问题描述:
我在使用nebula-spark-connector进行数据加载,进行图计算,对api的使用有一些小问题
版本:2.0.1
开发语言版本:jdk-1.8
在官网上看到有两种写法
写法一:
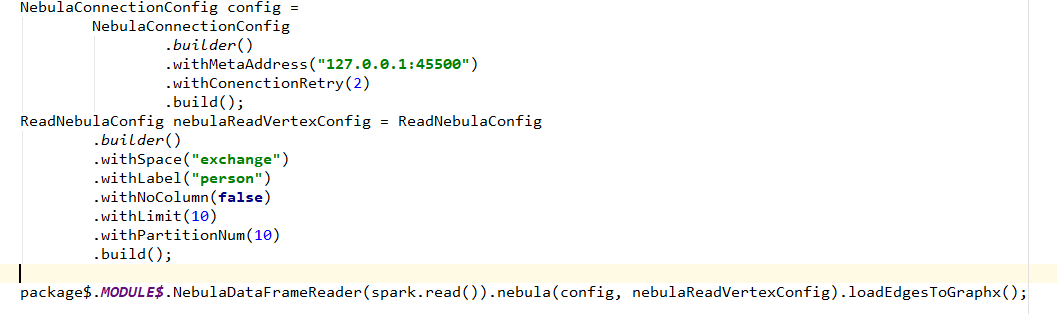
val vertex = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToGraphx()
val edgeRDD = spark.read.nebula(config, nebulaReadEdgeConfig).loadEdgesToGraphx()
val graph = Graph(vertexRDD, edgeRDD)
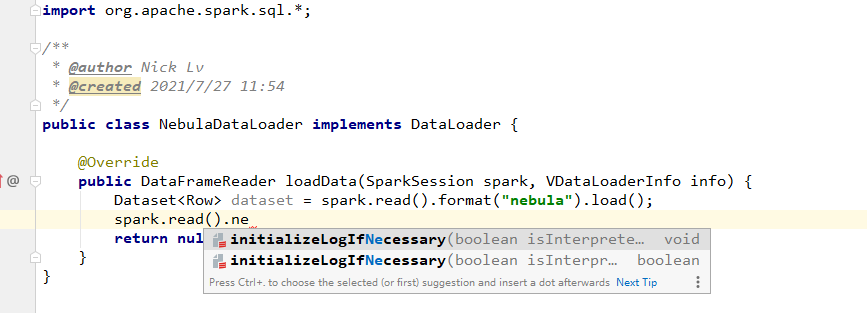
问题描述:这个spark.read.nebula,这里的read是sparksql的api,但是read的后面并没有nebula的选项,请问这个写法是如何写出来的?
相关链接:nebula-spark-utils/nebula-spark-connector/README_CN.md at v2.0.0 · vesoft-inc/nebula-spark-utils · GitHub
截图如下:

写法二:
var anotherDataset = spark.read
.format(“nebula”)
.option(Parameters.TYPE, Type.EDGE.getType)
.option(Parameters.HOST_AND_PORTS, hostPorts)
.option(Parameters.PARTITION_NUMBER, partitionNumber)
.option(Parameters.SPACE_NAME, nameSpace)
.option(Parameters.LABEL, edge)
.option(Parameters.RETURN_COLS, labelAndWeight(edge))
.load()
这种写法如何使用loadVerticesToGraphx()和loadEdgesToGraphx()这个api
相关链接:nebula-java/tools/nebula-algorithm/src/main/scala/com/vesoft/nebula/tools/algorithm/utils/NebulaUtil.scala at v1.0 · vesoft-inc/nebula-java · GitHub