-
nebula 版本:(2.5.0)
-
部署方式(分布式):
-
是否为线上版本:Y
-
硬件信息
- 磁盘( 推荐使用 SSD)
-
相关的 meta / storage / graph info 日志信息(尽量使用文本形式方便检索)
yaml文件内容如下:
# 连接的Nebula Graph版本,连接2.x时设置为v2。
version: v2
description: import_user_device_rel_0628
# 是否删除临时生成的日志和错误数据文件。
removeTempFiles: false
clientSettings:
# nGQL语句执行失败的重试次数。
retry: 1
# Nebula Graph客户端并发数。设置为 CPU 核数
concurrency: 24
# 每个Nebula Graph客户端的缓存队列大小。
channelBufferSize: 2560
# 指定数据要导入的Nebula Graph图空间。
space: user_sim_0628
# 连接信息。
connection:
user: root
password: nebula
address: 10.185.10.113:9669
postStart:
# 配置连接Nebula Graph服务器之后,在插入数据之前执行的一些操作。
commands: |
DROP SPACE IF EXISTS user_sim_0628;
CREATE SPACE IF NOT EXISTS user_sim_0628(partition_num=15, replica_factor=1, vid_type=FIXED_STRING(32)) ";
USE user_sim_0628;
CREATE TAG user();
CREATE TAG mcn();
CREATE TAG blk_user(flag int);
CREATE TAG wt_user(flag int);
CREATE TAG grey_user(flag int);
CREATE EDGE sim(deviceList string,sim_cos_dacay1 float,sim_jac_dacay1 float,sim_jac float,user_device_node_cnt int,user_device_cnt_start int,user_device_cnt_end int);
# 执行上述命令后到执行插入数据命令之间的间隔。
afterPeriod: 15s
preStop:
# 配置断开Nebula Graph服务器连接之前执行的一些操作。
commands: |
# 错误等日志信息输出的文件路径。
logPath: ./err/test3output.log
# 1.CSV文件相关设置。
files:
# 数据文件的存放路径,如果使用相对路径,则会将路径和当前配置文件的目录拼接。本示例第一个数据文件为点的数据。
- path: ./data/data_user_mcn0_blk0_wt0.csv
# 插入失败的数据文件存放路径,以便后面补写数据。
failDataPath: ./err/data_user_mcn0_blk0_wt0_err.csv
# 单批次插入数据的语句数量。
batchSize: 1000
# 读取数据的行数限制。
#limit: 1000
# 是否按顺序在文件中插入数据行。如果为false,可以避免数据倾斜导致的导入速率降低。
inOrder: false
# 文件类型,当前仅支持csv。
type: csv
csv:
# 是否有表头。
withHeader: true
# 是否有LABEL。
withLabel: false
# 指定csv文件的分隔符。只支持一个字符的字符串分隔符。
delimiter: ","
schema:
type: vertex
vertex:
tags:
- name: user
# 2.CSV文件相关设置。
# 数据文件的存放路径,如果使用相对路径,则会将路径和当前配置文件的目录拼接。本示例第一个数据文件为点的数据。
- path: ./data/data_user_mcn0_blk0_wt1.csv
# 插入失败的数据文件存放路径,以便后面补写数据。
failDataPath: ./err/data_user_mcn0_blk0_wt1_err.csv
# 单批次插入数据的语句数量。
batchSize: 1000
# 读取数据的行数限制。
#limit: 1000
# 是否按顺序在文件中插入数据行。如果为false,可以避免数据倾斜导致的导入速率降低。
inOrder: false
# 文件类型,当前仅支持csv。
type: csv
csv:
# 是否有表头。
withHeader: true
# 是否有LABEL。
withLabel: false
# 指定csv文件的分隔符。只支持一个字符的字符串分隔符。
delimiter: ","
schema:
type: vertex
vertex:
tags:
- name: user
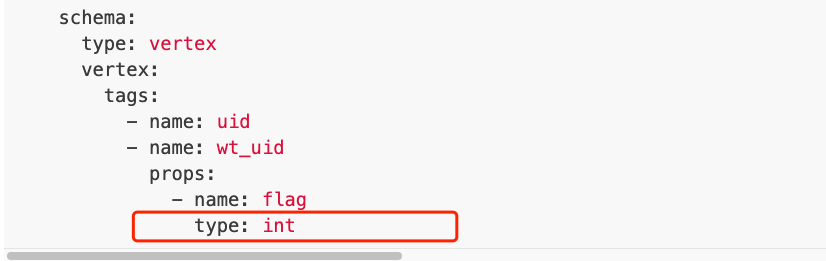
- name: wt_user
props:
- name: flag
type: int
上面代码中,如果不加最后一行
type: int
import时日志为:
2021/09/15 16:35:37 — START OF NEBULA IMPORTER —
2021/09/15 16:35:37 [INFO] config.go:380: find file: /data1/idata/user_device_rel/data/data_user_mcn0_blk0_wt0.csv
2021/09/15 16:35:37 [INFO] config.go:380: find file: /data1/idata/user_device_rel/data/data_user_mcn0_blk0_wt1.csv
2021/09/15 16:35:38 — END OF NEBULA IMPORTER —
如果加了最后一行,就能正常导入。
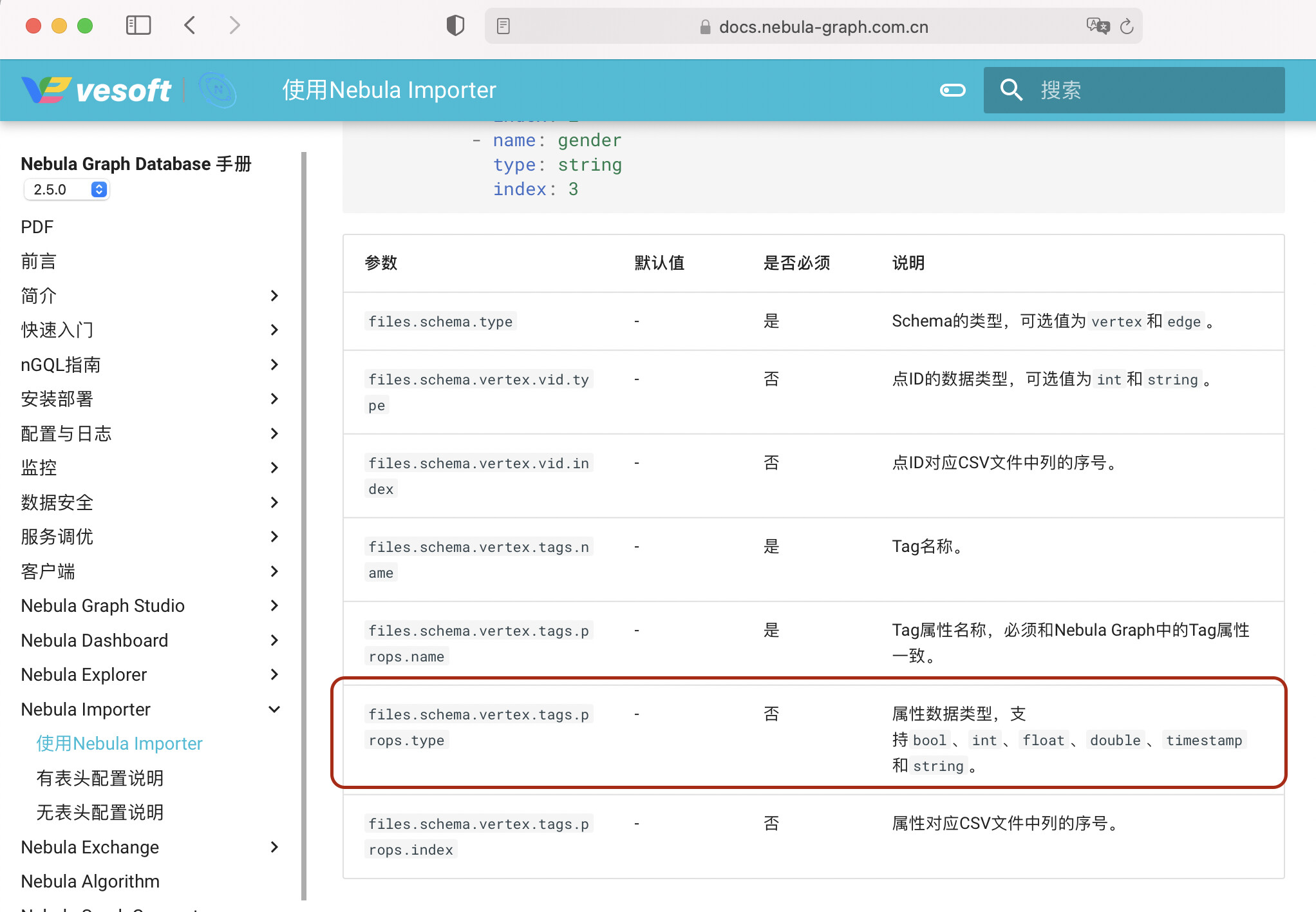
可是,files.schema.vertex.tags.props.type这个参数不是不必须的吗?
 你仔细看看模版里的东西,试着去理解、接受下它,你大概就明白它的为啥是现在这样了。
你仔细看看模版里的东西,试着去理解、接受下它,你大概就明白它的为啥是现在这样了。