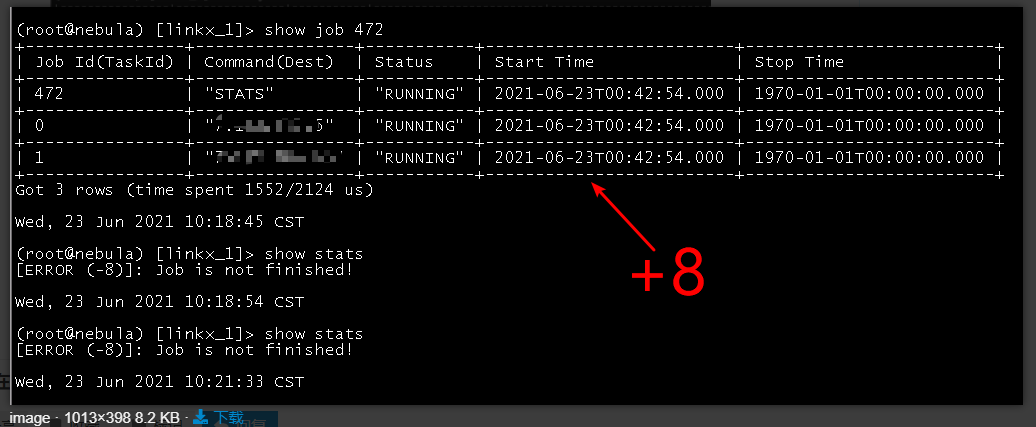
我看你batch设置只有200, Flink env的并发是配置的几。
磁盘写速度降下去的时候看下内存占用率吧, 如果不高可以配置下env的并发度,并把batch设置高一点(可设置1000)
是这样的, 我本地调试时用的200, 放到环境去执行使用的1000, 默认并发就是88 服务器是88core, 750G内存 的
关键是err日志中没有其他的日志了, 我没发定位这慢的原因

确定没问题么,每次切换space都会请求meta,这个速度是很慢的

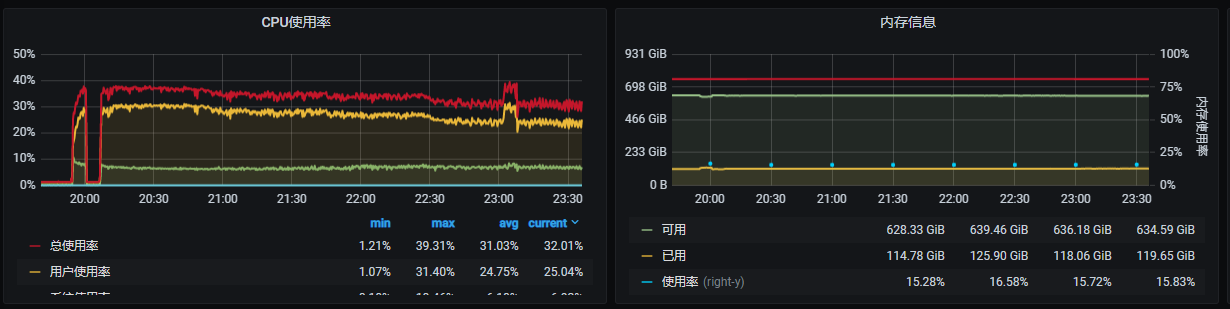
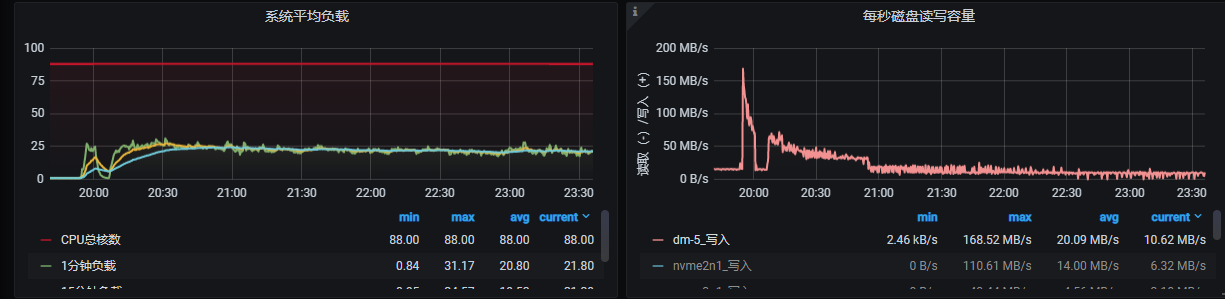
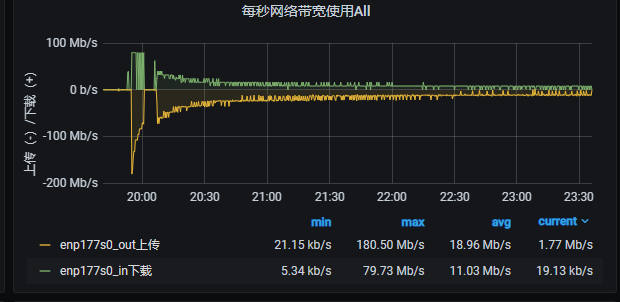
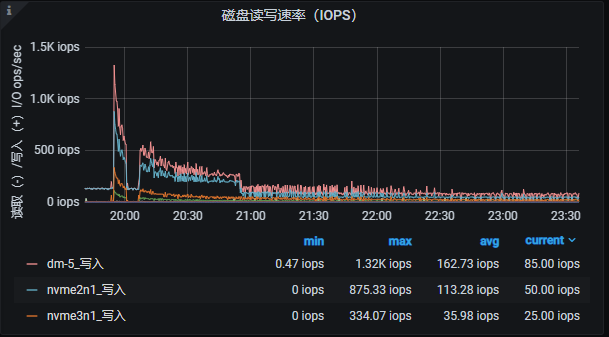
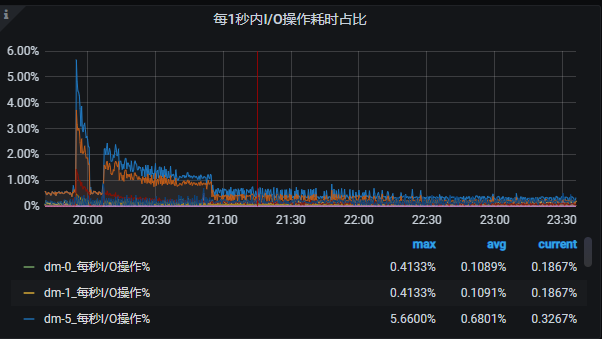
这是之前的高速导入时候的监控截图, 磁盘的写入和网络绝对不是瓶颈, 可以轻松上GB级别, IOPS也是10W+ 的随机读写, 上次的时候也是速度在慢慢降低, 但是最后还是稳住在100mb/s的速度导入了100亿数据
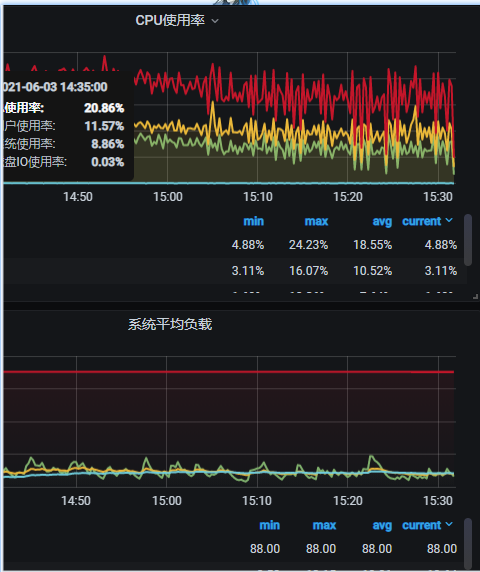
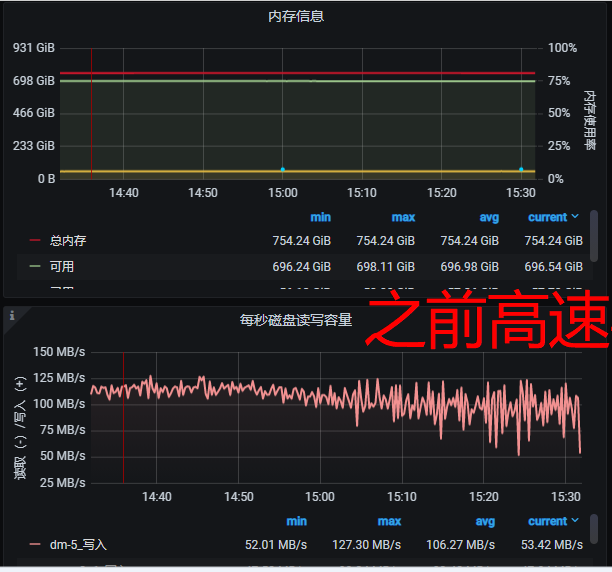
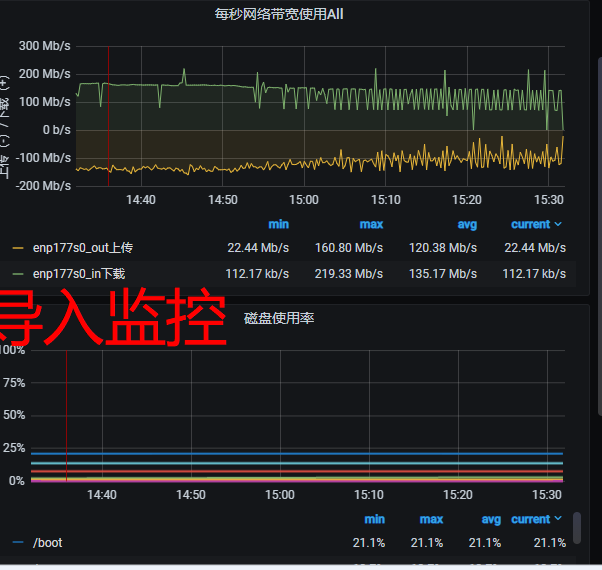
- 你看到nebula的data目录 目前数据量多大。
- NebulaGraph的安装方式是什么、如果是集群的话集群规模是多少
-
之前高速和现在,是使用同一个集群的同一个 space 么,还是两个集群?
现在速度比较慢的时候,space 的磁盘大小有多大,你们有统计这个 space 一共插入了多少条数据么? -
你是用的 docker-compose 么,多个 storage 实例是共用一个磁盘,还是每个实例一个磁盘。
-
能贴一下你 storage 的配置么?


你好
-
是同一个集群, 用一个space, space 的id都是357
-
是 docker-compose , 每个storage是一个独立机器,
-
配置
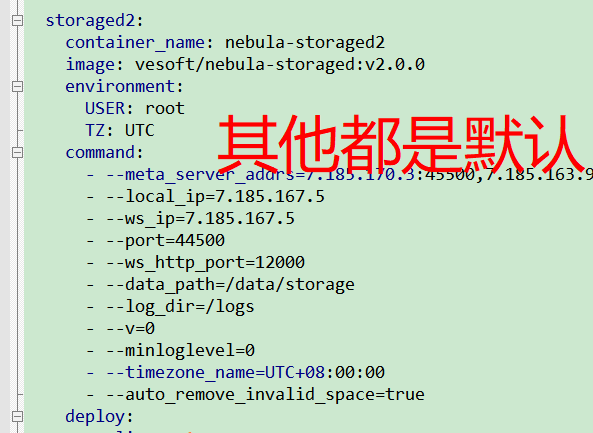
对了, 还有这个

建索引后写入肯定会慢的。
这2次不是同一个表, 那个问题就是单纯咨询有索引的话速度会慢很多
这次是我新建的一张新表, 没有索引的
具体是这样的, 上次的(假如A表)点有88亿, 已经导入完成, 并且已经建立索引, 这次导入的是点A表的自循环关系数据, 不知道这个有没有影响?>>
@nicole 我验证了一下, 怀疑是索引问题导致的, 具体步骤如下
- 我新建了一个spaces, 新建了这个关系, 整个space就只有一个关系
然后我用同样的代码导入, 你们看这速度
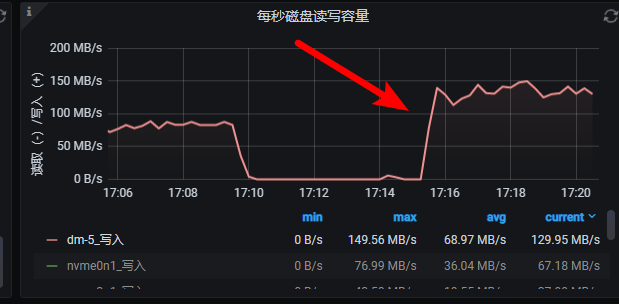
2, 那么问题来了, A点的话有88亿, 上次已经导入完成, 并且建立了索引, 现在的B关系是A点的自循环, 现在导入B关系数据的话, A的索引是对B关系导入有影响的??? (我现在删除了A点的索引再试试, 但不知道删除索引快不快,)
3, 我删除完索引后在开始导入, 可以看到正常了
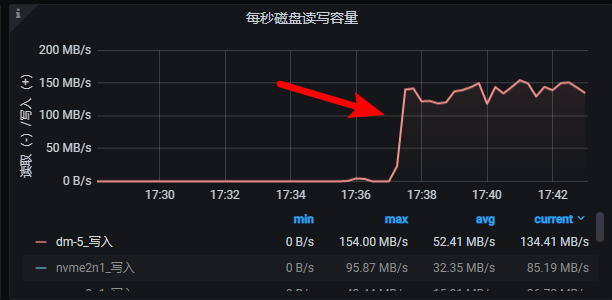
额,你再观察观察,A建立的索引与边的导入速度没关系的。 你删掉了索引相当于该space 占用的磁盘少了,应该和删掉一部分数据起到的效果一样。
1 那就奇怪了, 我昨天这边的结果是已删除索引,就导入速度OK了,
@nicole @Shylock-Hg 大佬求助, 紧急问题 ![]()
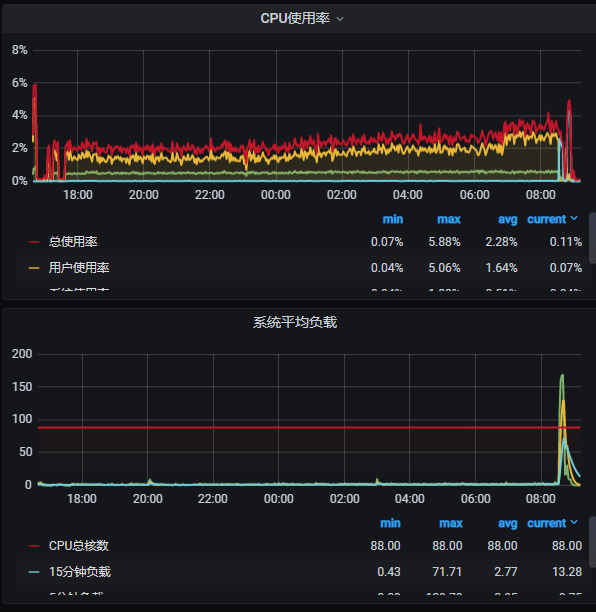
2. 新问题: 从昨天18点开始导入88亿数据, 跑到今天早上快9点了, 出问题了, 集群的master节点的机器一直自动挂了重启, 导致我这个导入是但副本数据也报错了, 至于这master节点挂了的原因是/var/lib/docker/overlay2目录问题太大了, 暴增到100% 导致我的 “/” 分区也100% , 每次master自动重启的话会立马释放这个目录空间,但是没过多久又会暴增, 其实这个问题已经出现这是第三次了, 之前都是重启解决 大佬知道这啥原因吗??? (备注: docker是默认路径安装的)
百度结果: https://www.cnblogs.com/wswang/p/10736726.html 大佬看下这个解释靠谱吗?? 如果靠谱的话, 那为啥nebula会一直重启呢???

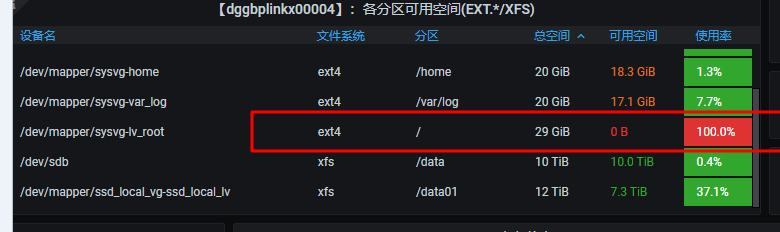
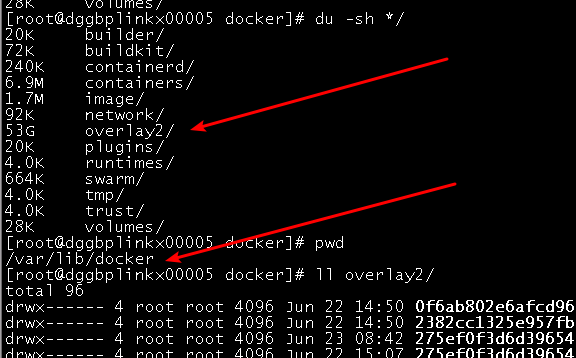
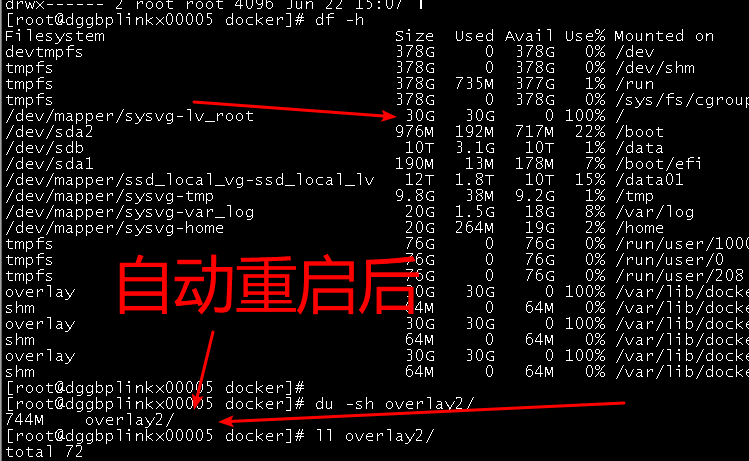
监控信息:
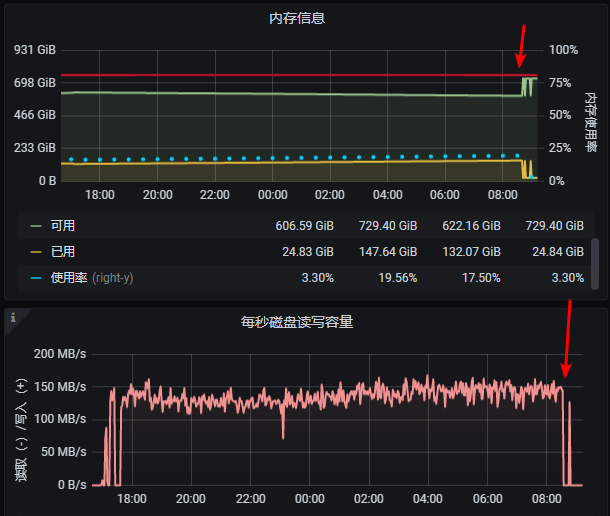
也可以考虑把 docker 目录从 / 中移动到另一个地方。停了 docker 服务,移动到新的地方,改 docker 配置里的路径,启动docker 服务