match p = (a)-[e]-(b) where id(a)==“b95af6bc70efbd16fa601fd124929e79f44404df” return p
我需要边的数据,关联点的数据,也需要统计count所有条数,所以用match写,拿到数据后再根据点和边进行分类,很方便,但是查询太慢了,实在是太慢了,该如何优化。
用go from再加上fetch prop 真的能快很多吗?
点2.3亿,边2.8亿。
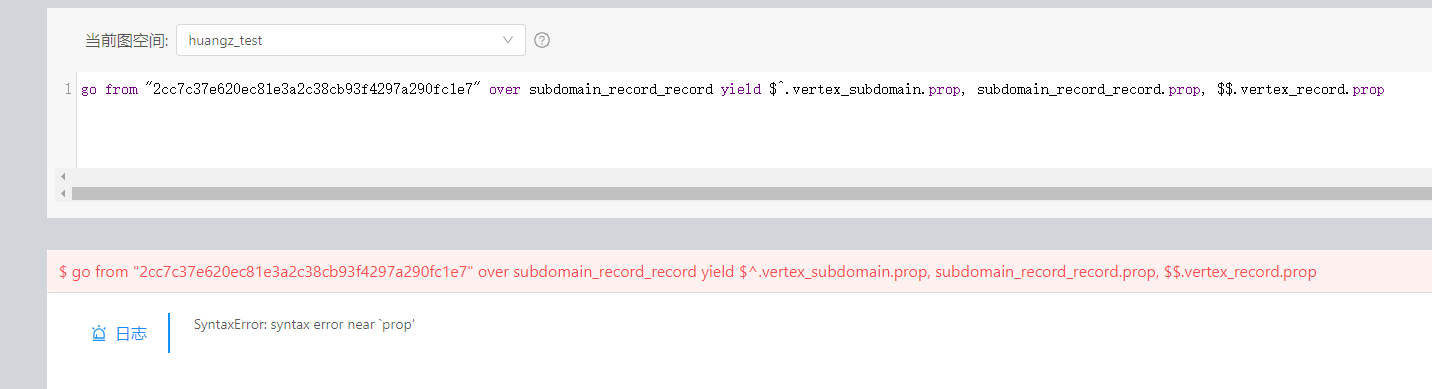
go from “2cc7c37e620ec81e3a2c38cb93f4297a290fc1e7” over subdomain_record_record yield $^.vertex_subdomain.prop, subdomain_record_record.prop, $$.vertex_record.prop
怎么写来着?