
配置文件贴一下,感觉是配置没配置好
配置文件,导入命令都发一下
{
# Spark相关配置
spark: {
app: {
name: Nebula Exchange 2.0
}
driver: {
cores: 1
maxResultSize: 1G
}
executor: {
memory:1G
}
cores {
max: 16
}
}
# Nebula Graph相关配置
nebula: {
address:{
# 指定Graph服务和所有Meta服务的IP地址和端口。
# 如果有多台服务器,地址之间用英文逗号(,)分隔。
# 格式: "ip1:port","ip2:port","ip3:port"
graph:["127.0.0.1:9669"]
meta:["127.0.0.1:9559"]
}
# 指定拥有Nebula Graph写权限的用户名和密码。
user: root
pswd: nebula
# 指定图空间名称。
space: basketballplayer
connection {
timeout: 3000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/errors
}
rate: {
limit: 1024
timeout: 1000
}
}
# 处理点
tags: [
# 设置标签player相关信息。
{
# 指定Nebula Graph中定义的标签名称。
name: player
type: {
# 指定数据源,使用CSV。
source: csv
# 指定如何将点数据导入Nebula Graph:Client或SST。
sink: client
}
# 指定CSV文件的HDFS路径。
# 用双引号括起路径,以hdfs://开头。
path: "hdfs://http://localhost:50070/basketballplayer/player.csv"
# 如果CSV文件没有表头,使用[_c0, _c1, _c2, ..., _cn]表示其表头,并将列指示为属性值的源。
# 如果CSV文件有表头,则使用实际的列名。
fields: [_c1, _c2]
# 指定Nebula Graph中定义的属性名称。
# fields与nebula.fields的顺序必须一一对应。
nebula.fields: [age, name]
# 指定一个列作为VID的源。
# vertex的值必须与上述fields或者csv.fields中的列名保持一致。
# 目前,Nebula Graph 2.0.0仅支持字符串或整数类型的VID。
# 不要使用vertex.policy映射。
vertex: {
field:_c0
# policy:hash
}
# 指定的分隔符。默认值为英文逗号(,)。
separator: ","
# 如果CSV文件有表头,请将header设置为true。
# 如果CSV文件没有表头,请将header设置为false。默认值为false。
header: false
# 指定单批次写入Nebula Graph的最大点数量。
batch: 256
# 指定Spark分片数量。
partition: 32
}
# 设置标签team相关信息。
{
# 指定Nebula Graph中定义的标签名称。
name: team
type: {
# 指定数据源,使用CSV。
source: csv
# 指定如何将点数据导入Nebula Graph:Client或SST。
sink: client
}
# 指定CSV文件的HDFS路径。
# 用双引号括起路径,以hdfs://开头。
path: "hdfs://http://localhost:50070/basketballplayer/team.csv"
# 如果CSV文件没有表头,使用[_c0, _c1, _c2, ..., _cn]表示其表头,并将列指示为属性值的源。
# 如果CSV文件有表头,则使用实际的列名。
fields: [_c1]
# 指定Nebula Graph中定义的属性名称。
# fields与nebula.fields的顺序必须一一对应。
nebula.fields: [name]
# 指定一个列作为VID的源。
# vertex的值必须与上述fields或者csv.fields中的列名保持一致。
# 目前,Nebula Graph 2.0.0仅支持字符串或整数类型的VID。
# 不要使用vertex.policy映射。
vertex: {
field:_c0
# policy:hash
}
# 指定的分隔符。默认值为英文逗号(,)。
separator: ","
# 如果CSV文件有表头,请将header设置为true。
# 如果CSV文件没有表头,请将header设置为false。默认值为false。
header: false
# 指定单批次写入Nebula Graph的最大点数量。
batch: 256
# 指定Spark分片数量。
partition: 32
}
# 如果需要添加更多点,请参考前面的配置进行添加。
]
# 处理边
edges: [
# 设置边类型follow相关信息。
{
# 指定Nebula Graph中定义的边类型名称。
name: follow
type: {
# 指定数据源,使用CSV。
source: csv
# 指定如何将点数据导入Nebula Graph:Client或SST。
sink: client
}
# 指定CSV文件的HDFS路径。
# 用双引号括起路径,以hdfs://开头。
path: "hdfs://http://localhost:50070/basketballplayer/follow.csv"
# 如果CSV文件没有表头,使用[_c0, _c1, _c2, ..., _cn]表示其表头,并将列指示为属性值的源。
# 如果CSV文件有表头,则使用实际的列名。
fields: [_c2]
# 指定Nebula Graph中定义的属性名称。
# fields与nebula.fields的顺序必须一一对应。
nebula.fields: [degree]
# 指定一个列作为起始点和目的点的源。
# vertex的值必须与上述fields或者csv.fields中的列名保持一致。
# 目前,Nebula Graph 2.0.0仅支持字符串或整数类型的VID。
# 不要使用vertex.policy映射。
source: {
field: _c0
}
target: {
field: _c1
}
# 指定的分隔符。默认值为英文逗号(,)。
separator: ","
# 指定一个列作为rank的源(可选)。
#ranking: rank
# 如果CSV文件有表头,请将header设置为true。
# 如果CSV文件没有表头,请将header设置为false。默认值为false。
header: false
# 指定单批次写入Nebula Graph的最大边数量。
batch: 256
# 指定Spark分片数量。
partition: 32
}
# 设置边类型serve相关信息。
{
# 指定Nebula Graph中定义的边类型名称。
name: serve
type: {
# 指定数据源,使用CSV。
source: csv
# 指定如何将点数据导入Nebula Graph:Client或SST。
sink: client
}
# 指定CSV文件的HDFS路径。
# 用双引号括起路径,以hdfs://开头。
path: "hdfs://http://localhost:50070/basketballplayer/serve.csv"
# 如果CSV文件没有表头,使用[_c0, _c1, _c2, ..., _cn]表示其表头,并将列指示为属性值的源。
# 如果CSV文件有表头,则使用实际的列名。
fields: [_c2,_c3]
# 指定Nebula Graph中定义的属性名称。
# fields与nebula.fields的顺序必须一一对应。
nebula.fields: [start_year, end_year]
# 指定一个列作为起始点和目的点的源。
# vertex的值必须与上述fields或者csv.fields中的列名保持一致。
# 目前,Nebula Graph 2.0.0仅支持字符串或整数类型的VID。
# 不要使用vertex.policy映射。
source: {
field: _c0
}
target: {
field: _c1
}
# 指定的分隔符。默认值为英文逗号(,)。
separator: ","
# 指定一个列作为rank的源(可选)。
#ranking: _c5
# 如果CSV文件有表头,请将header设置为true。
# 如果CSV文件没有表头,请将header设置为false。默认值为false。
header: false
# 指定单批次写入Nebula Graph的最大边数量。
batch: 256
# 指定Spark分片数量。
partition: 32
}
]
# 如果需要添加更多边,请参考前面的配置进行添加。
}
这是exchange的配置 用的数据就是官方文档的数据
导入命令是spark-submit --master "local" --class com.vesoft.nebula.exchange.Exchange /root/nebula-spark-utils/nebula-exchange/target/nebula-exchange-2.0.0.jar -c /root/nebula-spark-utils/nebula-exchange/target/classes/csv_application.conf
配置看着都正常的,我又看了下你的日志截图 最下面一行截了一半的, 应该是你使用的spark版本不对。
ps 这个截图是真神~
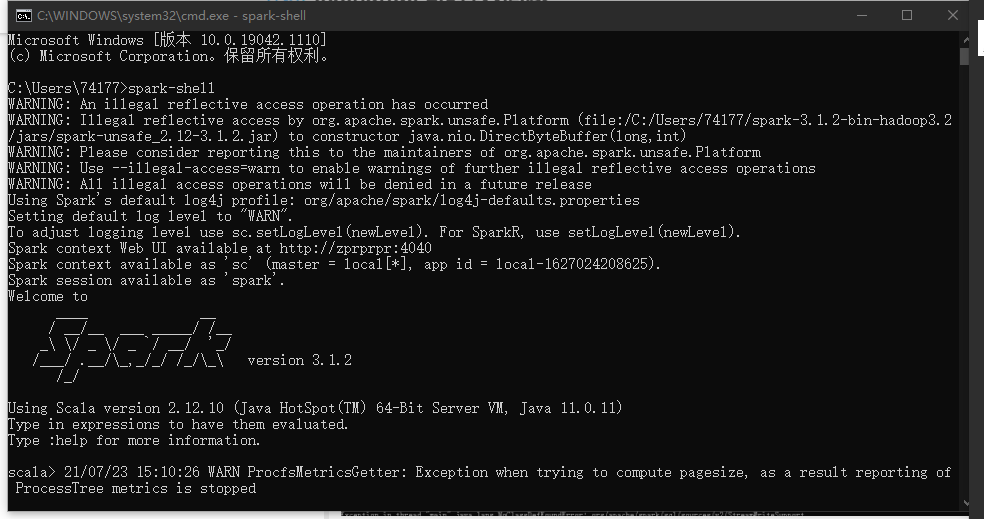
这个版本目前不兼容, 可以用2.4.0.
文档中有说明的https://docs.nebula-graph.com.cn/2.0.1/nebula-exchange/about-exchange/ex-ug-limitations/
我更换了文档里的scala spark兼容版本 但是还是报错
C:\Users\74177\spark-2.4.8-bin-hadoop2.6>spark-submit --master "local" --class com.vesoft.nebula.exchange.Exchange /Users/74177/nebula-spark-utils/nebula-exchange/target/nebula-exchange-2.0-20210519.071301-1.jar -c /Users/74177/nebula-spark-utils/nebula-exchange/target/classes/csv_application.conf
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/C:/Users/74177/spark-2.4.8-bin-hadoop2.6/jars/spark-unsafe_2.11-2.4.8.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
log4j:WARN No appenders could be found for logger (com.vesoft.nebula.exchange.config.Configs$).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
21/07/23 15:55:51 INFO SparkContext: Running Spark version 2.4.8
21/07/23 15:55:51 INFO SparkContext: Submitted application: com.vesoft.nebula.exchange.Exchange
21/07/23 15:55:51 INFO SecurityManager: Changing view acls to: 74177
21/07/23 15:55:51 INFO SecurityManager: Changing modify acls to: 74177
21/07/23 15:55:51 INFO SecurityManager: Changing view acls groups to:
21/07/23 15:55:51 INFO SecurityManager: Changing modify acls groups to:
21/07/23 15:55:51 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(74177); groups with view permissions: Set(); users with modify permissions: Set(74177); groups with modify permissions: Set()
21/07/23 15:55:52 INFO Utils: Successfully started service 'sparkDriver' on port 61982.
21/07/23 15:55:52 INFO SparkEnv: Registering MapOutputTracker
21/07/23 15:55:52 INFO SparkEnv: Registering BlockManagerMaster
21/07/23 15:55:52 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
21/07/23 15:55:52 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
21/07/23 15:55:52 INFO DiskBlockManager: Created local directory at C:\Users\74177\AppData\Local\Temp\blockmgr-951aad47-6e4f-4db8-8e39-eb9ed625a295
21/07/23 15:55:52 INFO MemoryStore: MemoryStore started with capacity 434.4 MB
21/07/23 15:55:52 INFO SparkEnv: Registering OutputCommitCoordinator
21/07/23 15:55:52 INFO Utils: Successfully started service 'SparkUI' on port 4040.
21/07/23 15:55:53 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://zprprpr:4040
21/07/23 15:55:53 INFO SparkContext: Added JAR file:/C:/Users/74177/nebula-spark-utils/nebula-exchange/target/nebula-exchange-2.0-20210519.071301-1.jar at spark://zprprpr:61982/jars/nebula-exchange-2.0-20210519.071301-1.jar with timestamp 1627026953056
21/07/23 15:55:53 INFO Executor: Starting executor ID driver on host localhost
21/07/23 15:55:53 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 62005.
21/07/23 15:55:53 INFO NettyBlockTransferService: Server created on zprprpr:62005
21/07/23 15:55:53 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
21/07/23 15:55:53 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, zprprpr, 62005, None)
21/07/23 15:55:53 INFO BlockManagerMasterEndpoint: Registering block manager zprprpr:62005 with 434.4 MB RAM, BlockManagerId(driver, zprprpr, 62005, None)
21/07/23 15:55:53 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, zprprpr, 62005, None)
21/07/23 15:55:53 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, zprprpr, 62005, None)
21/07/23 15:55:53 INFO Exchange$: Processing Tag player
21/07/23 15:55:53 INFO Exchange$: field keys: _c1, _c2
21/07/23 15:55:53 INFO Exchange$: nebula keys: age, name
21/07/23 15:55:53 INFO Exchange$: Loading CSV files from hdfs://http://localhost:50070/basketballplayer/player.csv
21/07/23 15:55:53 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('file:/C:/Users/74177/spark-2.4.8-bin-hadoop2.6/spark-warehouse').
21/07/23 15:55:53 INFO SharedState: Warehouse path is 'file:/C:/Users/74177/spark-2.4.8-bin-hadoop2.6/spark-warehouse'.
21/07/23 15:55:53 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
21/07/23 15:55:57 WARN FileStreamSink: Error while looking for metadata directory.
Exception in thread "main" java.lang.IllegalArgumentException: java.net.UnknownHostException: http
at org.apache.hadoop.security.SecurityUtil.buildTokenService(SecurityUtil.java:374)
at org.apache.hadoop.hdfs.NameNodeProxies.createNonHAProxy(NameNodeProxies.java:310)
at org.apache.hadoop.hdfs.NameNodeProxies.createProxy(NameNodeProxies.java:176)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:668)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:604)
at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:148)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2598)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:91)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2632)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2614)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:370)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:296)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$org$apache$spark$sql$execution$datasources$DataSource$$checkAndGlobPathIfNecessary$1.apply(DataSource.scala:561)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$org$apache$spark$sql$execution$datasources$DataSource$$checkAndGlobPathIfNecessary$1.apply(DataSource.scala:559)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:241)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:241)
at scala.collection.immutable.List.foreach(List.scala:392)
at scala.collection.TraversableLike$class.flatMap(TraversableLike.scala:241)
at scala.collection.immutable.List.flatMap(List.scala:355)
at org.apache.spark.sql.execution.datasources.DataSource.org$apache$spark$sql$execution$datasources$DataSource$$checkAndGlobPathIfNecessary(DataSource.scala:559)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:373)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:242)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:230)
at org.apache.spark.sql.DataFrameReader.csv(DataFrameReader.scala:641)
at org.apache.spark.sql.DataFrameReader.csv(DataFrameReader.scala:487)
at com.vesoft.nebula.exchange.reader.CSVReader.read(FileBaseReader.scala:87)
at com.vesoft.nebula.exchange.Exchange$.com$vesoft$nebula$exchange$Exchange$$createDataSource(Exchange.scala:240)
at com.vesoft.nebula.exchange.Exchange$$anonfun$main$2.apply(Exchange.scala:130)
at com.vesoft.nebula.exchange.Exchange$$anonfun$main$2.apply(Exchange.scala:122)
at scala.collection.immutable.List.foreach(List.scala:392)
at com.vesoft.nebula.exchange.Exchange$.main(Exchange.scala:122)
at com.vesoft.nebula.exchange.Exchange.main(Exchange.scala)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:855)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:930)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:939)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.net.UnknownHostException: http
... 44 more
21/07/23 15:55:57 INFO SparkContext: Invoking stop() from shutdown hook
21/07/23 15:55:57 INFO SparkUI: Stopped Spark web UI at http://zprprpr:4040
21/07/23 15:55:57 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
21/07/23 15:55:57 INFO MemoryStore: MemoryStore cleared
21/07/23 15:55:57 INFO BlockManager: BlockManager stopped
21/07/23 15:55:57 INFO BlockManagerMaster: BlockManagerMaster stopped
21/07/23 15:55:57 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
21/07/23 15:55:57 INFO SparkContext: Successfully stopped SparkContext
21/07/23 15:55:57 INFO ShutdownHookManager: Shutdown hook called
21/07/23 15:55:57 INFO ShutdownHookManager: Deleting directory C:\Users\74177\AppData\Local\Temp\spark-8bbfaa91-efd5-400a-bbc8-fcc56932fa65
21/07/23 15:55:57 INFO ShutdownHookManager: Deleting directory C:\Users\74177\AppData\Local\Temp\spark-d96b6559-a7ae-4cac-a4a3-a4fbc0a282ea
感谢回复!望解答
您好 我换了端口 之前那一步可以进行下去了 下面又出现了新的错误
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/C:/Users/74177/spark-2.4.8-bin-hadoop2.6/jars/spark-unsafe_2.11-2.4.8.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
log4j:WARN No appenders could be found for logger (com.vesoft.nebula.exchange.config.Configs$).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
21/07/23 18:32:59 INFO SparkContext: Running Spark version 2.4.8
21/07/23 18:32:59 INFO SparkContext: Submitted application: com.vesoft.nebula.exchange.Exchange
21/07/23 18:32:59 INFO SecurityManager: Changing view acls to: 74177
21/07/23 18:32:59 INFO SecurityManager: Changing modify acls to: 74177
21/07/23 18:32:59 INFO SecurityManager: Changing view acls groups to:
21/07/23 18:32:59 INFO SecurityManager: Changing modify acls groups to:
21/07/23 18:32:59 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(74177); groups with view permissions: Set(); users with modify permissions: Set(74177); groups with modify permissions: Set()
21/07/23 18:33:00 INFO Utils: Successfully started service 'sparkDriver' on port 51628.
21/07/23 18:33:00 INFO SparkEnv: Registering MapOutputTracker
21/07/23 18:33:00 INFO SparkEnv: Registering BlockManagerMaster
21/07/23 18:33:00 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
21/07/23 18:33:00 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
21/07/23 18:33:00 INFO DiskBlockManager: Created local directory at C:\Users\74177\AppData\Local\Temp\blockmgr-749658cc-8488-4d7c-8b97-b68193274477
21/07/23 18:33:00 INFO MemoryStore: MemoryStore started with capacity 434.4 MB
21/07/23 18:33:00 INFO SparkEnv: Registering OutputCommitCoordinator
21/07/23 18:33:00 INFO Utils: Successfully started service 'SparkUI' on port 4040.
21/07/23 18:33:00 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://zprprpr:4040
21/07/23 18:33:00 INFO SparkContext: Added JAR file:/C:/Users/74177/nebula-spark-utils/nebula-exchange/target/nebula-exchange-2.0-20210519.071301-1.jar at spark://zprprpr:51628/jars/nebula-exchange-2.0-20210519.071301-1.jar with timestamp 1627036380562
21/07/23 18:33:00 INFO Executor: Starting executor ID driver on host localhost
21/07/23 18:33:00 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 51651.
21/07/23 18:33:00 INFO NettyBlockTransferService: Server created on zprprpr:51651
21/07/23 18:33:00 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
21/07/23 18:33:00 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, zprprpr, 51651, None)
21/07/23 18:33:00 INFO BlockManagerMasterEndpoint: Registering block manager zprprpr:51651 with 434.4 MB RAM, BlockManagerId(driver, zprprpr, 51651, None)
21/07/23 18:33:00 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, zprprpr, 51651, None)
21/07/23 18:33:00 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, zprprpr, 51651, None)
21/07/23 18:33:00 INFO Exchange$: Processing Tag player
21/07/23 18:33:00 INFO Exchange$: field keys: _c1, _c2
21/07/23 18:33:00 INFO Exchange$: nebula keys: age, name
21/07/23 18:33:00 INFO Exchange$: Loading CSV files from hdfs://localhost:9000/basketballplayer/player.csv
21/07/23 18:33:00 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('file:/C:/Users/74177/spark-2.4.8-bin-hadoop2.6/spark-warehouse').
21/07/23 18:33:00 INFO SharedState: Warehouse path is 'file:/C:/Users/74177/spark-2.4.8-bin-hadoop2.6/spark-warehouse'.
21/07/23 18:33:01 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
21/07/23 18:33:01 INFO InMemoryFileIndex: It took 64 ms to list leaf files for 1 paths.
21/07/23 18:33:01 INFO InMemoryFileIndex: It took 4 ms to list leaf files for 1 paths.
21/07/23 18:33:03 INFO FileSourceStrategy: Pruning directories with:
21/07/23 18:33:03 INFO FileSourceStrategy: Post-Scan Filters: (length(trim(value#0, None)) > 0)
21/07/23 18:33:03 INFO FileSourceStrategy: Output Data Schema: struct<value: string>
21/07/23 18:33:03 INFO FileSourceScanExec: Pushed Filters:
21/07/23 18:33:03 INFO CodeGenerator: Code generated in 203.4034 ms
21/07/23 18:33:03 INFO CodeGenerator: Code generated in 16.5149 ms
21/07/23 18:33:03 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 171.7 KB, free 434.2 MB)
21/07/23 18:33:04 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 21.3 KB, free 434.2 MB)
21/07/23 18:33:04 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on zprprpr:51651 (size: 21.3 KB, free: 434.4 MB)
21/07/23 18:33:04 INFO SparkContext: Created broadcast 0 from csv at FileBaseReader.scala:87
21/07/23 18:33:04 INFO FileSourceScanExec: Planning scan with bin packing, max size: 4194482 bytes, open cost is considered as scanning 4194304 bytes.
21/07/23 18:33:04 INFO SparkContext: Starting job: csv at FileBaseReader.scala:87
21/07/23 18:33:04 INFO DAGScheduler: Got job 0 (csv at FileBaseReader.scala:87) with 1 output partitions
21/07/23 18:33:04 INFO DAGScheduler: Final stage: ResultStage 0 (csv at FileBaseReader.scala:87)
21/07/23 18:33:04 INFO DAGScheduler: Parents of final stage: List()
21/07/23 18:33:04 INFO DAGScheduler: Missing parents: List()
21/07/23 18:33:04 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[3] at csv at FileBaseReader.scala:87), which has no missing parents
21/07/23 18:33:04 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 8.9 KB, free 434.2 MB)
21/07/23 18:33:04 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 4.6 KB, free 434.2 MB)
21/07/23 18:33:04 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on zprprpr:51651 (size: 4.6 KB, free: 434.4 MB)
21/07/23 18:33:04 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1184
21/07/23 18:33:04 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[3] at csv at FileBaseReader.scala:87) (first 15 tasks are for partitions Vector(0))
21/07/23 18:33:04 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
21/07/23 18:33:04 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, ANY, 8265 bytes)
21/07/23 18:33:04 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
21/07/23 18:33:04 INFO Executor: Fetching spark://zprprpr:51628/jars/nebula-exchange-2.0-20210519.071301-1.jar with timestamp 1627036380562
21/07/23 18:33:04 INFO TransportClientFactory: Successfully created connection to zprprpr/172.29.0.1:51628 after 28 ms (0 ms spent in bootstraps)
21/07/23 18:33:04 INFO Utils: Fetching spark://zprprpr:51628/jars/nebula-exchange-2.0-20210519.071301-1.jar to C:\Users\74177\AppData\Local\Temp\spark-8e821d47-bb6d-4330-a55e-b0b80a52674f\userFiles-8092c2fe-924f-4c34-b739-3de45c578701\fetchFileTemp14037982583877635908.tmp
21/07/23 18:33:05 INFO Executor: Adding file:/C:/Users/74177/AppData/Local/Temp/spark-8e821d47-bb6d-4330-a55e-b0b80a52674f/userFiles-8092c2fe-924f-4c34-b739-3de45c578701/nebula-exchange-2.0-20210519.071301-1.jar to class loader
21/07/23 18:33:05 INFO FileScanRDD: Reading File path: hdfs://localhost:9000/basketballplayer/player.csv, range: 0-178, partition values: [empty row]
21/07/23 18:33:05 INFO CodeGenerator: Code generated in 8.0787 ms
21/07/23 18:33:05 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1259 bytes result sent to driver
21/07/23 18:33:05 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 844 ms on localhost (executor driver) (1/1)
21/07/23 18:33:05 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
21/07/23 18:33:05 INFO DAGScheduler: ResultStage 0 (csv at FileBaseReader.scala:87) finished in 0.939 s
21/07/23 18:33:05 INFO DAGScheduler: Job 0 finished: csv at FileBaseReader.scala:87, took 0.988830 s
21/07/23 18:33:05 INFO FileSourceStrategy: Pruning directories with:
21/07/23 18:33:05 INFO FileSourceStrategy: Post-Scan Filters:
21/07/23 18:33:05 INFO FileSourceStrategy: Output Data Schema: struct<value: string>
21/07/23 18:33:05 INFO FileSourceScanExec: Pushed Filters:
21/07/23 18:33:05 INFO CodeGenerator: Code generated in 5.0518 ms
21/07/23 18:33:05 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 171.7 KB, free 434.0 MB)
21/07/23 18:33:05 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 21.3 KB, free 434.0 MB)
21/07/23 18:33:05 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on zprprpr:51651 (size: 21.3 KB, free: 434.4 MB)
21/07/23 18:33:05 INFO SparkContext: Created broadcast 2 from csv at FileBaseReader.scala:87
21/07/23 18:33:05 INFO FileSourceScanExec: Planning scan with bin packing, max size: 4194482 bytes, open cost is considered as scanning 4194304 bytes.
Exception in thread "main" com.facebook.thrift.transport.TTransportException: java.net.SocketTimeoutException: connect timed out
at com.facebook.thrift.transport.TSocket.open(TSocket.java:175)
at com.vesoft.nebula.client.meta.MetaClient.getClient(MetaClient.java:103)
at com.vesoft.nebula.client.meta.MetaClient.doConnect(MetaClient.java:98)
at com.vesoft.nebula.client.meta.MetaClient.connect(MetaClient.java:88)
at com.vesoft.nebula.exchange.MetaProvider.<init>(MetaProvider.scala:32)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.process(VerticesProcessor.scala:109)
at com.vesoft.nebula.exchange.Exchange$$anonfun$main$2.apply(Exchange.scala:145)
at com.vesoft.nebula.exchange.Exchange$$anonfun$main$2.apply(Exchange.scala:122)
at scala.collection.immutable.List.foreach(List.scala:392)
at com.vesoft.nebula.exchange.Exchange$.main(Exchange.scala:122)
at com.vesoft.nebula.exchange.Exchange.main(Exchange.scala)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:855)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:930)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:939)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.net.SocketTimeoutException: connect timed out
at java.base/java.net.PlainSocketImpl.waitForConnect(Native Method)
at java.base/java.net.PlainSocketImpl.socketConnect(PlainSocketImpl.java:107)
at java.base/java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:399)
at java.base/java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:242)
at java.base/java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:224)
at java.base/java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.base/java.net.Socket.connect(Socket.java:608)
at com.facebook.thrift.transport.TSocket.open(TSocket.java:170)
... 22 more
21/07/23 18:33:06 INFO SparkContext: Invoking stop() from shutdown hook
21/07/23 18:33:06 INFO SparkUI: Stopped Spark web UI at http://zprprpr:4040
21/07/23 18:33:06 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
21/07/23 18:33:06 INFO MemoryStore: MemoryStore cleared
21/07/23 18:33:06 INFO BlockManager: BlockManager stopped
21/07/23 18:33:06 INFO BlockManagerMaster: BlockManagerMaster stopped
21/07/23 18:33:06 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
21/07/23 18:33:06 WARN SparkEnv: Exception while deleting Spark temp dir: C:\Users\74177\AppData\Local\Temp\spark-8e821d47-bb6d-4330-a55e-b0b80a52674f\userFiles-8092c2fe-924f-4c34-b739-3de45c578701
java.io.IOException: Failed to delete: C:\Users\74177\AppData\Local\Temp\spark-8e821d47-bb6d-4330-a55e-b0b80a52674f\userFiles-8092c2fe-924f-4c34-b739-3de45c578701\nebula-exchange-2.0-20210519.071301-1.jar
at org.apache.spark.network.util.JavaUtils.deleteRecursivelyUsingJavaIO(JavaUtils.java:144)
at org.apache.spark.network.util.JavaUtils.deleteRecursively(JavaUtils.java:118)
at org.apache.spark.network.util.JavaUtils.deleteRecursivelyUsingJavaIO(JavaUtils.java:128)
at org.apache.spark.network.util.JavaUtils.deleteRecursively(JavaUtils.java:118)
at org.apache.spark.network.util.JavaUtils.deleteRecursively(JavaUtils.java:91)
at org.apache.spark.util.Utils$.deleteRecursively(Utils.scala:1062)
at org.apache.spark.SparkEnv.stop(SparkEnv.scala:103)
at org.apache.spark.SparkContext$$anonfun$stop$11.apply$mcV$sp(SparkContext.scala:1974)
at org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:1340)
at org.apache.spark.SparkContext.stop(SparkContext.scala:1973)
at org.apache.spark.SparkContext$$anonfun$2.apply$mcV$sp(SparkContext.scala:575)
at org.apache.spark.util.SparkShutdownHook.run(ShutdownHookManager.scala:214)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply$mcV$sp(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:188)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1945)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply$mcV$sp(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:188)
at scala.util.Try$.apply(Try.scala:192)
at org.apache.spark.util.SparkShutdownHookManager.runAll(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anon$2.run(ShutdownHookManager.scala:178)
at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:54)
21/07/23 18:33:06 INFO SparkContext: Successfully stopped SparkContext
21/07/23 18:33:06 INFO ShutdownHookManager: Shutdown hook called
21/07/23 18:33:06 INFO ShutdownHookManager: Deleting directory C:\Users\74177\AppData\Local\Temp\spark-8e821d47-bb6d-4330-a55e-b0b80a52674f\userFiles-8092c2fe-924f-4c34-b739-3de45c578701
21/07/23 18:33:06 ERROR ShutdownHookManager: Exception while deleting Spark temp dir: C:\Users\74177\AppData\Local\Temp\spark-8e821d47-bb6d-4330-a55e-b0b80a52674f\userFiles-8092c2fe-924f-4c34-b739-3de45c578701
java.io.IOException: Failed to delete: C:\Users\74177\AppData\Local\Temp\spark-8e821d47-bb6d-4330-a55e-b0b80a52674f\userFiles-8092c2fe-924f-4c34-b739-3de45c578701\nebula-exchange-2.0-20210519.071301-1.jar
at org.apache.spark.network.util.JavaUtils.deleteRecursivelyUsingJavaIO(JavaUtils.java:144)
at org.apache.spark.network.util.JavaUtils.deleteRecursively(JavaUtils.java:118)
at org.apache.spark.network.util.JavaUtils.deleteRecursivelyUsingJavaIO(JavaUtils.java:128)
at org.apache.spark.network.util.JavaUtils.deleteRecursively(JavaUtils.java:118)
at org.apache.spark.network.util.JavaUtils.deleteRecursively(JavaUtils.java:91)
at org.apache.spark.util.Utils$.deleteRecursively(Utils.scala:1062)
at org.apache.spark.util.ShutdownHookManager$$anonfun$1$$anonfun$apply$mcV$sp$3.apply(ShutdownHookManager.scala:65)
at org.apache.spark.util.ShutdownHookManager$$anonfun$1$$anonfun$apply$mcV$sp$3.apply(ShutdownHookManager.scala:62)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at org.apache.spark.util.ShutdownHookManager$$anonfun$1.apply$mcV$sp(ShutdownHookManager.scala:62)
at org.apache.spark.util.SparkShutdownHook.run(ShutdownHookManager.scala:214)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply$mcV$sp(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:188)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1945)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply$mcV$sp(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:188)
at scala.util.Try$.apply(Try.scala:192)
at org.apache.spark.util.SparkShutdownHookManager.runAll(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anon$2.run(ShutdownHookManager.scala:178)
at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:54)
21/07/23 18:33:06 INFO ShutdownHookManager: Deleting directory C:\Users\74177\AppData\Local\Temp\spark-28f1a119-5485-4eb4-9d70-b2469a51c31f
21/07/23 18:33:06 INFO ShutdownHookManager: Deleting directory C:\Users\74177\AppData\Local\Temp\spark-8e821d47-bb6d-4330-a55e-b0b80a52674f
21/07/23 18:33:06 ERROR ShutdownHookManager: Exception while deleting Spark temp dir: C:\Users\74177\AppData\Local\Temp\spark-8e821d47-bb6d-4330-a55e-b0b80a52674f
java.io.IOException: Failed to delete: C:\Users\74177\AppData\Local\Temp\spark-8e821d47-bb6d-4330-a55e-b0b80a52674f\userFiles-8092c2fe-924f-4c34-b739-3de45c578701\nebula-exchange-2.0-20210519.071301-1.jar
at org.apache.spark.network.util.JavaUtils.deleteRecursivelyUsingJavaIO(JavaUtils.java:144)
at org.apache.spark.network.util.JavaUtils.deleteRecursively(JavaUtils.java:118)
at org.apache.spark.network.util.JavaUtils.deleteRecursivelyUsingJavaIO(JavaUtils.java:128)
at org.apache.spark.network.util.JavaUtils.deleteRecursively(JavaUtils.java:118)
at org.apache.spark.network.util.JavaUtils.deleteRecursivelyUsingJavaIO(JavaUtils.java:128)
at org.apache.spark.network.util.JavaUtils.deleteRecursively(JavaUtils.java:118)
at org.apache.spark.network.util.JavaUtils.deleteRecursively(JavaUtils.java:91)
at org.apache.spark.util.Utils$.deleteRecursively(Utils.scala:1062)
at org.apache.spark.util.ShutdownHookManager$$anonfun$1$$anonfun$apply$mcV$sp$3.apply(ShutdownHookManager.scala:65)
at org.apache.spark.util.ShutdownHookManager$$anonfun$1$$anonfun$apply$mcV$sp$3.apply(ShutdownHookManager.scala:62)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at org.apache.spark.util.ShutdownHookManager$$anonfun$1.apply$mcV$sp(ShutdownHookManager.scala:62)
at org.apache.spark.util.SparkShutdownHook.run(ShutdownHookManager.scala:214)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply$mcV$sp(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:188)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1945)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply$mcV$sp(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:188)
at scala.util.Try$.apply(Try.scala:192)
at org.apache.spark.util.SparkShutdownHookManager.runAll(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anon$2.run(ShutdownHookManager.scala:178)
at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:54)
Exception in thread “main” com.facebook.thrift.transport.TTransportException: java.net.SocketTimeoutException: connect timed out
目前看起来第一步报错是这里 这个是什么原因呢? 看别的帖子也没提到过这个问题
看错误是 meta 连不上了,看一下服务是否正常
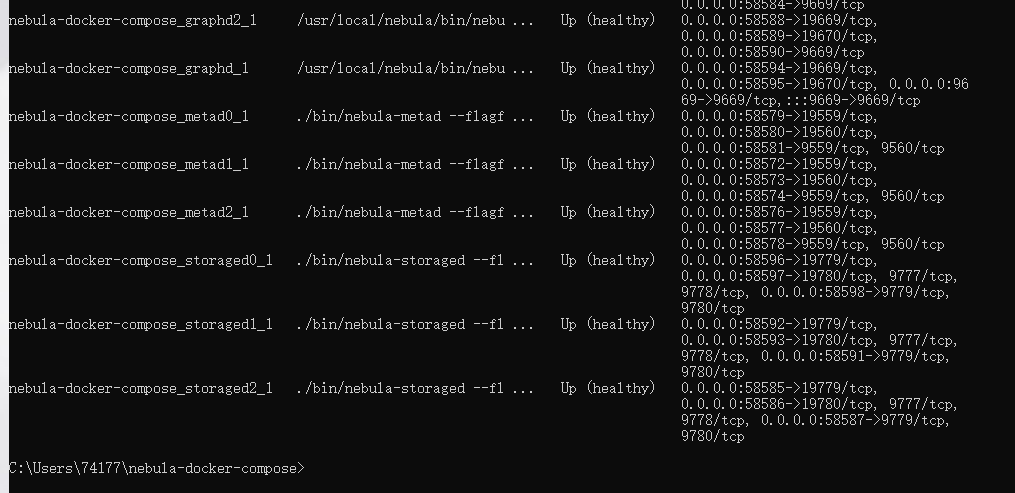
端口写错了,你是docker compose部署的,要用映射出来的端口号
那我应该用哪个呢 是58581? 还是58574?

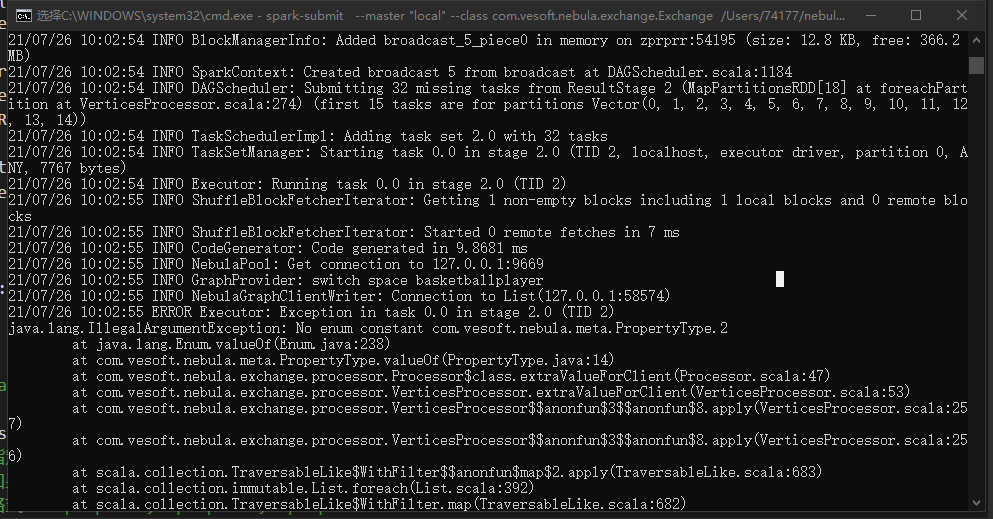
你确认你的nebula版本是2.0.1么, 你这个是版本不匹配
exchange用的是Index of /repositories/snapshots/com/vesoft/nebula-exchange 1这个链接的snapshot版本
nebula是用的2.0.1的呀 用docker部署的 查到git版本号是761f22b
我用https://docs.nebula-graph.com.cn/2.0.1/2.quick-start/2.deploy-nebula-graph-with-docker-compose/这个链接下的方法更新过镜像了 应该是没问题的