- nebula 版本:2.0.1
- 部署方式:分布式
- 是否为线上版本:Y
- 硬件信息
- 磁盘( 推荐使用 SSD):机械硬盘
- CPU、内存信息
问题:exchange入库速度很慢,1千万点数据,入库接近半小时。
入库工具官方提供的:nebula-exchange-2.0.1.jar
https://repo1.maven.org/maven2/com/vesoft/nebula-exchange/2.0.1/
入库配置文件:
{
# Spark相关配置
spark: {
app: {
name: Nebula Exchange 2.0
}
driver: {
cores: 1
maxResultSize: 1G
}
cores {
max: 16
}
}
# Nebula Graph相关配置
nebula: {
address:{
# 以下为Nebula Graph的Graph服务和所有Meta服务所在机器的IP地址及端口。
# 如果有多个地址,格式为 "ip1:port","ip2:port","ip3:port"。
# 不同地址之间以英文逗号 (,) 隔开。
graph:["x.x.x.39:9669", "x.x.x.40:9669", "x.x.x.41:9669"]
meta:["x.x.x.39:9559", "x.x.x.40:9559", "x.x.x.41:9559"]
}
# 填写的账号必须拥有Nebula Graph相应图空间的写数据权限。
user: importer
pswd: 密码脱敏
# 填写Nebula Graph中需要写入数据的图空间名称。
space: evil_phone_info
connection {
timeout: 30000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
# hive 的目录 错误日志位置
output:/user/huhe001/programFormal/graphdata/exchange_errs/btsvoice-exchange
}
rate: {
limit: 1024
timeout: 10000
}
}
# 处理点
tags: [
# 设置标签相关信息。
{
# Nebula Graph中对应的标签名称。
name: btsvoice
type: {
# 指定数据源文件格式,设置为hive。
source: hive
# 指定如何将点数据导入Nebula Graph:Client或SST。
sink: client
}
# 设置读取数据库表数据的SQL语句
exec: "select bts_id_key, bts_id, bts_prov_name_own, bts_area_name_own, lac, ci, longitude, latitude, black_num, grey_num from graph.BLACK_DWA_D_USE_VOICE_BASE_ENTITY_NEW where month_id='202108' and day_id='31' and bts_id!='' and length(bts_id_key)<=32 and length(bts_id_key)>=5"
# 在fields里指定表中的列名称,其对应的value会作为Nebula Graph中指定属性。
# fields和nebula.fields里的配置必须一一对应。
# 如果需要指定多个列名称,用英文逗号(,)隔开。
fields: [bts_id, bts_prov_name_own, bts_area_name_own, lac, ci, longitude, latitude, black_num, grey_num]
nebula.fields: [bts_id, bts_prov_name_own, bts_area_name_own, lac, ci, longitude, latitude, black_num, grey_num]
# 指定表中某一列数据为Nebula Graph中点VID的来源。
# vertex.field的值必须与上述fields中的列名保持一致。
vertex:{
field: bts_id_key
}
# 单批次写入 Nebula Graph 的最大点数据量。
batch: 256
# Spark 分区数量
partition: 32
}
]
}
目标写如点:btsvoice
数据量:10472013
写入前数据情况:
(root@nebula) [evil_phone_info]> show stats;
+---------+-------------------+-----------+
| Type | Name | Count |
+---------+-------------------+-----------+
| "Tag" | "btsflux" | 1691519 |
+---------+-------------------+-----------+
| "Tag" | "btsvoice" | 0 |
+---------+-------------------+-----------+
| "Tag" | "cert" | 16163553 |
+---------+-------------------+-----------+
| "Tag" | "channel" | 335434 |
+---------+-------------------+-----------+
| "Tag" | "developer" | 665771 |
+---------+-------------------+-----------+
| "Tag" | "imei" | 29697911 |
+---------+-------------------+-----------+
| "Tag" | "model" | 15 |
+---------+-------------------+-----------+
| "Tag" | "phone" | 61016402 |
+---------+-------------------+-----------+
| "Tag" | "product" | 17617 |
+---------+-------------------+-----------+
| "Tag" | "prov" | 31 |
+---------+-------------------+-----------+
| "Edge" | "phone2btsflux" | 0 |
+---------+-------------------+-----------+
| "Edge" | "phone2btsvoice" | 0 |
+---------+-------------------+-----------+
| "Edge" | "phone2cert" | 118890454 |
+---------+-------------------+-----------+
| "Edge" | "phone2channel" | 18875935 |
+---------+-------------------+-----------+
| "Edge" | "phone2developer" | 118890454 |
+---------+-------------------+-----------+
| "Edge" | "phone2imei" | 30957882 |
+---------+-------------------+-----------+
| "Edge" | "phone2model" | 1386916 |
+---------+-------------------+-----------+
| "Edge" | "phone2phone" | 396365465 |
+---------+-------------------+-----------+
| "Edge" | "phone2prov" | 61016473 |
+---------+-------------------+-----------+
| "Space" | "vertices" | 120060202 |
+---------+-------------------+-----------+
| "Space" | "edges" | 746383579 |
+---------+-------------------+-----------+
Got 21 rows (time spent 1484/2147 us)
phone上面带有索引
入库监控图:
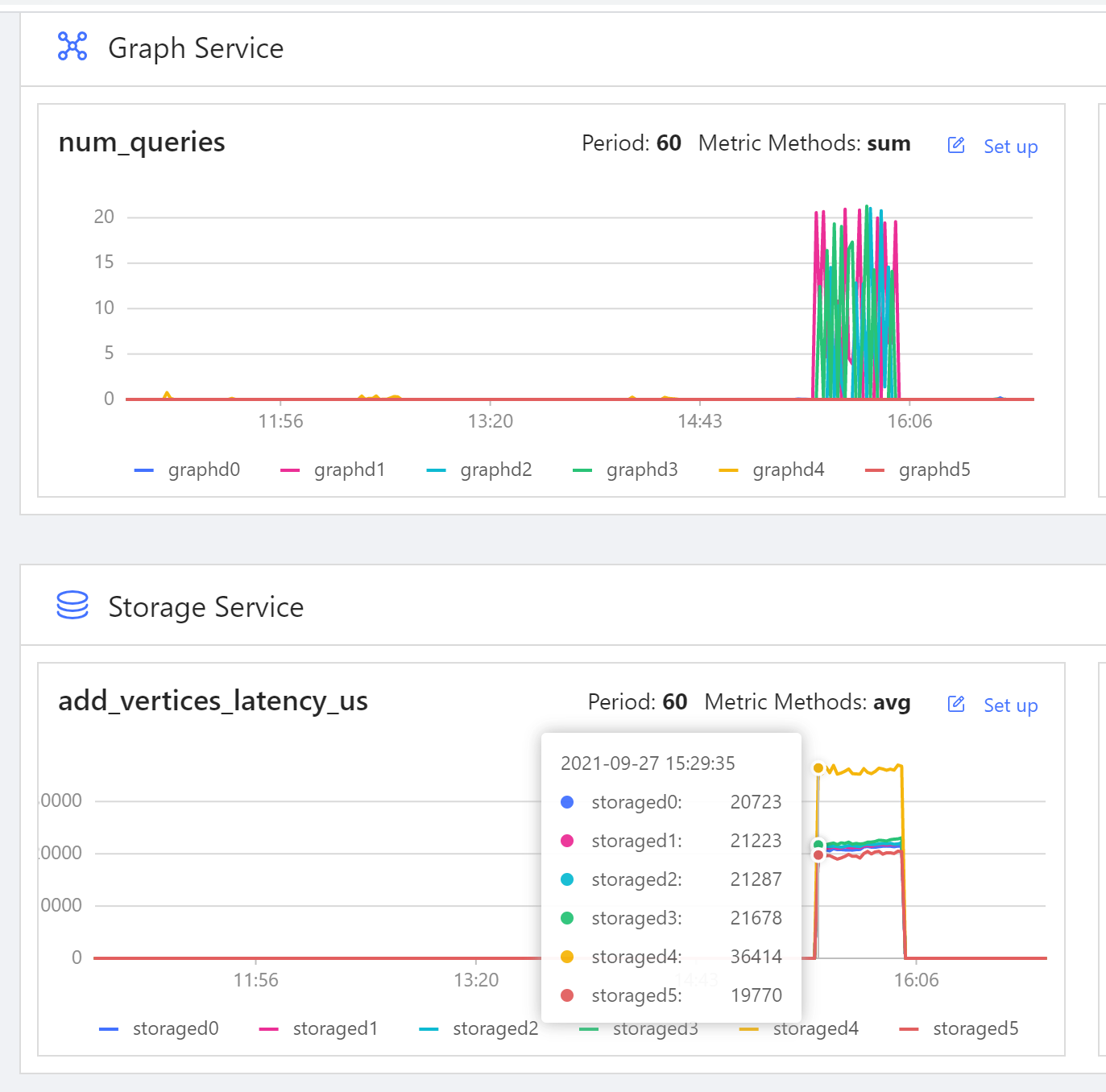
1、入库时带有大量的查询正常吗。
2、图上显示入库时storage速度是每秒多少。