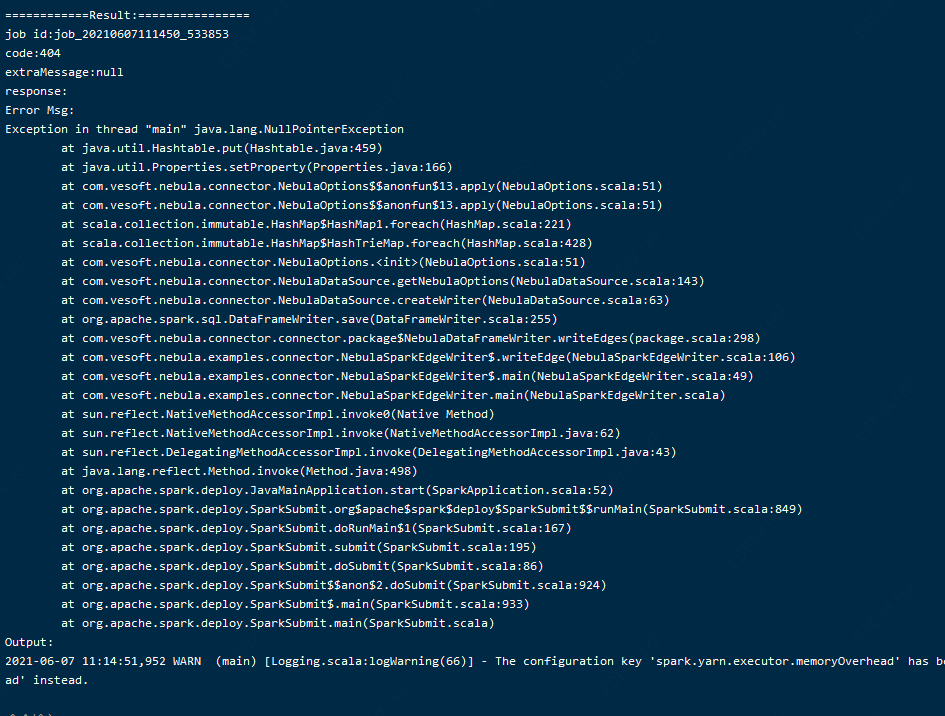
麻烦看下,边的sql已经把null的数据过滤掉了,但是报nullpointerException,不是很理解
