大佬好, 帮忙看下这是什么原因呢?
操作步骤:
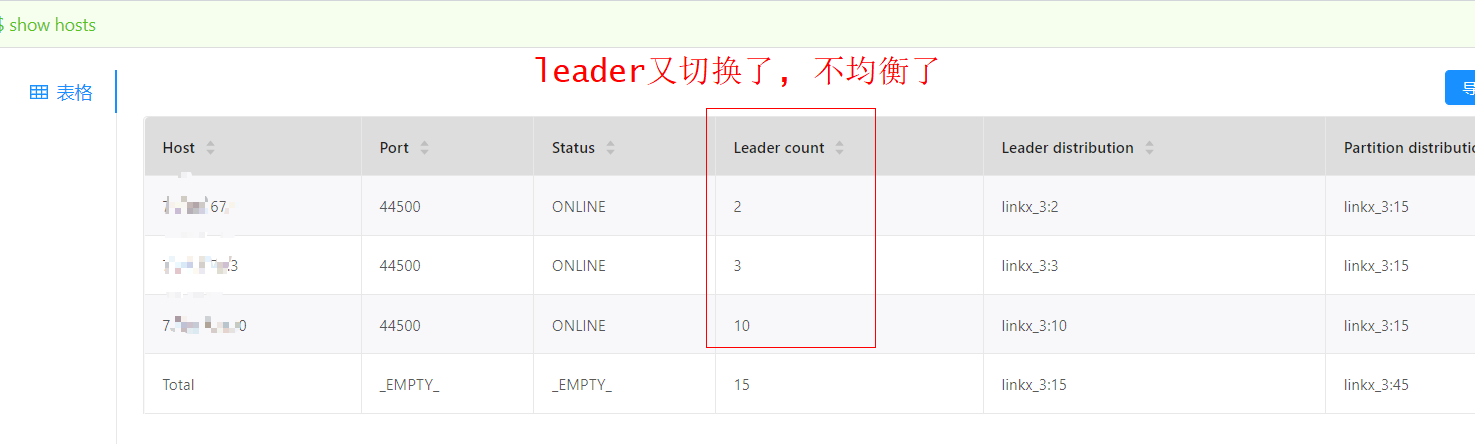
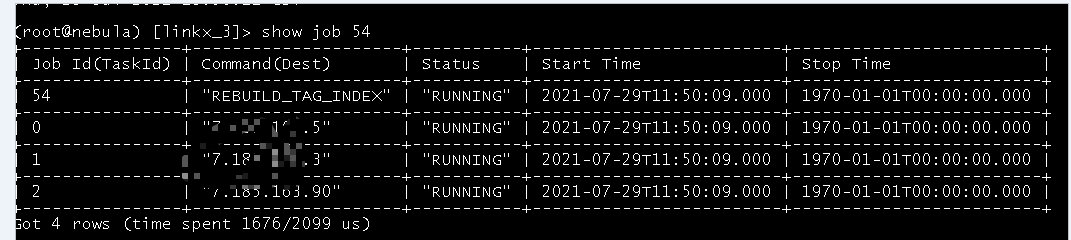
- 新建索引给13亿的tag, 不久后失败, 并伴随着leader切换, 过程中还有节点offline,
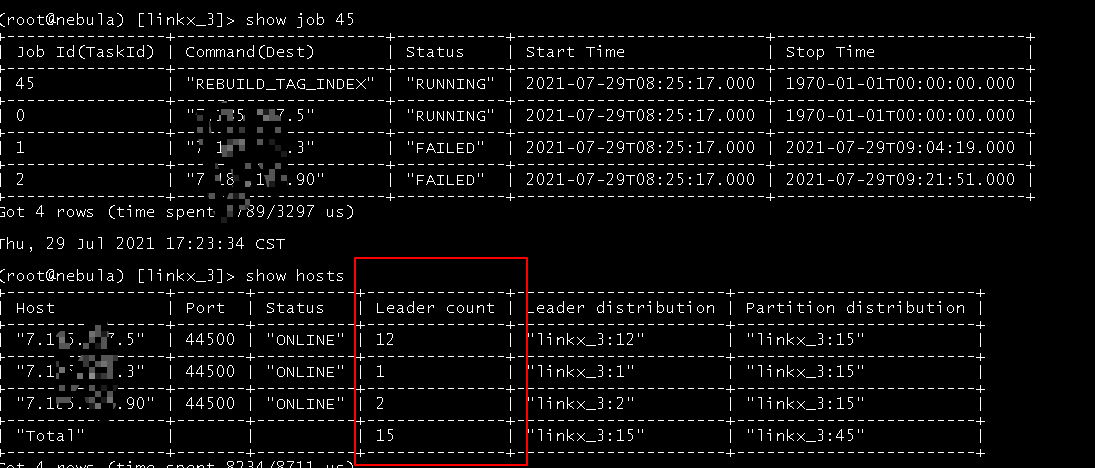
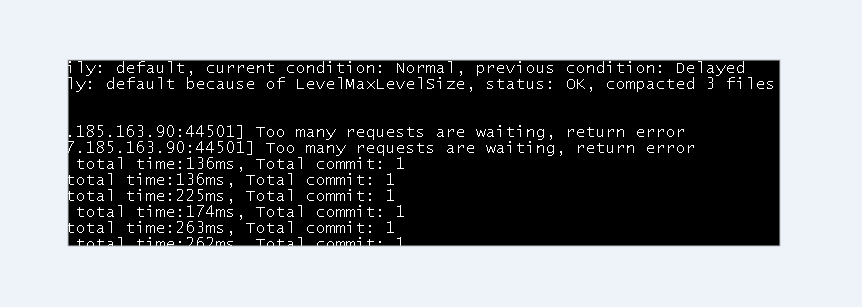
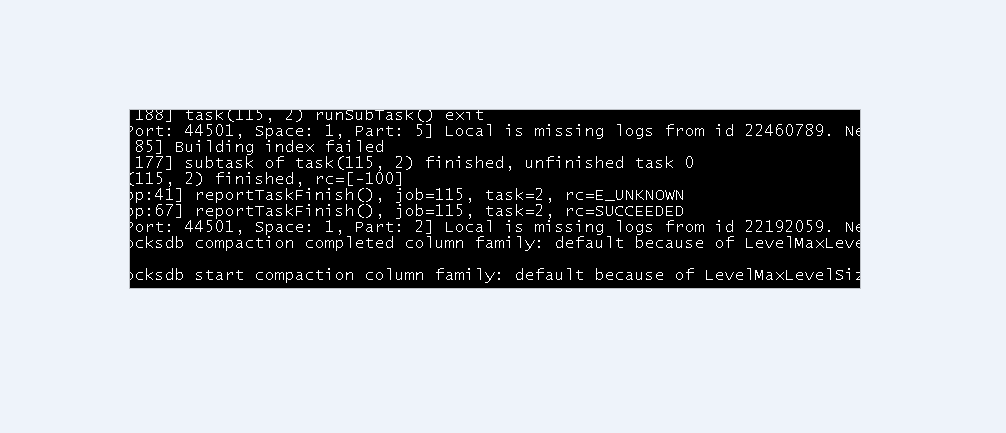
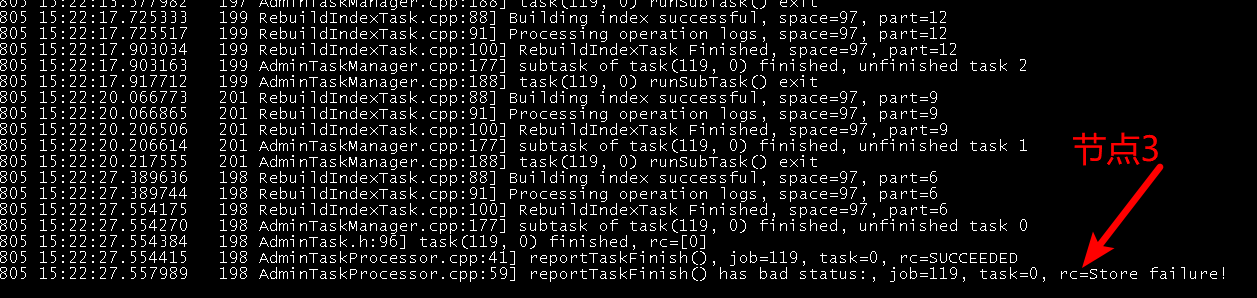
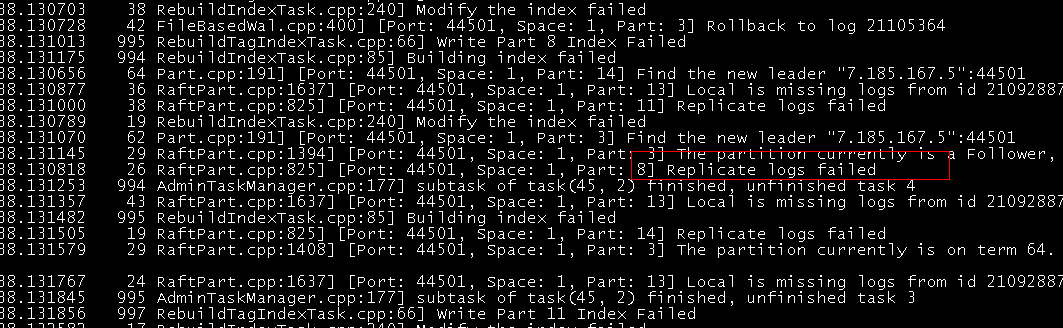
日志中有这个打印

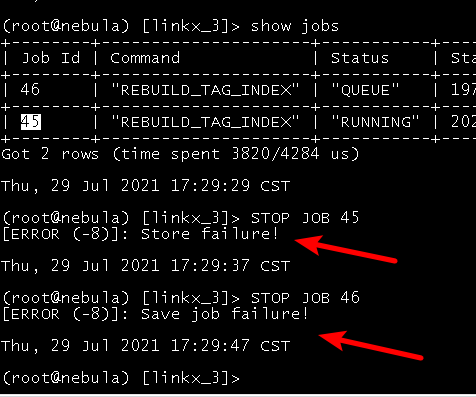
- 想把失败的job和右面queue的job想通过命令stop了, 但是发现执行stop…失败, 但是任务又停了
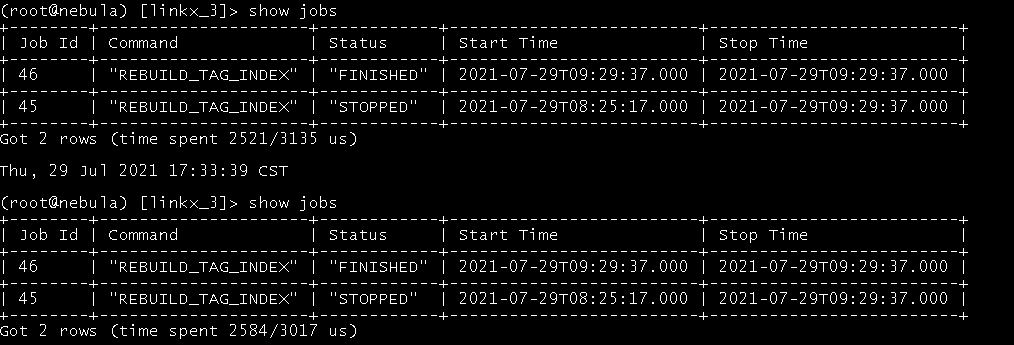
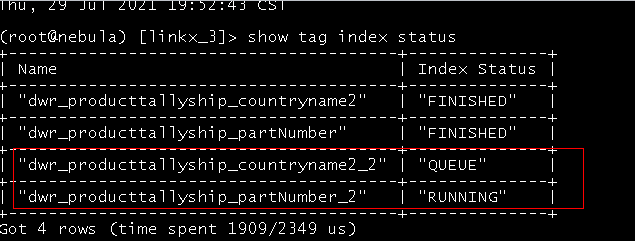
- 想drop失败的索引后重新建立索引, 但是发现是秒Finalished(其实没有成功, 试了好多次都不行)

4, 重新启动集群, 换了个索引名字重新建立, 发现在running了
大佬好, 帮忙看下这是什么原因呢?
操作步骤:
日志中有这个打印
4, 重新启动集群, 换了个索引名字重新建立, 发现在running了
heartbeat_interval_secs是多少?create index后,确保sleep这个时间后再rebuild。另外,建议balance leader一下,让leader分布均衡后再rebuild。
秒成功是个bug吧
就是因为meta数据还没同步到storage,storage空跑了一遍。
对应时段的网络和IO贴 一下?
为什么还有个compaction啊
自动compact是开着的
自动compact 可能会因为rebuild的随机读触发,导致更严重的IO争抢
你监控看看是不是IO不够了。是的话,要不就是compact停下
--local_config=true
########## basics ##########
# Whether to run as a daemon process
--daemonize=true
# The file to host the process id
--pid_file=pids/nebula-storaged.pid
########## logging ##########
# The directory to host logging files, which must already exists
--log_dir=logs
# Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=0
# Verbose log level, 1, 2, 3, 4, the higher of the level, the more verbose of the logging
--v=0
# Maximum seconds to buffer the log messages
--logbufsecs=0
# Whether to redirect stdout and stderr to separate output files
--redirect_stdout=true
# Destination filename of stdout and stderr, which will also reside in log_dir.
--stdout_log_file=storaged-stdout.log
--stderr_log_file=storaged-stderr.log
# Copy log messages at or above this level to stderr in addition to logfiles. The numbers of severity levels INFO, WARNING, ERROR, and FATAL are 0, 1, 2, and 3, respectively.
--stderrthreshold=2
########## networking ##########
# Comma separated Meta server addresses
--meta_server_addrs=127.0.0.1:9559
# Local IP used to identify the nebula-storaged process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=127.0.0.1
# Storage daemon listening port
--port=9779
# HTTP service ip
--ws_ip=0.0.0.0
# HTTP service port
--ws_http_port=19779
# HTTP2 service port
--ws_h2_port=19780
# heartbeat with meta service
--heartbeat_interval_secs=240
######### Raft #########
# Raft election timeout
--raft_heartbeat_interval_secs=30
# RPC timeout for raft client (ms)
--raft_rpc_timeout_ms=500
## recycle Raft WAL
--wal_ttl=7201
########## Disk ##########
# Root data path. Split by comma. e.g. --data_path=/disk1/path1/,/disk2/path2/
# One path per Rocksdb instance.
--data_path=data/storage
# The default reserved bytes for one batch operation
--rocksdb_batch_size=8192
# The default block cache size used in BlockBasedTable.
# The unit is MB.
--rocksdb_block_cache=8
# The type of storage engine, `rocksdb', `memory', etc.
--engine_type=rocksdb
# Compression algorithm, options: no,snappy,lz4,lz4hc,zlib,bzip2,zstd
# For the sake of binary compatibility, the default value is snappy.
# Recommend to use:
# * lz4 to gain more CPU performance, with the same compression ratio with snappy
# * zstd to occupy less disk space
# * lz4hc for the read-heavy write-light scenario
--rocksdb_compression=lz4
# Set different compressions for different levels
# For example, if --rocksdb_compression is snappy,
# "no:no:lz4:lz4::zstd" is identical to "no:no:lz4:lz4:snappy:zstd:snappy"
# In order to disable compression for level 0/1, set it to "no:no"
--rocksdb_compression_per_level=
# Whether or not to enable rocksdb's statistics, disabled by default
--enable_rocksdb_statistics=false
# Statslevel used by rocksdb to collection statistics, optional values are
# * kExceptHistogramOrTimers, disable timer stats, and skip histogram stats
# * kExceptTimers, Skip timer stats
# * kExceptDetailedTimers, Collect all stats except time inside mutex lock AND time spent on compression.
# * kExceptTimeForMutex, Collect all stats except the counters requiring to get time inside the mutex lock.
# * kAll, Collect all stats
--rocksdb_stats_level=kExceptHistogramOrTimers
# Whether or not to enable rocksdb's prefix bloom filter, disabled by default.
--enable_rocksdb_prefix_filtering=false
# Whether or not to enable the whole key filtering.
--enable_rocksdb_whole_key_filtering=true
# The prefix length for each key to use as the filter value.
# can be 12 bytes(PartitionId + VertexID), or 16 bytes(PartitionId + VertexID + TagID/EdgeType).
--rocksdb_filtering_prefix_length=12
############## rocksdb Options ##############
# rocksdb DBOptions in json, each name and value of option is a string, given as "option_name":"option_value" separated by comma
#--rocksdb_db_options={}
# rocksdb ColumnFamilyOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
#--rocksdb_column_family_options={"write_buffer_size":"67108864","max_write_buffer_number":"4","max_bytes_for_level_base":"268435456"}
# rocksdb BlockBasedTableOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_block_based_table_options={"block_size":"8192"}
--rocksdb_column_family_options={"level0_slowdown_writes_trigger":"100","level0_stop_writes_trigger":"100","disable_auto_compactions":"true","max_bytes_for_level_base":"536870912","max_write_buffer_number":"10","write_buffer_size":"134217728","min_write_buffer_number_to_merge":"4","level0_file_num_compaction_trigger":"4","target_file_size_base":"134217728","target_file_size_multiplier":"1"}
--rocksdb_db_options={"max_subcompactions":"32","max_background_jobs":"64","max_open_files":"100000000","max_background_flushes":"32"}
--rebuild_index_batch_num=128
--max_concurrent_subtasks=5
--enable_partitioned_index_filter=true
我在自己环境试了下,rebuild index时候的压力还是挺大的,rebuild_index_batch_num这个参数几乎起不到限流作用,现阶段会先通过sleep来限流。
你觉得小了?
如果rebuild出错,会打印这个log,然后retry,5次retry的限制。log上来看,有一次出错了,再retry后成功了。
raft_heartbeat_interval_secs 这个也改成240
–enable_rocksdb_prefix_filtering=false 改成true 这个需要观察下内存够不够,你们700GB应该够的
@xiaochen@yangmeng
这个bug,你知道的。。。