nebula 2.5 全文索引执行太慢,是因为没有配置什么参数吗?2.0上一般花费几十毫秒但是在2.5上画了好几秒钟。
LOOKUP ON TagSentence WHERE WILDCARD(TagSentence.Content,"*make*" ,30)
explain format="dot" LOOKUP ON TagSentence WHERE
digraph exec_plan {
rankdir=BT;
"Project_3"[label="{Project_3|outputVar: \[\{\"colNames\":\[\"VertexID\"\],\"type\":\"DATASET\",\"name\":\"__Project_3\"\}\]|inputVar: __Filter_2}", shape=Mrecord];
"Filter_2"->"Project_3";
"Filter_2"[label="{Filter_2|outputVar: \[\{\"colNames\":\[\"VertexID\",\"TagSentence.Content\"\],\"type\":\"DATASET\",\"name\":\"__Filter_2\"\}\]|inputVar: __TagIndexFullScan_1}", shape=Mrecord];
"TagIndexFullScan_4"->"Filter_2";
"TagIndexFullScan_4"[label="{TagIndexFullScan_4|outputVar: \[\{\"colNames\":\[\"VertexID\",\"TagSentence.Content\"\],\"type\":\"DATASET\",\"name\":\"__TagIndexFullScan_1\"\}\]|inputVar: }", shape=Mrecord];
"Start_0"->"TagIndexFullScan_4";
"Start_0"[label="{Start_0|outputVar: \[\{\"colNames\":\[\],\"type\":\"DATASET\",\"name\":\"__Start_0\"\}\]|inputVar: }", shape=Mrecord];
}
WILDCARD(TagSentence.Content,"*make*" ,30)
profile format="dot" LOOKUP ON TagSentence WHERE WILDCARD(TagSentence.Content,"*make*" ,30)
| id | name | dependencies | profiling data | operator
| 3 | Project | 2 | ver: 0, rows: 32, execTime: 166us, totalTime: 168us | outputVar: [
| 2 | Filter | 4 | ver: 0, rows: 32, execTime: 316163us, totalTime: 316170us | outputVar: [
| 4 | TagIndexFullScan | 0 | ver: 0, rows: 41841, execTime: 0us, totalTime: 3480478us | outputVar: [
| 0 | Start | | ver: 0, rows: 0, execTime: 0us, totalTime: 83us | outputVar: [
上面是explain的结果和profile的结果。
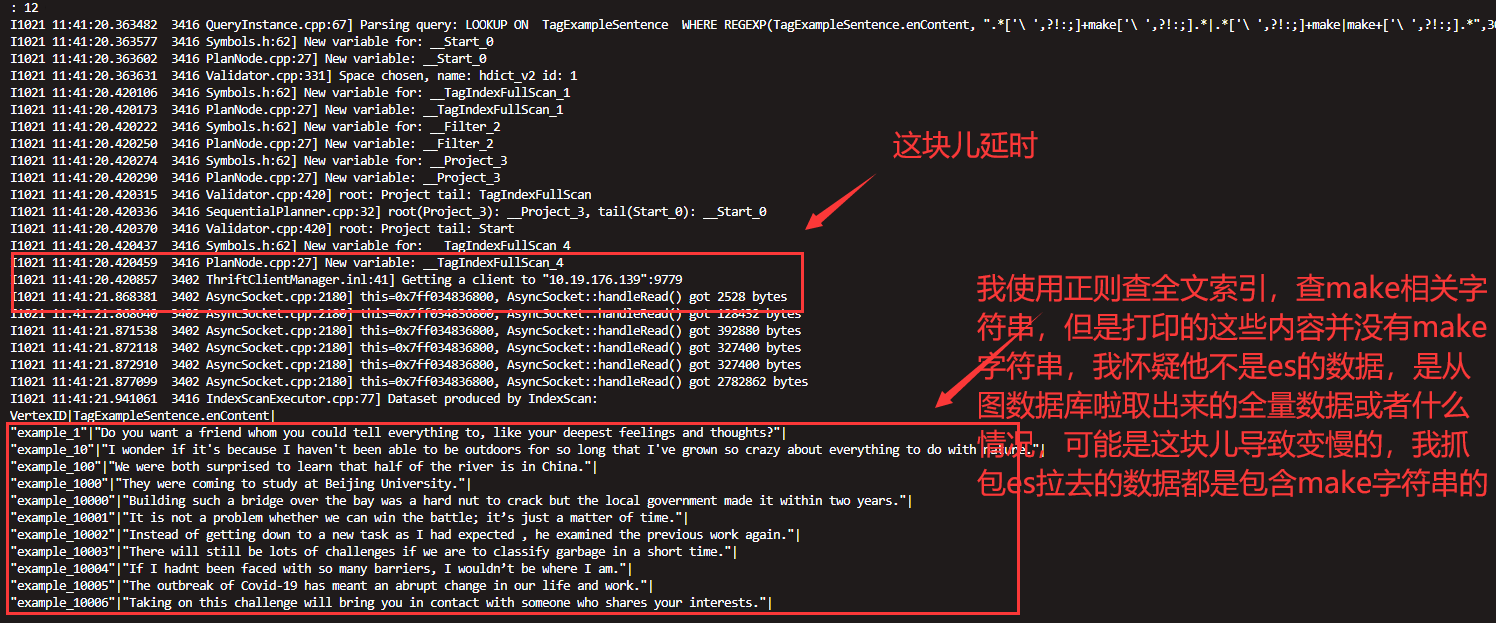
看起来大量时间花费在了filter上。还没细研究filter的机制,之前看过graph的日志,es查询请求默认200ms很快返回的。
看这块儿有一个异步拉取数据的逻辑发生。