- nebula 版本:v2.0.0
- 部署方式:分布式(3台)
- 硬件信息
- 磁盘:SSD
- CPU、内存信息:8核、64g
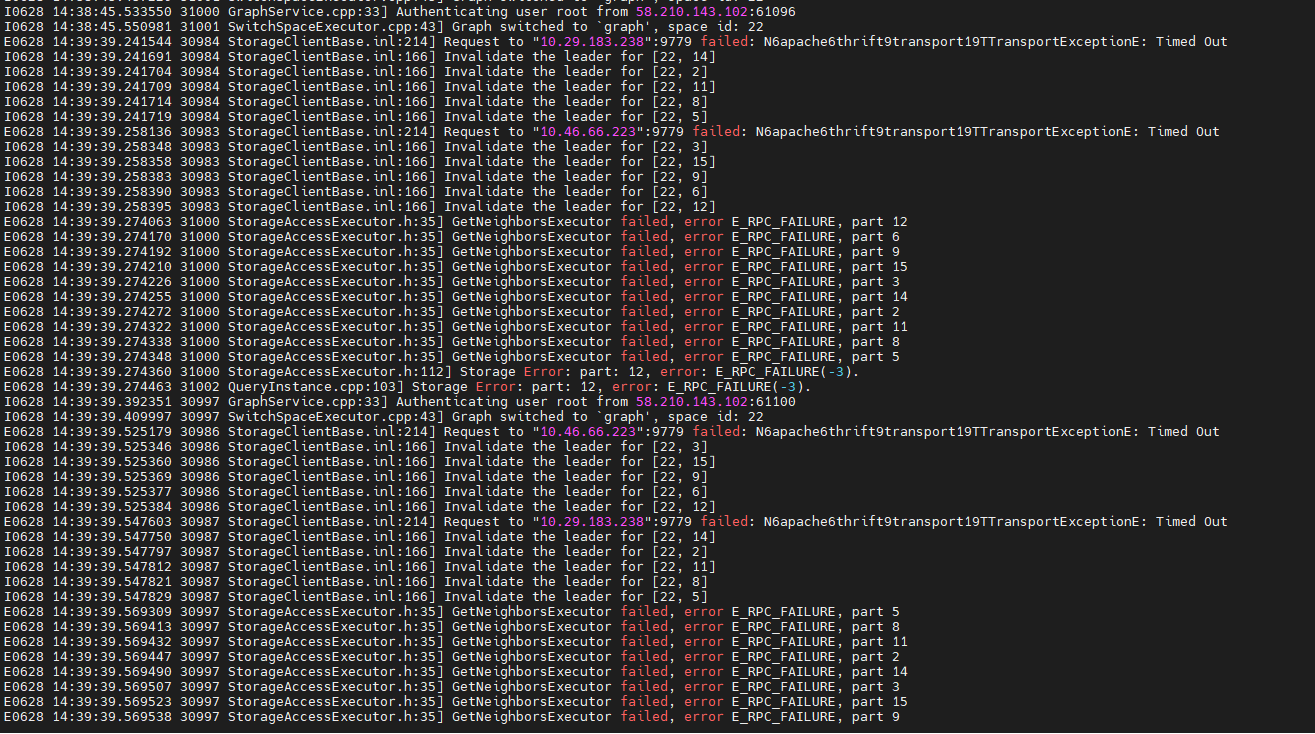
我使用javaclient,测试路径查询并发性能,当层数设置为15层时会出现超时并报错,当把层数减少为10层时则会在测试一段时间后出现相同报错,日志如下所示。
我的java程序如下所示:
我的query如下,并发时具体id会有变化。
FIND SHORTEST PATH FROM ‘idA’ TO ‘idB’ OVER * BIDIRECT UPTO 10 STEPS ;
我的数据包含5亿个点和7亿个边。
我的问题:
1.出现这种报错的原因是因为查询太复杂时间太长导致的吗,有没有什么规避的方法?
2.我测试使用的jmeter,启动10个线程2秒一次,测试发现三台机器的cpu都爆满,内存占用率反而不高,吞吐量在2-3个查询每秒,请问路径查询的并发效率和查询效率以后的版本还有没有优化的空间,还是说只能通过加配置来解决?
3.并发的过程中storaged服务占用的cpu资源大于graphd,这是为什么?
4.在官方文档中描述路径的查找是单线程,会占用很多内存。请问单线程的含义是什么,每个graphd服务每次只能处理一个路径查找query吗?
我们是广度优先,如果数据量比较大,你的跳数比较多的时候,有可能内存溢出,然后服务挂了。
1.出现这种报错的原因是因为查询太复杂时间太长导致的吗,有没有什么规避的方法?
加大内存,我们目前在优化内存这部分的逻辑,以后会执行时间变的更长,但是不会 OOM。
可以考虑下你实际的业务,这么多跳,是否可以放离线去做。
2.我测试使用的jmeter,启动10个线程2秒一次,测试发现三台机器的cpu都爆满,内存占用率反而不高,吞吐量在2-3个查询每秒,请问路径查询的并发效率和查询效率以后的版本还有没有优化的空间,还是说只能通过加配置来解决?
可以设置 storage 的 block cache。Storage服务配置 - NebulaGraph Database 手册
3.并发的过程中storaged服务占用的cpu资源大于graphd,这是为什么?
storage 需要扫数据
4.在官方文档中描述路径的查找是单线程,会占用很多内存。请问单线程的含义是什么,每个graphd服务每次只能处理一个路径查找query吗?
文档写的有点歧义。
是指一个 query 在 graph 是一个线程在处理。
3 个赞
system
关闭
3
该主题在最后一个回复创建后7天后自动关闭。不再允许新的回复。