
(刘灿,
报社主编,
,
,
,
,
山木,
刘灿,笔名山木。山东新泰人。中共党员。1970年入伍。,
,
,
,
,
,
60.42,
false,
baike.baidu.com,
刘灿(报社主编)_百度百科,
Person,
,
,
{“baike.baidu.com”:“3662838”},
)
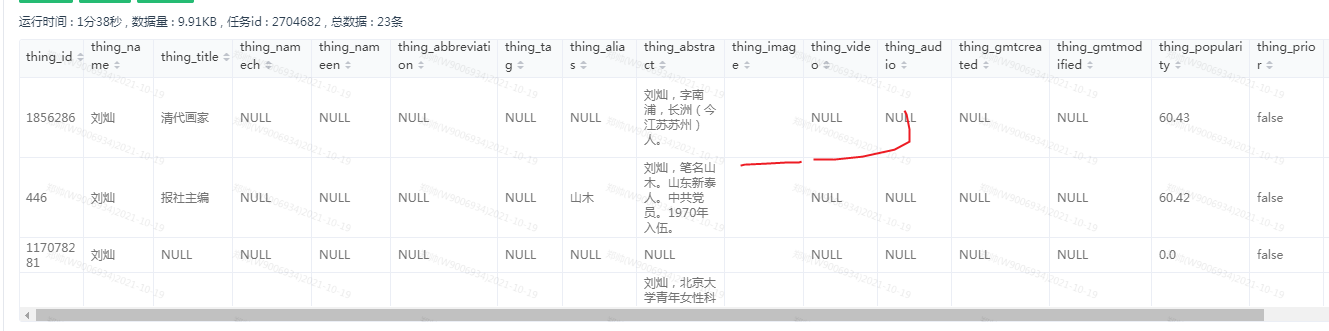
这话数据没有长度很长的字段,string 默认是多大啊??
string 没有长度限制, fixed_string 才有长度限制。
ps:你为啥要额外设一个default值为null? 你不设 默认值也是_NULL_
这个你们1.0和2.0返回数据不统一,我们这边业务查询要求兼容统一才都设置为null 的,
你们的2.0 返回_NULL_ 多了前后的下划线,不统一我们也没办法
Wrong strNum: 13 这个报错是什么原因??是数据为空解析失败吗??
这个问题和数据为空应该没关系,你配置文件中只配置了这两个属性, 数据中这两个属性的值分别是多少?
我配置全部字段 报 Wrong strNum: 13
exec: “select thing_id, thing_name, thing_title, thing_namech, thing_nameen, thing_abbreviation, thing_tag, thing_alias, thing_abstract, thing_image, thing_video, thing_audio, thing_gmtcreated, thing_gmtmodified, thing_popularity, thing_prior, thing_datasource, thing_urls, thing_class, thing_imagejson, thing_embedding, thing_sourceids, thing_videocover from oppo_kg_dw.dwd_kg_release_spo_thing_df_v3_4_ht_v6 where ds = ‘20211011’ limit 300”
fields: [thing_name, thing_title, thing_namech, thing_nameen, thing_abbreviation, thing_tag, thing_alias, thing_abstract, thing_image, thing_video, thing_audio, thing_gmtcreated, thing_gmtmodified, thing_popularity, thing_prior, thing_datasource, thing_urls, thing_class, thing_imagejson, thing_embedding, thing_sourceids, thing_videocover]
nebula.fields: [Thing_name, Thing_title, Thing_nameCh, Thing_nameEn, Thing_abbreviation, Thing_tag, Thing_alias, Thing_abstract, Thing_image, Thing_video, Thing_audio, Thing_gmtCreated, Thing_gmtModified, Thing_popularity, Thing_prior, Thing_dataSource, Thing_urls, Thing_class, Thing_imageJson, Thing_embedding, Thing_sourceIds, Thing_videoCover]
vertex: {field:thing_id}
就这条数据
(刘灿,
报社主编,
,
,
,
,
山木,
刘灿,笔名山木。山东新泰人。中共党员。1970年入伍。,
,
,
,
,
,
60.42,
false,
baike.baidu.com,
刘灿(报社主编)_百度百科,
Person,
,
,
{“baike.baidu.com”:“3662838”},
)
这应该是个bug, 你全部的数据里面是否有存在值为null的数据?
参考这个pr:Bugfix/encoder row writer by MMyheart · Pull Request #366 · vesoft-inc/nebula-java · GitHub
这个问题那边可以提交到 client master 分支吗,我看master 还没有改
client上 fix的pr还没有合,等合入后你可以用snapshot版本的Exchange。
恩,不过等不及了。我自己改了自己打包了,谢啦
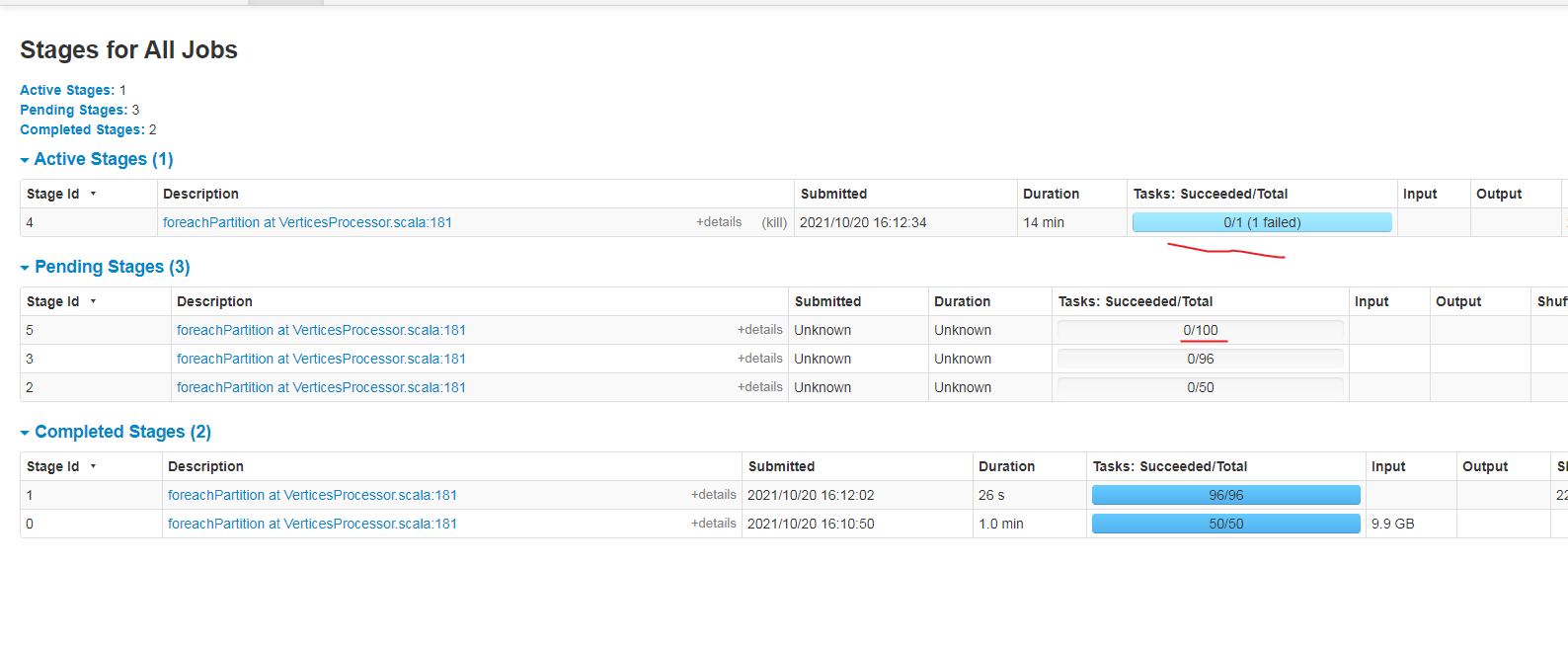
再问一下,这个sst 生成文件是一个一个tag 生成数据吗,还是多个tag 同时并行,现在多个tag跑spark 直接卡主不动了
现在测试sst 发现是先写文件到sprak 临时目录,在上传hdfs ,这边数据一多spark 临时磁盘就不足了,导致sst 生成失败,这个可以直接向hdfs 写sst 吗,一定要先生成sst 文件在上传吗
是一个tag一个tag进行处理的,每个tag内部是并发处理的
因为要向同一个文件多次写数据,所以不能直接写hdfs。 你可以修改下配置文件中的local path,不用临时磁盘
现在还有一个问题,一个tag 数据为1亿数据,现在跑者就卡主了,我看任务是task 就只有一个。没有多个任务task 跑,我加了重新分区也不行
(Encoders.tuple(Encoders.BINARY, Encoders.BINARY))
.toDF(“key”, “value”).repartition(100) //这我加的重新分区,也不行
.sortWithinPartitions(“key”) //这个算子代码一直卡这里执行好久 ,
.foreachPartition { iterator: Iterator[Row] =>
val taskID = TaskContext.get().taskAttemptId()
var writer: NebulaSSTWriter = null
var currentPart = -1
val localPath = fileBaseConfig.localPath
val remotePath = fileBaseConfig.remotePath
try {
iterator.foreach { vertex =>
val key = vertex.getAs[Array[Byte]](0)
val value = vertex.getAs[Array[Byte]](1)
var part = ByteBuffer
.wrap(key, 0, 4)
.order(ByteOrder.nativeOrder)
.getInt >> 8
if (part <= 0) {
part = part + partitionNum
}
你提交任务 分配了多少个executor, 代码里不用再加一下repartition,因为在读取hive数据之后会根据配置文件中配的partition数进行repatition的。
我设置了多个executor ,但是就是没起作用,才加上repartion 的现在加了数据多了还是不行奇怪,帮忙看看
${SPARK_HOME}/bin/spark-submit
–queue root.ipd.daily
–name “nebula-import-sst”
–master yarn
–driver-cores 16
–driver-memory 48g
–executor-memory 48g
–deploy-mode cluster
–num-executors 48
–executor-cores 16
–conf spark.port.maxRetries=1
–conf spark.yarn.maxAppAttempts=1
–conf spark.executor.memoryOverhead=8g
–conf spark.driver.memoryOverhead=8g
–conf spark.hadoop.fs.defaultFS="$ALG_HDFS"
–conf spark.default.parallelism=48
–conf spark.executor.extraJavaOptions="-XX:MaxDirectMemorySize=7372m"
–files “$conf”
–class com.vesoft.nebula.exchange.Exchange
lib/nebula-exchange-2.5-SNAPSHOT.jar -c $conf -h -d
.sortWithinPartitions(“key”) //这个算子代码一直卡这里执行好久 , 这个方法好像用不到分区,有点奇怪数据多了就不行,数据少一点就不卡