nebulaGraph2.0.1
meta 3 个,stoaged 6 个, graph 6 个, 备份3
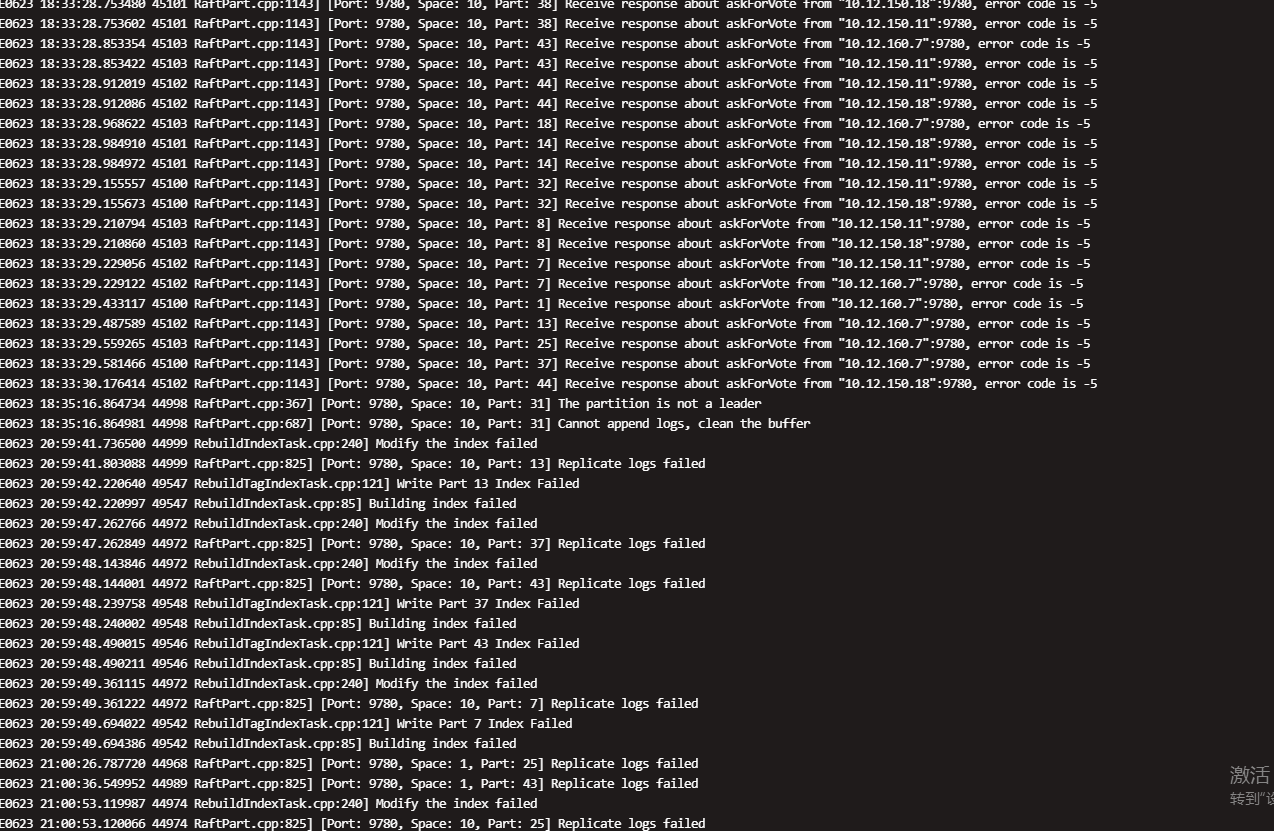
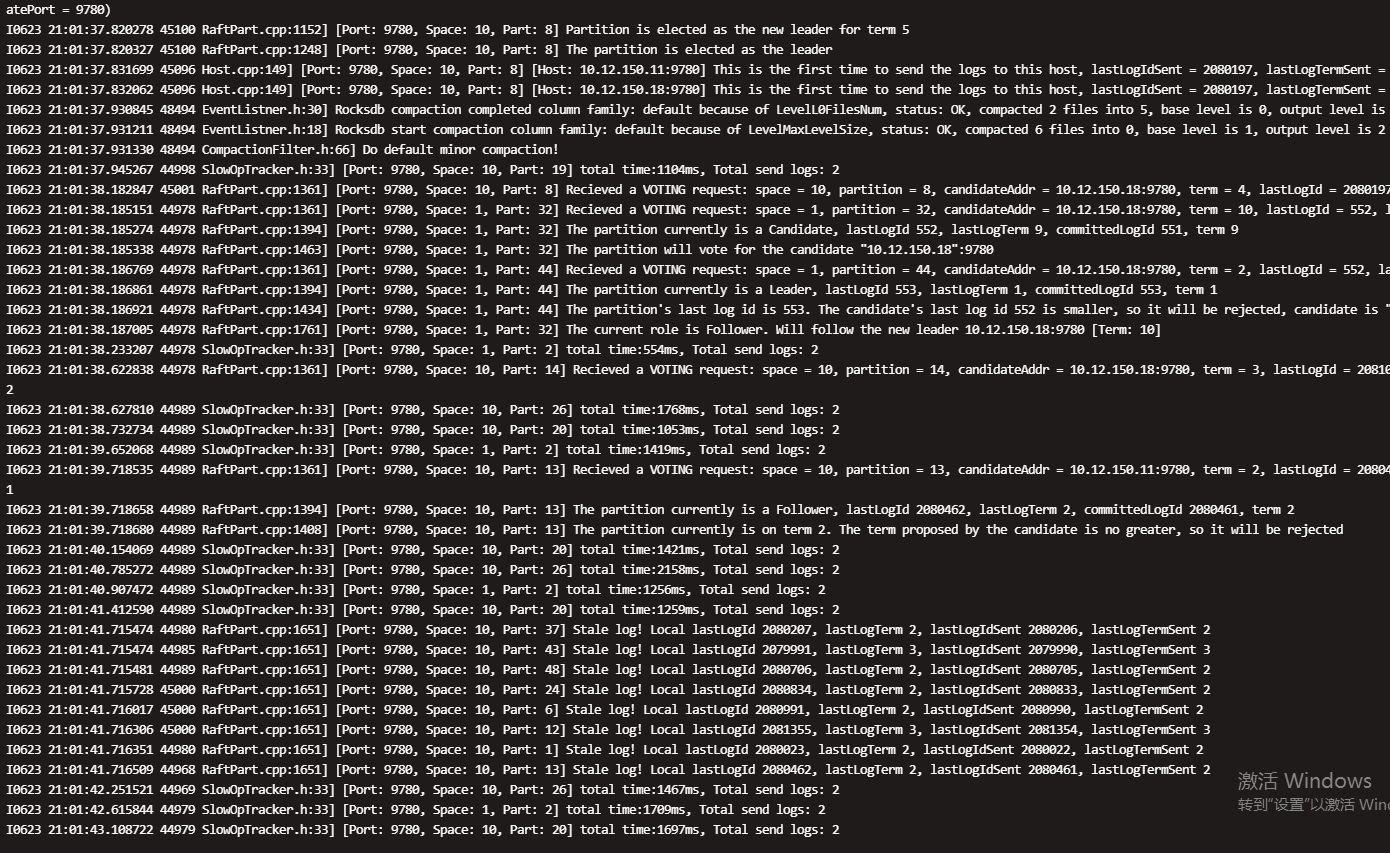
用spark 导入数据,中途发现有部分storage节点挂了,这样导入数据会有问题吗 ,后来show hosts ,leader 不平衡,balance 后rebulid索引一直不成功
nebulaGraph2.0.1
meta 3 个,stoaged 6 个, graph 6 个, 备份3
用spark 导入数据,中途发现有部分storage节点挂了,这样导入数据会有问题吗 ,后来show hosts ,leader 不平衡,balance 后rebulid索引一直不成功
是不是Spark 并发太高了
Balance Leader 和 Rebuild Index 没什么关系吧
show host 看一下 leader 分配是不是成功了
spark 并发可以的,我导入了好多次都可以的,只是今天导入出现了这个问题
那应该是nebula 集群状态的问题
nebula-storaged.bj2157.service.log.ERROR.20210623-175435.44957 (44.6 KB) nebula-storaged.bj2157.service.log.INFO.20210623-175434.44957 (2.3 MB) nebula-storaged.bj2157.service.log.WARNING.20210623-175435.44957 (63.0 KB)
这是storaged 日志 ,导入时间昨晚18.30 开始,麻烦帮看看什么问题
你好,请问有core文件吗?另外,磁盘是SSD吗?
core 什么文件?? 是ssd
这个什么问题,可以解决吗,这边在测试中,如果不行这边卸载重新装,这边感觉数据有点乱了,
storage挂掉有很多可能,有可能是操作系统的限制,把进程杀掉了;也有可能是OOM了,也有可能是bug导致。一般进程挂掉后,会生成一个core.xxxx的文件,可以通过这个core文件破案。
如果没有生成core文件,执行以下命令后再观察一下,下次挂掉就会有core文件了:
ulimit -c unlimited
如果有core.xxx 文件,执行下边命令查看一下堆栈:
gdb nebula-storaged core.xxx
bt
在那个目录,好像没看到core,这边在导入测试一下。我重新安装了,把问题数据都删除了,看看能个不能重现这个问题
现在我 lookup 语句不加过滤条件查询一下,数据量大了,storaged 就挂了,这是什么原因啊,还有你说的core 在那个文件目录,这边没有找到啊只有logs 文件
lookup不加where条件的话,相当于full index scan。是oom了。如果需要统计数量值,建议用stats:
https://docs.nebula-graph.io/2.0/3.ngql-guide/7.general-query-statements/6.show/14.show-stats/
那这个怎么解决啊。如果有用户控制台测试写lookup 语句,没加过滤条件吧storaged 高挂了,那这不是出事故了 ,生产环境不能随便挂服务的啊
这个问题很严重啊。随便写个语句storaged 就挂了,这个他不稳定了吧,这个你们要加限制控制啊
还有问下,创建索引如果数据量很多,是不是也会ooM 导致storaged 挂掉啊
问下这storaged 的内存在那设置一下,避免OOM,服务器内存64 G 的应该够用的啊,还是你们程序里面设置了初始内存大小啊,这边可以在那个配置文件里面改大一些吗
内存控制和limit在开发了