现在查询是单线程的,如果用户输入了一个复杂的查询逻辑会导致后面的其他查询一起卡死,那有地方可以设置查询服务的线程数和设置最大查询响应时间之类的,或者部署集群多副本之类的可以解决这个问题吗
1 个赞
The number of threads to execute user queries, 0 for # of CPU cores
–num_worker_threads=0
num_worker_threads 参数设置执行线程数。
我这设置是默认的0,应该是把所有cpu核数用满的才对,但之前测试查询的时候还是卡死了,后续的简单查询命令无法执行,等前面那个复杂的结果出来后,才执行成功。。。这个多线程是并行还是并发的?感觉更像并发
graphd 是可以部署多副本的,client 端需要做个简单的 load balance。
graphd 中的任务都是异步的,会同时放在线程池中并行的执行。你说的前面的任务会阻塞后续任务,可以看下 server 上运行复杂查询时的 cpu 负债情况和磁盘的 IO,再来确定是哪里的瓶颈。
1 个赞
恩,多副本这个我知道的,之前部署过集群。
刚刚复现了一下问题,查了一个三度的find all path,然后这条查询命令卡了几分钟之后,报错[ERROR (-8)]: OK Get neighbors failed, 期间其余任何语句都无法查询,主要是storaged服务一直在占用资源,在查询服务报错失败之后,依旧无法查询,卡在那里。
下图返回查询失败时间是17:51分,系统资源截图和其他查询卡主截图都是在那之后的。

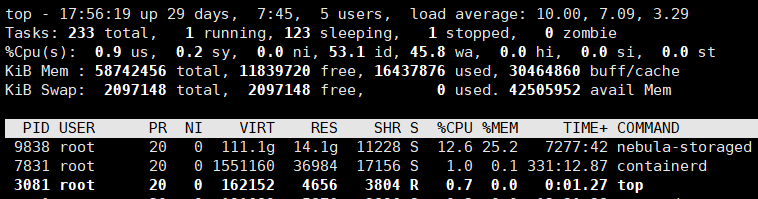
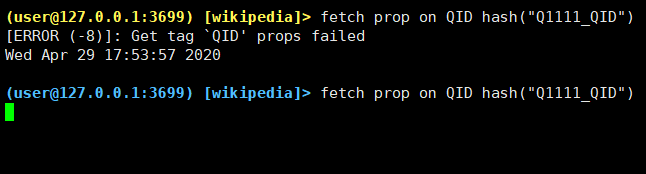
有没有可能是客户端超时了? Storage还在运行。
客户端是超时了,但是python接口那设置过超长的等待时间,所以最后可以跑出结果的。但问题是,这个超时了,也不会停,还在那占用性能,导致其它查询无法运行。。。
您是希望我们提供客户端的执行接口可以设置超时时间,而不是整体的超时时间是吗?
假如是这样的需求,可能我们没办法提供。但是假如是解决这个sql由于执行时间太长(有可能你是查询了好几度,而且数据量很大,服务端需要比较长时间处理),但是你希望超过一定时间之后客户端按超时处理掉,不想让它占用线程,那你可以把client整体的超时时间设置成你们系统认为可接受最长超时时间。