提问参考模版:
- nebula 版本:2.5.0
- 部署方式(单机 ):
- 是否为线上版本:Y
请教一下nebula算法的调用,参考文档上显示
通过nebula-spark-connector读取到的数据默认是
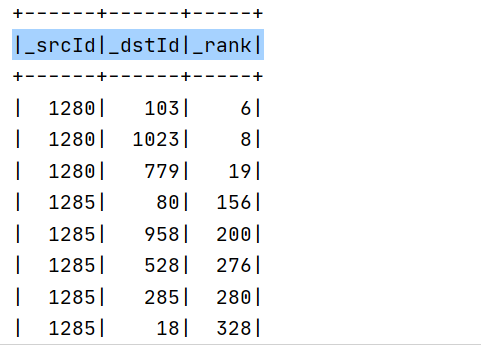
请问可以直接将该数据用到算法计算吗,这里的rank必须是INTEGER,且是否和上图第三行不是rank的说法冲突呢。如果想通过spark-connector想定制化读取进行算法计算的数据有可行的办法吗
提问参考模版:
尝试了一下用这三行数据是有算法输出的,但是这样的话如果使得权重只能是边默认的rank了,如何设置到自己想要的double类型的权重呢?
nebula自带的Rank可以作为权重的,文档的说明是指: 算法可以指定边的权重,但边权重不一定非要是Nebula的_rank.
你用的是提供的一个工具包,使用算法我们建议采用API调用的形式,通过Spark-connector进行数据读取,这样你可以做更灵活的配置,想读取什么数据自己指定就好。
您好,谢谢您的解答。对于rank我明白了,导入数据的时候可以把权重处理成integer作为整形导入。我目前就是使用spark-connector的读取数据且进行api调用,还有有以下几个疑问呢
1:如果数据量很大的话,spark-connector的读取速度是否够快
2:另外如图所示的一些参数具体是什么意思有相关说明吗
图算法多数是迭代计算的,maxIter是指最多迭代几次结束计算过程。
false表示当前图是hasWeight的值, 你进入到apply函数就能看到参数定义呀
好的 感谢!
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。

