某个点 查询一步的关系 就有将近10万数据 ,查询三步 直接将数据库搞挂 ,有没有好的方法 只取部分数据 类似mysql的limit?
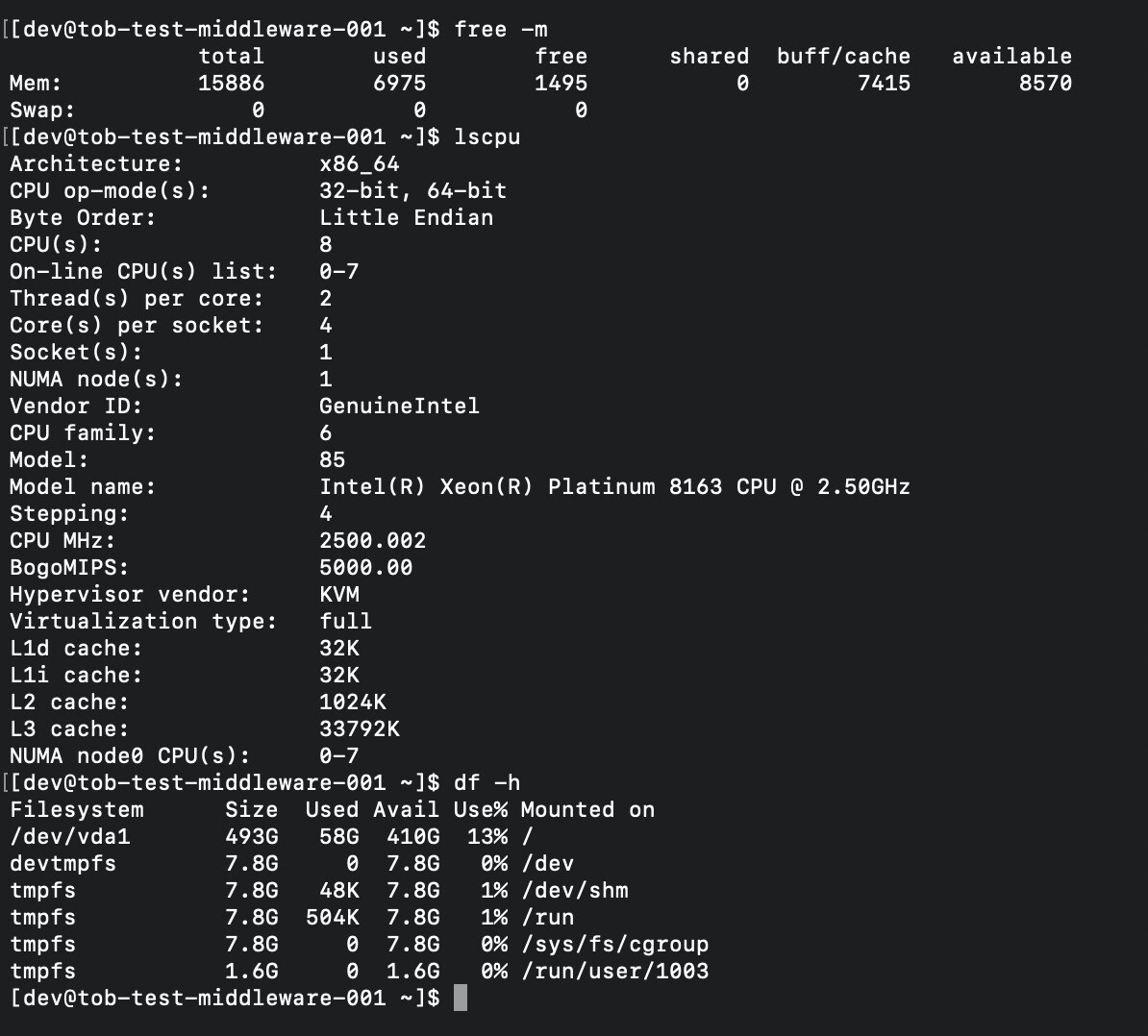
把你的机器配置也贴一下,磁盘类型,磁盘大小,CPU 核数和内存大小
cat /sys/block/*/queue/rotational
–
看下磁盘类型
1 个赞
nGQL 支持 limit,但还没做下推优化,所以目前只能配置一下 max_edge_returned_per_vertex 来缓解超级节点的情况。
查询应该还没有达到默认的60s,图数据库直接挂掉 连不上了
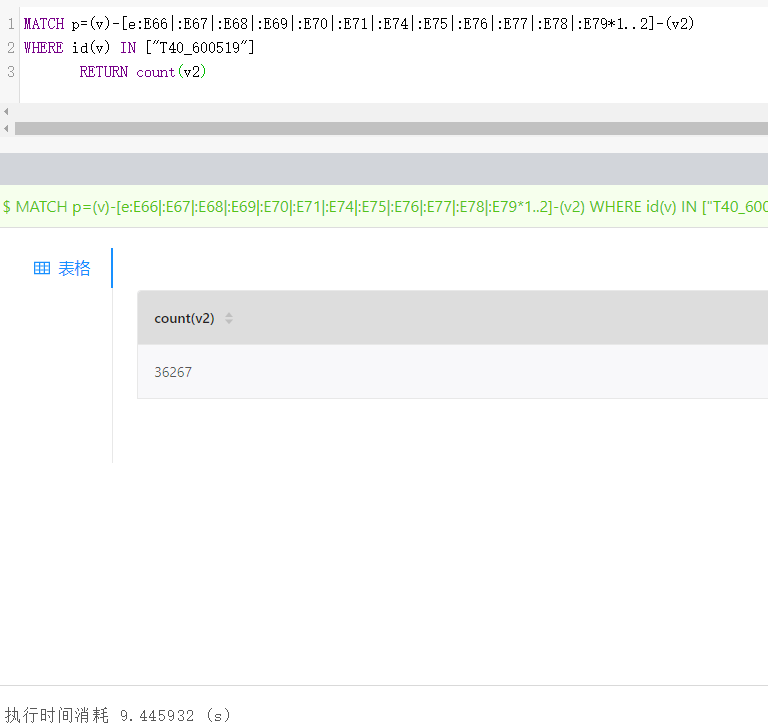
嗯,oom 了。试一下上面那个配置
老师 像这种情况 怎么避免?生产上可以查询耗时,但是一定要避免数据库挂掉
2.5版本有一个新功能做Graphd的内存水位控制,看一下 Release Note - Nebula Graph Database 手册
参数:system_memory_high_watermark_ratio
1 个赞
老师 ,目前已经升级了2.5.0版本

同样查询三步 studio直接断开连接了 必须重启图数据库 才能连接;
system_memory_high_watermark_ratio 这个属性需要手动设置吗?

这个参数默认是0.8的,你这个情况 1)看看是graph还是storage挂掉?2)贴下相应的log。
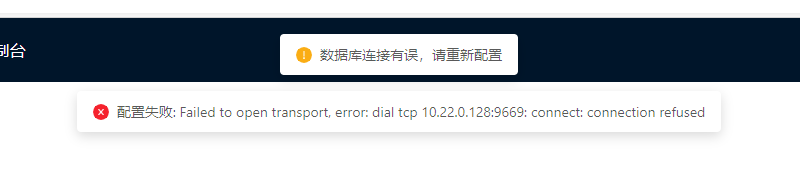

日志你就看最新的,nebula-graphd.INFO和nebula-storaged.INFO
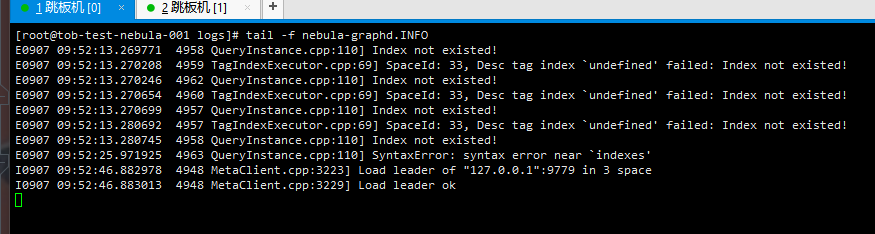

crash的话看看nebula/bin下有没有core dump文件?
另外log目录下stderr那些都没有内容吗?INFO的日志详细程度还可以通过v来配置的。